机器学习-线性回归实践
发布时间:2024年01月09日
目标:使用Sklearn、numpy模块实现展现数据预处理、线性拟合、得到拟合模型,展现预测值与目标值,展现梯度下降;
一、导入模块
import numpy as np
np.set_printoptions(precision=2)
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.preprocessing import StandardScaler
from lab_utils_multi import load_house_data
import matplotlib.pyplot as plt
from lab_utils_multi import load_house_data, compute_cost, run_gradient_descent
from lab_utils_multi import norm_plot, plt_contour_multi, plt_equal_scale, plot_cost_i_w
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000';dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')二、导入数据集
x_train, y_train = load_house_data()
#设置特征变量
X_feature = ['size(sqft)','bedrooms','floors','age']三、 训练数据集
scaler = StandardScaler()
X_norm = scaler.fit_transform(x_train)
print(f"Peak to Peak range by column in Raw X:{np.ptp(x_train,axis=0)}")
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")四、创建模型并进行拟合
sgdr = SGDRegressor(max_iter=1000)
sgdr.fit(X_norm, y_train)
print(sgdr)
print(f"number of iterations completed: {sgdr.n_iter_}, number of weight updates: {sgdr.t_}")五、 进行预测
b_norm = sgdr.intercept_
w_norm = sgdr.coef_
y_pred_sgd = sgdr.predict(X_norm)
y_pred = np.dot(X_norm, w_norm) + b_norm 六、可视化预测值与目标值
fig,ax=plt.subplots(1,4,figsize=(12,3),sharey=True)
for i in range(len(ax)):
ax[i].scatter(x_train[:,i],y_train, label = 'target')
ax[i].set_xlabel(X_feature[i])
ax[i].scatter(x_train[:,i],y_pred,color=dlorange, label = 'predict')
ax[0].set_ylabel("Price"); ax[0].legend();
fig.suptitle("target versus prediction using z-score normalized model")
plt.show()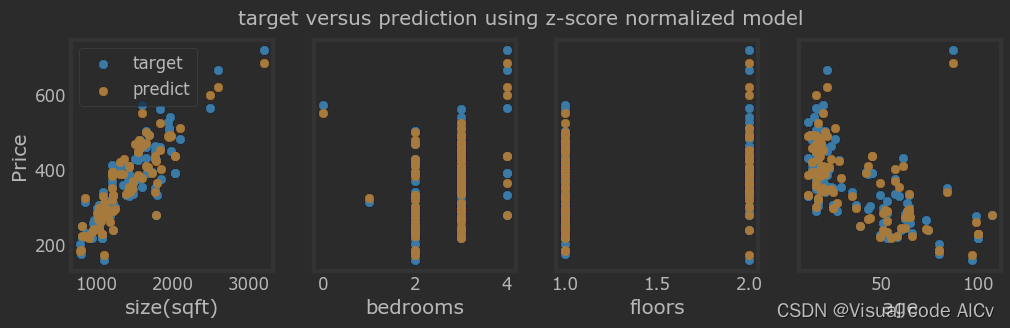 ?
?
?七、梯度下降α=1e-7
_, _, hist = run_gradient_descent(x_train, y_train, 10, alpha = 1e-7)
plot_cost_i_w(x_train, y_train, hist)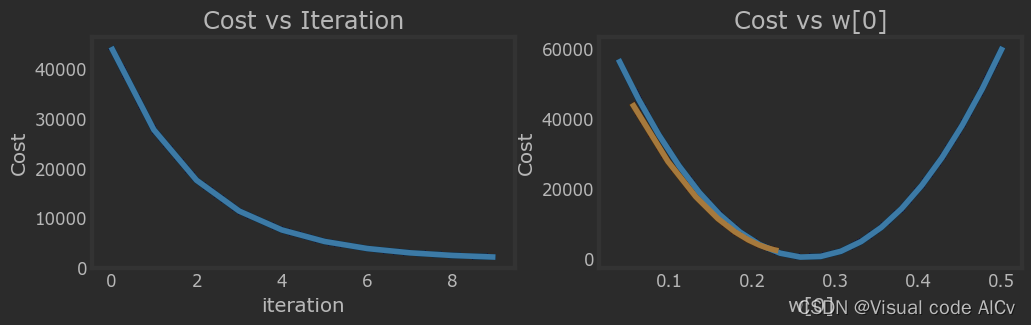
文章来源:https://blog.csdn.net/m0_65995252/article/details/135491746
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 213. 打家劫舍 II
- MySQL 8.0中新增的功能(二)
- springcloud getway 网关之过滤器filter
- 【跳槽面试】Redis中分布式锁的实现
- 爬虫中,代理 IP 有哪些常见用途?
- System.Data.SqlClient.SqlException:“在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误
- MysqL——深入MySQL原理(一)
- 10 个顶级的 OBS 录屏替代品知识分享
- 14、Kafka ------ kafka 核心API 之 流API(就是把一个主题的消息 导流 到另一个主题里面去)
- 一个JSON.parse的问题,让我丢掉了字节的 offer!