寒武纪显卡实现softmax算子
寒武纪显卡实现softmax基本逻辑
寒武纪实现softmax包括下面5个步骤,我们也采取5个kernel来实现softmax:
unionMaxKernel(float* middle, float* source1, int num),这个kernel使用的任务类型是union1,其中middle的长度为taskDim,达到的目的是middle对应元素存储的是不同taskId处理的那部分数据的局部max
blockMaxKernel(float* dstMax, float* middle, int taskNum),这个kernel使用的任务类型是BLOCK,任务总数也是1,其中dstMax的长度为1,达到的目的是将长度为taskDim的middle进一步做max规约得到全局max
unionSumKernel(float* middle, float* source1, int num, float globalMax),这个kernel使用的任务类型是union1,其中middle的长度为taskDim,达到的目的是middle对应元素存储的是不同taskId处理的那部分数据的局部数值和,其中globalMax就是上面两个kernel计算出来的全局max
这个函数特别值得注意的是,由于寒武纪显卡无法直接针对向量source1的特定元素进行操作,为此我们引入了一个中间向量tmp[maxNum],其中tmp每个元素都是-globalMax,借助于__bangd_add来实现source1 = source1 + tmp。除此之外,寒武纪有3个实现exp的函数,但是经过查证,这三个exp函数的数值精度差距很大,由于经过线性变换以后source1的元素都在负半轴,因此这里我们使用__bang_active_exp_less_0函数来提高精度,详细内容可以参考官网链接说明
blockSumKernel(float *dstSum, float *middle, int taskNum),这个kernel使用的任务类型是BLOCK,任务总数也是1,其中dstSum的长度为1,达到的目的是将长度为taskDim的middle进一步做sum规约得到全局sum
softmaxKernel(float *dst, float *source1, float globalMax, float globalSum, int num),这个kernel使用的dst,source1长度都是num,globalMax,globalSum在上面已经计算出来,最终希望dst存储最终的softmax结果。
编译命令为:
cncc softmax.mlu -o softmax --bang-mlu-arch=mtp_372 -O3
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destMax;//方便后面比较最大值
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__mlu_entry__ void unionMaxKernel(float* middle, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
destMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destMax < src1[0]){
destMax = src1[0];
}
}
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destMax < src1[0]){
destMax = src1[0];
}
}//结束以后向量destMax保存了source1[indSart:indStart+step]这部分数据的全局最大值
__memcpy(middle + taskId, &destMax, sizeof(float), NRAM2GDRAM);//middle长度为taskDim
}
//----------------------
__mlu_entry__ void blockMaxKernel(float* dstMax, float* middle, int taskNum) {//将长度为taskDim的middle继续做Max规约
int remain = taskNum%warpSize;
int repeat = (taskNum - remain)/warpSize;//如果taskDim太大,超过warpSize,使用for循环规约
__nram__ float srcMid[warpSize];
destMax = -INFINITY;
for(int i = 0; i < repeat; i++){
__memcpy(srcMid, middle + i * warpSize, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_argmax(srcMid, srcMid, warpSize);
if(destMax < srcMid[0]){
destMax = srcMid[0];
}
}
if(remain){
__bang_write_value(srcMid, warpSize, -INFINITY);//初始化srcMid全部元素为负无穷
__memcpy(srcMid, middle + repeat * warpSize, remain * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMid, srcMid, warpSize);
if(destMax < srcMid[0]){
destMax = srcMid[0];
}
}
