行人重识别(ReID)基础知识入门
1、ReID技术概述
1.1 基本原理
ReID,全称Re-identification,目的是利用各种智能算法在图像数据库中找到与要搜索的目标相似的对象。ReID是图像检索的一个子任务,本质上是图像检索而不是图像分类。给定一个监控行人图像,检索跨设备下的该行人图像。
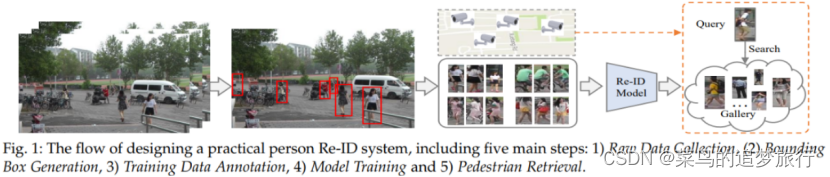
行人重识别(Person re-identification)主要目的是针对出现在监控摄像头内的某个目标行人,准确快速地从监控网络其他摄像头内的大量行人中将这个目标行人标识出来。如图所示一个区域有多个摄像头拍摄视频序列,ReID的要求对一个摄像头下感兴趣的行人,检索到该行人在其他摄像头下出现的所有图片。

人脸识别目前相对来说准确率是非常高的,但在这些场景中人脸识别可能会失效,不再适用,尤其是远距离监控,就算是拍到人脸,可能也是一张模糊的人脸,ReID看的是一个人的整体特征,包括衣着、配饰、体态等等一些特征,就好像是用我们自己的眼睛看一样。
行人重识别技术可以弥补目前固定摄像头的视觉局限,并可与行人检测、行人跟踪技术相结合。工程上,最简单的行人重识别的技术流程如下所示。

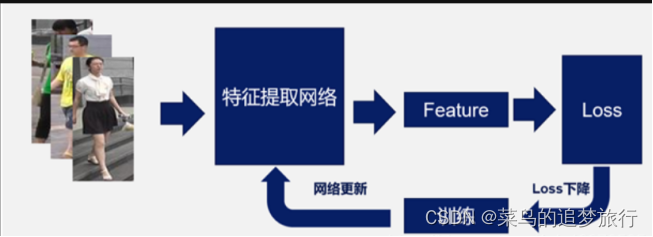
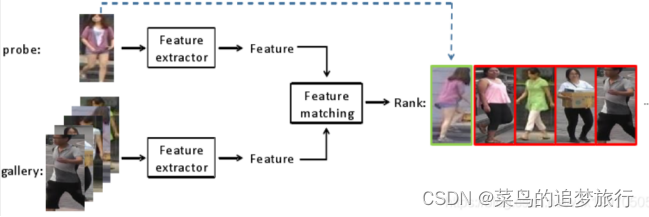
上面这张图展示了ReID的一个任务过程,首先要做的是Detection,也就是检测出行人。剩下的部分,就是要去训练一个特征提取网络,根据特征所计算的度量距离得到损失值,选用一个优化器去迭代找到loss最小值,并不断更新网络的参数达到学习的效果。在测试的时候,用将要检索的图片(称为query或者probe),在底库gallery中,根据计算出的特征距离进行排序,选出最TOP的几张图片,来达到目标检索的目的。下面两张图分别是训练阶段和测试阶段的示意图:
1.2 实现流程
1.行人检测:通过目标检测模型提取当前帧的行人图像。
2.特征提取:基于特征提取模型,项目中现使用预训练的特征提取模型提取行人区域图片的特征向量。
3.单镜头行人跟踪:结合行人区域特征,通过deepsort等算法进行行人跟踪。
4.跨镜头行人跟踪:基于深度学习的全局特征和数据关联实现跨镜头行人目标跟踪。
5.向量存储与检索:对于给定的行人查询向量,与行人特征库中所有的待查询向量进行向量检索,即计算特征向量间的相似度(计算余弦距离等方法)。
在以上步骤中,特征提取是最关键的一环,它的作用是将输入的行人图片转化为固定维度的特征向量,以用于后续的目标跟踪和向量检索。好的特征需要具备良好的相似度保持性,即在特征空间中,相似度高的图片之间的向量距离比较近,而相似度低的图片对的向量距离比较远。通常用于训练这种模型的方式叫做度量学习。
注解:
全局特征:每一张图片的全局信息进行一个特征抽取,全局特征没有任何的空间信息。局部特征:对图像的某一个区域进行特征提取,最后将多个局部特征融合起来作为最终特征。度量学习:将学习到的特征映射到新的空间,表现为同一行人的不同图片间的相似度大于不同行人的不同图片(即相同的人更近,不同的人更远)。图像检索:根据图片特征之间的距离进行排序,返回检索结果。
1.3 重识别存在的技术挑战
ReID 在实际应用场景下的数据非常复杂,由于不同摄像设备之间的差异,同时行人兼具刚性和柔性的特性 ,外观易受穿着、尺度、遮挡、姿态和视角等影响,所以,对跨镜追踪(ReID)算法的要求也更高。
实际应用中常常出现:
无正面照;服装更换;遮挡;图像分辨率低;光线差异;室内室外场景变化

