大模型 RAG 面试篇
发布时间:2024年01月19日
1.LLMs 存在模型幻觉问题,请问如何处理?
?检索+LLM。
先用问题在领域数据库里检索到候选答案,再用LLM对答案进行加工。
2.基于LLM+向量库的文档对话 思路是怎么样?
- 加载文件
- 读取文本
- 文本分割
- 文本向量化
- 问句向量化
- 在文本向量中匹配出与问句向量最相似的top k个
- 匹配出的文本作为上下文和问题一起添加到 prompt 中
- 提交给 LLM 生成回答
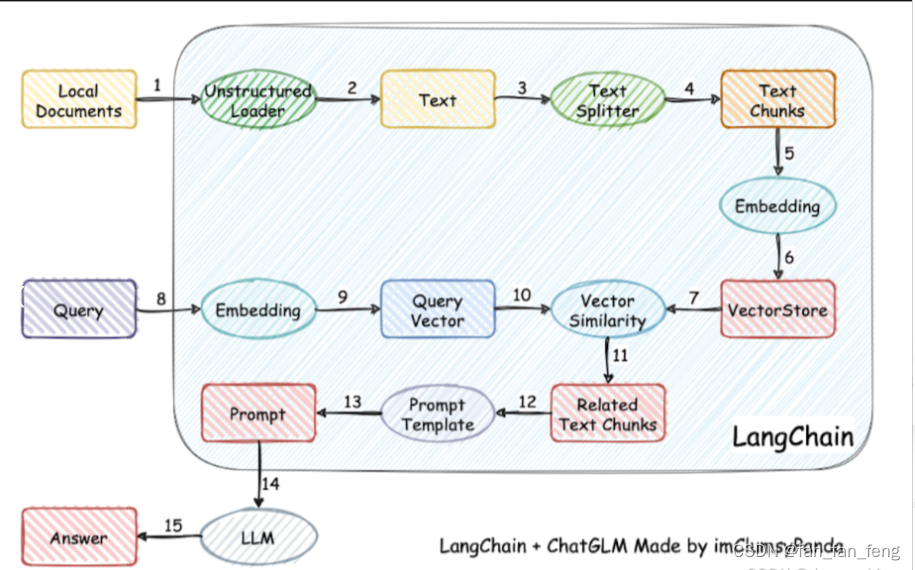
3.基于LLM+向量库的文档对话 核心技术是什么?
- 基于LLM+向量库的文档对话 核心技术:embedding
- 思路:将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 promt 提交给 LLM 回答
4.基于LLM+向量库的文档对话 prompt 模板 如何构建?
已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
文章来源:https://blog.csdn.net/fan_fan_feng/article/details/135702566
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ARM的一些基础知识
- ?springboot代码混淆及反混淆代码工具
- 【Minecraft外网联机教程】Linux搭建我的世界MC服务器
- OVF简介(Open Virtualization Format:开放虚拟化格式 )
- 【LeetCode】每日一题 2023_12_27 保龄球游戏的获胜者(模拟)
- vditor显示不出来、vditor无法渲染、Vditor无法正常使用,永久解决问题思路
- AP8660 USB升压线充电宝 5-12V光猫 K2路由器电源连接线
- VUE--插槽slot(将父级的模块片段插入到子级中)
- 力扣精选算法100题——四数之和(双指针专题)
- 阿里云服务器ECS入门与基础运维