__memcpy(dstMax, &destMax, sizeof(float), NRAM2GDRAM);//这个kernel只能使用Block类型,1个任务
}
__mlu_entry__ void unionSumKernel(float* middle, float* source1, int num, float globalMax) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
__nram__ float tmp[maxNum];
__bang_write_value(tmp, maxNum, -globalMax);//初始化tmp全部元素为-globalMax
__bang_write_zero(destSum, maxNum);
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(src1, tmp, src1, maxNum);//src1 = src1 - globalMax
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
//__bang_active_exphp(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
__bang_add(destSum, destSum, src1, maxNum);//destSum += exp(src1 - globalMax)
}
if(remainNram){
__bang_write_value(src1, maxNum, globalMax);
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(src1, tmp, src1, maxNum);//src1 = src1 - globalMax ,后面maxNum-remainNram这部分直接为0
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
//__bang_active_exphp(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
__bang_add(destSum, destSum, src1, maxNum);//destSum在原来基础上又多加了(maxNum - remainNram)
}//结束以后长度为maxNum的向量destSum保存了source1[indSart:indStart+step]这部分数据的数值和+(maxNum - remainNram)
//__bang_printf("destSum[%d]:%.6f, src1:%.6f\n",remainNram, destSum[remainNram], src1[remainNram]);
//下面开始针对destSum做规约
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
//__bang_printf("taskId:%d,maxNum - remainNram:%d,but get sum:%.6f\n",taskId, maxNum - remainNram, destSumFinal[0]);
__memcpy(middle + taskId, destSumFinal, sizeof(float), NRAM2GDRAM);
}
//----------------------
__mlu_entry__ void blockSumKernel(float *dstSum, float *middle, int taskNum)//将长度为taskDim的middle继续做Sum规约
{
int remain = taskNum % warpSize;
int repeat = (taskNum - remain) / warpSize;
__nram__ float srcMid[warpSize];
__bang_write_zero(destSumFinal, warpSize); // 初始化destSumFinal全部元素为0
//__bang_printf("sum:%.6f\n",destSumFinal[0]);
for (int i = 0; i < repeat; i++)
{
__memcpy(srcMid, middle + i * warpSize, warpSize * sizeof(float), GDRAM2NRAM); // 每次迁移32个float数据到NRAM
__bang_add(destSumFinal, destSumFinal, srcMid, warpSize); // destSumFinal存储add结果
}
if (remain)
{
__bang_write_zero(srcMid, warpSize); // 初始化destSumFinal全部元素为0
__memcpy(srcMid, middle + repeat * warpSize, remain * sizeof(float), GDRAM2NRAM);
__bang_add(destSumFinal, destSumFinal, srcMid, warpSize); // destSumFinal存储add结果
}
__bang_reduce_sum(destSumFinal, destSumFinal, warpSize); // 针对destSumFinal规约即可把结果保存到destSumFinal[0]
//__bang_printf("xiao,taskId:%d,sum:%.6f\n", taskId, destSumFinal[0]);
__memcpy(dstSum, destSumFinal, sizeof(float), NRAM2GDRAM); // 这个kernel只能使用Block类型,1个任务
}