2、训练数据格式介绍
- 通过人工标注或者检测算法得到的行人图片
- 数据集分为训练集,验证集,query以及gallery
- 在训练集上进行模型的训练,得到模型后对query与gallery中的图片特征提取特征计算相似度,对于每个query在gallery中找出前N个与其相似的图片
- 训练,测试中人物身份不重复
常用的几种数据集:
1)Market-1501:Person Re-Identification Meets Image Search
链接:https://pan.baidu.com/s/1ntIi2Op
2015年,论文 Person Re-Identification Meets Image Search 提出了 Market 1501 数据集,现在 Market 1501 数据集已经成为行人重识别领域最常用的数据集之一。 Market 1501 的行人图片采集自清华大学校园的 6 个摄像头,一共标注了 1501 个行人。其中,751 个行人标注用于训练集,750个行人标注用于测试集,训练集和测试集中没有重复的行人 ID,也就是说出现在训练集中的 751 个行人均未出现在测试集中。
训练集:751 个行人,12936 张图片
测试集:750 个行人,19732 张图片
query 集:750 个行人,3368 张图片
query 集的行人图片都是手动标注的图片,从 6 个摄像头中为测试集中的每个行人选取一张图片,构成query 集。
测试集中的每个行人至多有 6 张图片,query 集共有 3368 张图片。
网络模型训练时,会用到训练集;测试模型好坏时,会用到测试集和query 集。此时测试集也被称作gallery集。因此实际用到的子集为,训练集、gallery 集和query 集。
2)MARS: A Video Benchmark for Large-Scale Person Re-identification(基于视频)
链接:https://pan.baidu.com/s/1XKBdY8437O79FnjWvkjusw 提取码: ymc5
考虑了视频中的人员再识别(reid)问题,本文介绍了一个新的视频reid数据集,名为运动分析和重新识别集(MARS),是Market-1501的datase数据集的视频扩展。
MARS是迄今为止最大的视频reid数据集,它包含1,261个id和大约20,000个tracklet,与基于图像的数据集相比,它提供了丰富的视觉信息。
3)DukeMTMC-reID:Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
链接:https://drive.google.com/open?id=1jjE85dRCMOgRtvJ5RQV9-Afs-2_5dY3O
它的行人数据来源于论文 Performance Measures and a Data Set for Multi-Target,
Multi-Camera Tracking 提出的行人追踪 DukeMTMC 数据集,DukeMTMC-reID 是 DukeMTMC数据集的一个子集。需要注意的是,该数据集存在隐私泄露问题,作者已在官方渠道下架数据集。目前部分顶会文章仍在使用。DukeMTMC 数据集采集自 Duke 大学的 8 个摄像头,数据集以视频形式存储,具有手动标注的行人边界框。DukeMTMC-reID数据集从 DukeMTMC 数据集的视频中,每 120 帧采集一张图像构成 DukeMTMC-reID数据集。原始数据集包含了85分钟的高分辨率视频,采集自8个不同的摄像头。并且提供了人工标注的bounding box。从视频中每120帧采样一张图像,得到了 36411张图像。一共有1404个人出现在大于两个摄像头下,有408个人只出现在一个摄像头下。所以作者随机采样了 702个人作为训练集,702个人作为测试集。在测试集中,采样了每个ID的每个摄像头下的一张照片作为 查询图像(query)。剩下的图像加入测试的搜索库(gallery),并且将之前的 408人作为干扰项,也加到 gallery中。最终,DukeMTMC-reID 包含了16522张训练图片(来自702个人), 2228个查询图像(来自另外的702个人),以及 17661张图像的搜索库(gallery)。并提供切割后的图像供下载。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (NeRF学习)NeRF复现 win11
- 关于“等待”的交互设计
- 如何用一份完美简历锁定心仪工作?
- 2023最新最全【Kali Linux】入门教程【从零基础入门到精通】附安装包
- 【想0基础转行】Python和Web前端怎么选?哪个更简单、更符合趋势?
- 基于SpringBoot的车险理赔管理系统的设计与实现
- 【Vue第6-7章】vue-router与Vue UI组件库_Vue2
- 丢失的数字算法(leetcode第268题)
- 老牌网站监测应用 Pingdom 体验,与百川云网站有什么区别?
- ConcurrentHashMap深度分析