分布变化下的Test-Time adaption 综述
论文??https://arxiv.org/abs/2303.15361
代码??https://github.com/tim-learn/awesome-test-time-adaptation?(其实这是相关领域代码和论文合集之类的东西)
Abstract
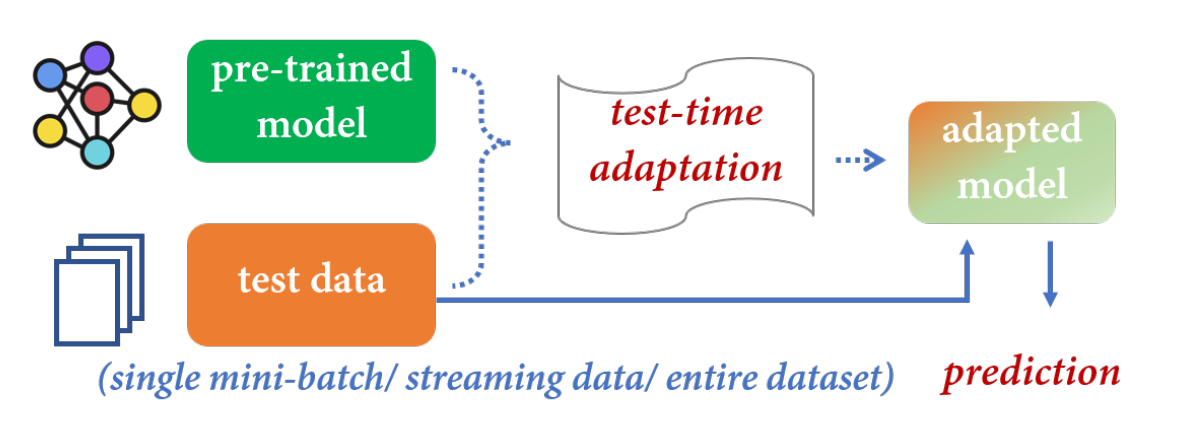
机器学习方法努力在训练过程中获得一个鲁棒模型,即使在分布变化的情况下也能很好地泛化到测试样本。然而,由于未知的测试分布,这些方法的性能经常会下降。测试时适应(TTA)是一种新兴的范式,它有可能在做出预测之前,在测试期间使预训练的模型适应未标记的数据。该范式的最新进展突出了利用未标记数据进行训练的显著好处
自适应模型先于推理。在本研究中,我们将TTA划分为几个不同的类别,即测试时间(无源)域自适应、测试时间批量自适应、在线测试时间自适应和测试时间先验自适应。对于每个类别,我们都提供了高级算法的综合分类,然后讨论了不同的学习场景。此外,我们还分析了TTA的相关应用,并讨论了未来研究的开放挑战和前景。
Background
传统机器学习假设训练和测试数据是分开的。然而当测试分布(目标)与训练分布(源)不同时,我们面临分布移位distribution shifts的问题。e.g天气,相机等
域泛化domain generalization(DG)[5]旨在使用来自一个或多个源域的数据来学习模型,该模型可以很好地泛化到任何非分布的目标域。另一方面,领域自适应(domain adaptation, DA)[6]遵循转导学习原理,将知识从标记的源领域转移到未标记的目标领域。DG只在训练阶段操作,而TTA的优势在于能够在测试阶段从目标域访问测试数据。这使得TTA能够通过适应可用的测试数据来提高识别性能。
Classification
-
测试时域自适应 (Test-time Domain Adaptation, TTDA):
- 定义: 在测试时,模型通过对目标域的数据进行适应来提高性能,以便更好地适应新的领域。
- 特点: 主要关注在测试时适应模型,以适应目标领域的分布,从而提高性能。
-
无源域自适应 (Source-Free Domain Adaptation, SFDA):
- 定义: 类似于测试时域自适应,但是在这种情况下,模型在没有目标域标签的情况下进行适应。
- 特点: SFDA关注在没有目标域标签的情况下适应模型,这对于目标领域没有标签信息的情况下非常有用。
-
测试时批次自适应 (Test-time Batch Adaptation, TTBA):
- 定义: 在测试时,模型根据目标领域的一批样本进行适应,而不是整个领域。
- 特点: TTBA注重通过处理目标领域中的一小批样本来进行适应,以更好地适应该批次的分布。
-
在线测试时自适应 (Online Test-time Adaptation, OTTA):
- 定义: 在测试时,模型通过动态地从目标领域中获取适应数据来进行实时适应。
- 特点: OTTA强调在测试时实时地适应模型,以便模型能够根据不断变化的目标领域动态调整。
-
测试时先验自适应 (Test-time Prior Adaptation, TTPA):
- 定义: 在测试时,模型利用先验知识或先验信息来进行适应,以提高性能。
- 特点: TTPA强调在测试时利用模型之前学到的先验知识,以便更好地适应新的任务或领域。
RELATED RESEARCH TOPICS
2.1 Domain Adaptation and Domain Generalization
数据挖掘方法依赖于源数据的存在来弥补领域差距,现有技术大致可分为四类,即输入级翻译[28]、[29]、特征级对齐[30]、[31]、[32]、输出级正则化[33]、[34]、[35]和先验估计[17]、[36]、[37]。如果可以从源模型中生成训练数据[12],那么SFDA问题可以使用标准的数据分析方法来解决。