__mlu_entry__ void softmaxKernel(float *dst, float *source1, float globalMax, float globalSum, int num){
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum;
for(int i = 0; i < repeat; i++){
__bang_write_value(destSum, maxNum, -globalMax);//初始化destSum全部元素为-globalMax
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
//__bang_active_exphp(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSumInv,使用1.0/globalSum编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * maxNum, src1, maxNum * sizeof(float), NRAM2GDRAM);
}
if(remainNram){
__bang_write_value(src1, maxNum, -globalMax);
__bang_write_value(destSum, maxNum, -globalMax);//初始化destSum全部元素为-globalMax
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
//__bang_active_exphp(src1, src1, maxNum);//src1 = exp(src1 - globalMax)
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSumInv,使用1.0/globalSum编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src1, remainNram * sizeof(float), NRAM2GDRAM);
}
//__bang_printf("Inv:%.6f\n",globalSumInv);
}
int main(void)
{
int num = 102001010;
//int num = 10;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_middle;
float* mlu_dstMax;
float* mlu_dstSum;
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_middle, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dstMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dstSum, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
unionMaxKernel<<<dim, ktype, queue>>>(mlu_middle, mlu_src1, num);
cnrtQueueSync(queue);
//---------------------------
cnrtDim3_t dimBlock = {1, 1, 1};
blockMaxKernel<<<dimBlock, CNRT_FUNC_TYPE_BLOCK, queue>>>(mlu_dstMax, mlu_middle, taskNum);
cnrtQueueSync(queue);
float globalMax;
CNRT_CHECK(cnrtMemcpy(&globalMax, mlu_dstMax, sizeof(float), cnrtMemcpyDevToHost));
printf("max:%.6f\n",globalMax);
//----------------------------
unionSumKernel<<<dim, ktype, queue>>>(mlu_middle, mlu_src1, num, globalMax);
cnrtQueueSync(queue);
//---------------------------
blockSumKernel<<<dimBlock, CNRT_FUNC_TYPE_BLOCK, queue>>>(mlu_dstSum, mlu_middle, taskNum);
cnrtQueueSync(queue);
float globalSum;
CNRT_CHECK(cnrtMemcpy(&globalSum, mlu_dstSum, sizeof(float), cnrtMemcpyDevToHost));
printf("sum:%.6f\n",globalSum);
//----------------------------
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//printf("max:%.6f,sum:%.6f\n", globalMax ,globalSum);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_middle);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
softmax融合
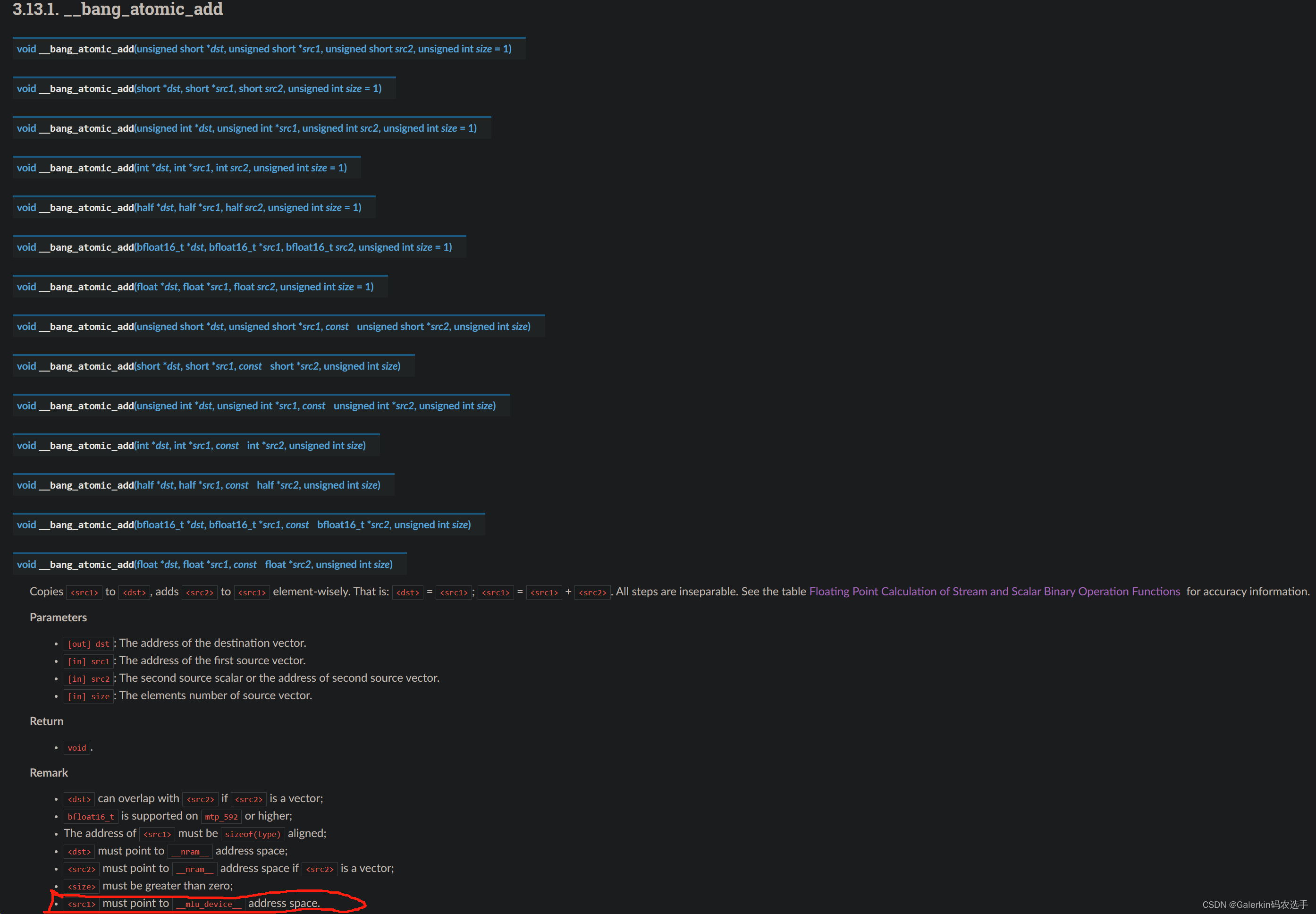
借助于__bang_atomic_add和__bang_atomic_max两个函数,我们可以把上面的5个kernel融合成一个kernel,代码框架逻辑和上面完全一样,我们以__bang_atomic_add函数来重点介绍一下寒武纪显卡的原子操作,该函数涉及到三个向量的原子操作,其中dst和src2都是NRAM上的向量,但是src1是__mlu_device__上的向量,对于我们的代码,比如说上面的sum规约例子,不同的taskId最后都会得到一个结果保存在destSumFinal[0],这个结果保存的是taskId对应的这部分数据的数值和,而我们需要获得全局数值和。之前的做法是,我们把不同taskId的结果保存在全局内存变量middle里面,middle的长度为taskDim,然后借助于另一个kernel对middle规约。现在我们有了原子操作,我们可以借助于原子操作把不同taskId的结果直接累加到全局变量里面。

上面三行代码结束以后,不管是哪个taskId,计算出来的globalSum都是一样的结果,也就是不同taskId对应的destSumFinal[0]相加的结果,这里特别值得注意的就是调用原子操作之前一定要先做同步,保证不同taskId都计算结束,其次就是globalSum必须设置为指针型向量,不能使用常数。详细代码如下所示:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destMax;//方便后面比较最大值
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
//------------------------------------下面开始计算max
destMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destMax < src1[0]){
destMax = src1[0];
}
}
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destMax < src1[0]){
destMax = src1[0];
}
}//结束以后向量destMax保存了source1[indSart:indStart+step]这部分数据的全局最大值
globalMax[0] = -INFINITY;
__sync_all();
__bang_atomic_max(&destMax, globalMax, &destMax, 1);//globalMax[0]必须初始化为负无穷
//------------------------------------下面开始计算sum
__nram__ float tmp[maxNum];
__bang_write_value(tmp, maxNum, -globalMax[0]);//初始化tmp全部元素为-globalMax[0]
__bang_write_zero(destSum, maxNum);
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(src1, tmp, src1, maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_add(destSum, destSum, src1, maxNum);//destSum += exp(src1 - globalMax[0])
}
if(remainNram){
__bang_write_value(src1, maxNum, globalMax[0]);
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(src1, tmp, src1, maxNum);//src1 = src1 - globalMax[0] ,后面maxNum-remainNram这部分直接为0
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_add(destSum, destSum, src1, maxNum);//destSum在原来基础上又多加了(maxNum - remainNram)
}//结束以后长度为maxNum的向量destSum保存了source1[indSart:indStart+step]这部分数据的数值和+(maxNum - remainNram)
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
__sync_all();
globalSum[0] = 0.0;
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
//------------------------------------下面开始计算softmax
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat; i++){
__bang_write_value(destSum, maxNum, -globalMax[0]);//初始化destSum全部元素为-globalMax[0]
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSum[0]Inv,使用1.0/globalSum[0]编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * maxNum, src1, maxNum * sizeof(float), NRAM2GDRAM);
}
if(remainNram){