域泛化(DG)[49],[50],[51]旨在从一个或多个不同但相关的域学习模型,这些域可以在未知的测试域上很好地泛化。研究人员经常开发特定的训练技术来提高预训练模型的泛化能力,这可以与研究的TTA范式相兼容。有关该主题的进一步信息,我们建议读者参考现有文献(例如,[5],[52])。
2.2 Hypothesis Transfer Learning
假设迁移学习(htl)[53]是迁移学习的另一种特殊情况,其中预训练的模型(源假设)保留了先前遇到的任务的信息。浅层次html方法[54]、[55]、[56]、[57]、[58]、[59]通常假设最优目标假设与这些源假设密切相关。
2.3 Continual Learning and Meta-Learning
持续学习(continuous learning, CL)[63]的目的是按顺序学习多个任务的模型,在该模型中,从前一个任务中获得的知识逐渐积累,用于未来的任务。task-incremental, domain-incremental, and class-incremental learning
元学习Meta-Learning[74]与持续学习有着相似的假设,但训练数据是从任务分布中随机抽取的,而测试数据是样本较少的任务。
2.4 Data-Free Knowledge Distillation
知识蒸馏(Knowledge distillation, KD)[76]旨在通过匹配网络输出或中间特征,将知识从教师模型转移到学生模型。为了解决隐私和机密性问题,提出了无数据KD范式[23],无需访问原始训练数据。
与TTA相比,无数据KD在模型之间进行知识转移,而不是在分布转移的数据集之间进行知识转移。
2.5 Self-Supervised and Semi-Supervised Learning
自监督学习[84]是一种学习范式,其重点是如何通过利用其底层结构的借口任务从数据本身获取监督信号,从而从未标记数据中学习。对于TTA任务,这些自监督学习技术可以用来帮助学习判别特征[98]或作为辅助任务[8]。
半监督学习[99]是另一种学习范式,涉及利用未标记数据来减少对标记数据的依赖。对于TTA任务,这些半监督学习技术可以很容易地整合到无监督地更新预训练模型中。
2.6 Test-Time Augmentation
数据增强技术[108],如几何变换和色彩空间增强,可以创建训练图像的修改版本,从而提高深度模型对未知扰动的抗业务能力。通常,Test-Time Augmentation技术不明确地考虑分布变化,但可以通过TTA方法加以利用。
ONLINE TEST-TIME ADAPTATION
以前,我们已经考虑了各种测试时适应场景,其中预训练的源模型在测试时适应于一个域[7]、[12]、一个小批量[13]、[447],甚至是单个实例[8]、[14]。然而,脱机测试时间适应通常需要一定数量的样本来形成一个小批或一个域,这对于数据连续和顺序到达的流数据场景可能是不可行的。为了像在线学习一样重用过去的知识,TTT[8]采用了一种在线变体,它不针对每个输入间歇性地优化模型,而是保留了针对最后一个输入的优化模型。
给定源域DS上训练良好的分类器fS和一系列未标记的小批次{B1, B2,···},OTTA旨在利用fS中隐含的标记知识在线推断出Bi中样本在分布移位下的标签。换句话说,在先前看到的小批量中学习的知识可以积累以适应当前的小批量。
上述定义对应于Tent[9]中解决的问题,其中从不同于源数据分布的新数据分布中抽取多个小批量样本。此外,它还包含在线测试时间实例适应问题,如TTT-Online[8]中在批大小为1时引入的问题。然而,测试时的样本可能来自各种不同的分布,导致新的挑战,如错误积累和灾难性遗忘。为了解决这个问题,CoTTA[483]和EATA[484]研究了连续测试时间适应问题,使预训练的源模型适应不断变化的测试数据。这种非平稳适应问题也可以视为上述定义的一种特殊情况,其中每个小批可能来自不同的分布。
分类 Taxonomy on OTTA Algorithms?