__bang_write_value(src1, maxNum, -globalMax[0]);
__bang_write_value(destSum, maxNum, -globalMax[0]);//初始化destSum全部元素为-globalMax[0]
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSum[0]Inv,使用1.0/globalSum[0]编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src1, remainNram * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,max:%.6f, sum:%.6f\n",taskId, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 102001010;
//int num = 10;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
softmax同时计算max和sum
回忆之前英伟达平台编写softmax的经验,当时我们引入了一个结构体来存储计算过程中的max和数值和,

这里我们也采取类似的思路来减少从GDRM到NRAM的数据访问频率,我们以下面这段代码为例子重点介绍如何运用寒武纪框架一边计算全局max,一边计算数值和。
代码29行初始化一个变量destNewMax为负无穷,方便后面比较最大值
进入循环以后,代码31行开始根据循环体不断读取全局变量不同位置的数据,将数值转移到NRAM数组src1上
代码32行借助于函数__bang_argmax计算出src1的最大值和对应的索引,注意__bang_argmax的两个向量参数长度必须相同,但是第一个向量计算以后索引为0的位置存储的是value,索引为1的位置存储的是index
代码33行——35行开始判断是否要更新最大值destNewMax
代码36行——38行其实就是在做一个src1 = exp(src1-destNewMax),只不过本人一时半会没有找到一个函数可以直接让向量减去一个常数,为此这里使用__bang_add来达成目的
代码39行——44行,这里必须要判断当前循环数是否大于0,i = 0的时候destSum = src1即可,但是一旦i大于0,destSum = destSum×exp(destOldMax - destNewMax) + src1,这一步就是保证数值和正确的关键,每次循环都会更新最大值,所以每次循环都要对上一次的数值和destSum做一个缩放,并且每次循环都需要更新destOldMax的数值
代码46行——61行这部分代码的逻辑和上面这个循环类似,只不过是针对无法整除多余的那部分做了一点特殊处理:
代码47行这里必须要对src1重新初始化为负无穷,因为经过上面的循环以后,src1都已经有值了,如果这里步重新初始化覆盖,就会导致前remainNram个元素是source1末尾的这部分元素,但是后面maxNum-remainNram这部分元素还是上一轮循环的结果,此时盲目去比较最大值,是无法得到前remainNram个元素的最大值的
代码53行也是类似,必须要重新初始化src1,要不然src1会有一部分负无穷

#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
//------------------------------------下面开始计算max
__nram__ float tmp[maxNum];
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < src1[0]){
destNewMax = src1[0];//更新最大值
}
__bang_write_value(tmp, maxNum, -destNewMax);
__bang_add(src1, tmp, src1, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_write_value(tmp, maxNum, exp(destOldMax - destNewMax));
__bang_mul(destSum, destSum, tmp, maxNum);//destSum = destSum * exp(destOldMax - destNewMax)
}
__bang_add(destSum, destSum, src1, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < src1[0]){
destNewMax = src1[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_write_value(tmp, maxNum, -destNewMax);
__bang_add(src1, tmp, src1, maxNum);//后面maxNum-remainNram部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remainNram
if(repeat > 0){
__bang_write_value(tmp, maxNum, exp(destOldMax - destNewMax));
__bang_mul(destSum, destSum, tmp, maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}//结束以后向量destNewMax保存了source1[indSart:indStart+step]这部分数据的全局最大值,destSum保存数值和
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat; i++){
__bang_write_value(destSum, maxNum, -globalMax[0]);//初始化destSum全部元素为-globalMax[0]
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSum[0]Inv,使用1.0/globalSum[0]编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * maxNum, src1, maxNum * sizeof(float), NRAM2GDRAM);
}
if(remainNram){
__bang_write_value(src1, maxNum, -globalMax[0]);
__bang_write_value(destSum, maxNum, -globalMax[0]);//初始化destSum全部元素为-globalMax[0]
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(src1, destSum, src1, maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_write_value(destSum, maxNum, globalSumInv);//初始化destSum全部元素为globalSum[0]Inv,使用1.0/globalSum[0]编译报错
__bang_mul(src1, src1, destSum, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src1, remainNram * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,max:%.6f, sum:%.6f\n",taskId, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 102001010;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
__bang_sub_scalar和__bang_mul_scalar的使用
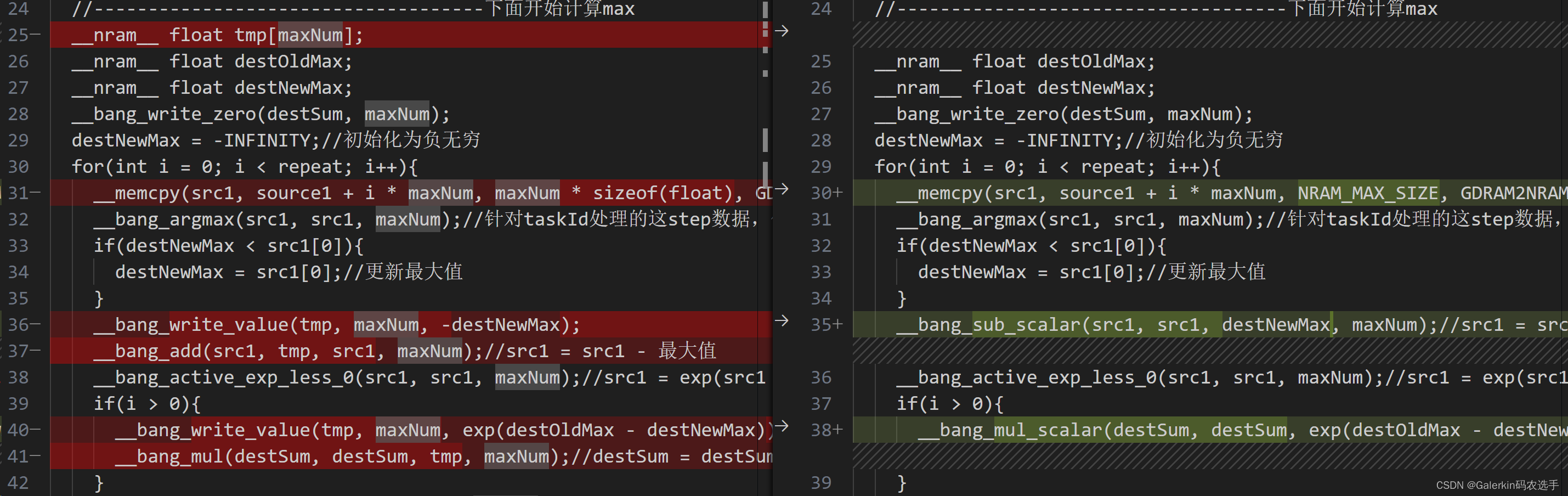
经过查找,我们发现寒武纪里面有两个函数__bang_sub_scalar和__bang_mul_scalar可以直接实现向量减去一个常数以及向量×一个常数,为此我们可以删减中间变量tmp,加大maxNum,通过VS code的对比功能可以很容易发现两个代码之间的差距
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 256;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
//------------------------------------下面开始计算max
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < src1[0]){
destNewMax = src1[0];//更新最大值
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);//destSum = destSum * exp(destOldMax - destNewMax)
}
__bang_add(destSum, destSum, src1, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < src1[0]){
destNewMax = src1[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-remainNram部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remainNram
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}//结束以后向量destNewMax保存了source1[indSart:indStart+step]这部分数据的全局最大值,destSum保存数值和
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * maxNum, src1, NRAM_MAX_SIZE, NRAM2GDRAM);
}
if(remainNram){
__bang_write_value(src1, maxNum, -globalMax[0]);
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src1, remainNram * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 102001010;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- webpack/vue-cli构建速度和打包体积优化
- 最牛量子处理器Heron亮相,IBM让量子计算不再空谈理论
- 【LeetCode刷题笔记】字符串
- 并发编程之ReentrantReadWriteLock详解
- CloudPulse:一款针对AWS云环境的SSL证书搜索与分析引擎
- Linux系统常用的安全优化
- 计算机视觉基础(11)——语义分割和实例分割
- 回归预测 | MATLAB实ZOA-LSTM基于斑马优化算法优化长短期记忆神经网络的多输入单输出数据回归预测模型 (多指标,多图)
- 通义灵码 - 免费的阿里云 VS code Jetbrains AI 编码辅助工具
- 【华为OD真题 Python】贪吃的猴子