Batch Normalization Calibration(批次标准化校准):
- 定义: 在测试时,通过调整模型的批次标准化参数,以适应目标领域的统计特性,从而提高性能。
- 特点: 主要关注批次标准化的校准,以使模型在目标领域中更好地适应统计特性。
BN 层可以将特定领域的知识编码为规范化统计[335]。
Entropy Minimization(熵最小化):
- 定义: 在测试时,通过最小化模型对目标领域样本的预测熵,来使模型更加确定性,提高性能。
- 特点: 通过减小模型对目标领域样本的不确定性,从而提高适应性。
Pseudo-labeling(伪标签):
- 定义: 在测试时,通过使用模型的预测结果作为伪标签,将目标领域中的无标签样本纳入训练,以提高性能。
- 特点: 利用模型对目标领域的预测,将无标签样本引入训练过程,以帮助模型适应目标领域。
Consistency Regularization(一致性正则化):
- 定义: 在测试时,通过在目标领域样本的多次预测之间增加一致性约束,以提高模型性能。
- 特点: 强调模型对相同输入的一致性,使其更稳定地适应目标领域。
Anti-forgetting Regularization(防遗忘正则化):
- 定义: 在测试时,通过保持模型对源领域的知识,防止模型在适应目标领域时遗忘源领域的知识。
- 特点: 通过正则化来确保在适应新领域时不会丢失对源领域的学习。
Miscellaneous Methods(其他方法):
- 定义: 包括各种其他在线测试时自适应的方法,可能结合了不同的策略或技术,以适应不同的应用场景。
Learning Scenarios of OTTA Algorithms
Stationary v.s. Dynamic.? 有两类OTTA任务。
Vanilla OTTA[9]假设测试数据来自平稳分布,连续OTTA[483]假设测试数据来自连续变化的分布
OTTA算法之间的其他区别与TTBA算法之间的区别相同,即实例vs批处理,自定义vs实时,单个vs多个。i.e., instance v.s. batch,? customized v.s. on-the-fly,? and single v.s. multiple.
OTTA适用于那些在实际应用中需要不断适应新数据、新任务或新环境的情况。例如,在移动机器人、自动驾驶汽车、实时监测系统等领域,模型需要实时适应新的输入条件。
Applications
1.Image Classification
2 Semantic Segmentation
3 Object Detection
?4 Beyond Vanilla Object Images
5 Beyond Vanilla Recognition Problems
6 Natural Language Processing (NLP)
7 Beyond CV and NLP - graph,speech, miscellaneous, reinforcement
Evaluation
顾名思义,TTA方法需要在测试时间优化后立即对测试数据的性能进行评估。然而,在该领域有不同的评估TTA方法的协议,因此严格的评估协议很重要。
首先,一些SFDA工作,特别是领域自适应语义分割[126],[131]和DomainNet上的分类,将源模型适应于未标记的目标集,并在与目标集共享相同分布的测试集上评估性能。然而,这在原则上违反了TTA的设置,尽管测试集上的性能始终与目标集的性能一致。我们建议这些SFDA方法同时报告目标集上的性能。
其次,一些SFDA的工作,如BAIT[274]在他们的论文中提供了一个在线版本,但这种在线SFDA方法与OTTA的不同之处在于评估在一整个epoch之后进行。我们建议在线SFDA方法更名为“one-epoch SFDA”,以避免与OTTA方法混淆。
第三,对于连续TTA方法[483]、[484],在对每个小批量进行优化之前,先对每个小批量进行评估。这种方式不同于OTTA[8]的标准评价方案,在评价之前进行优化。我们建议连续TTA方法遵循与香草TTA方法相同的协议。
EMERGING TRENDS AND OPEN CHALLENGES
trends
Diverse downstream fields.
Black-box pre-trained models.?
Open-world adaptation.
Memory-efficient continual adaptation.?
On-the-fly adaptation.?
现有的大多数TTA方法都需要从源域定制预训练模型,这给即时适应带来了不便。因此,fully test-time adaptation[9],它允许在On-the-fly模型中进行适应,越来越受到关注。
Problem
Theoretical analysis.
Benchmark and validation.?
New applications.?
Trustworthiness.?
Trustworthiness.?
CONCLUSION
学习如何使预训练模型适应分布变化下的未标记数据是机器学习领域中一个新兴的关键问题。本调查提供了四个相关主题的全面综述:无源域自适应、测试时间批量自适应、在线测试时间自适应和测试时间先验自适应。这些主题被统一为测试时间适应的广泛学习范式。对于每个主题,我们首先介绍其历史和定义,然后是高级算法的新分类。此外,我们还提供了与TTA相关的应用综述,以及新兴的研究趋势和开放性问题的展望。我们相信这一调查将有助于新手和有经验的研究者更好地了解分布变化下测试时间适应的研究现状。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- YOLO数据处理工具函数合集
- 例如,用一个DatabaseRow类型表示一个数据库行(容器),用泛型Column<T>作为它的键
- win11 or win10 安装Ubuntu 22.04.3 LTS 子系统
- sysbench在mysql中的使用
- 【已解决】You have an error in your SQL syntax
- 查看自己超算账号上剩余储存空间教程
- 解决Qt Creator中文乱码的问题
- 最新Python深度学习技术进阶与应用
- docker-compose安装mongodb
- Vue面试指南:探索Vue的核心概念和高级特性2