【基础】【Python网络爬虫】【14.多进程与多线程】并发、并行、同步、异步(附大量案例代码)(建议收藏)
Python网络爬虫基础
一、通俗理解并发编程中的相关核心概念
核心概念:进程、线程和互斥锁
CPU的作用- 计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。
- CPU的核数(多核计算机多个CPU,大部分情况下也只是用了一核CPU)
- 假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单核CPU一次只能运行一个任务(同一时刻只能干一件事)。
进程 :就好比工厂的车间,它代表CPU所能处理的单个任务。- 基于车间来聊:
- 一个车间里,可以有很多工人。他们协同完成一个任务。
线程 :就好比车间里的工人。一个进程可以包括多个线程。
- 继续思考:
- 车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是被该进程下所有线程共享的,每个线程都可以使用这些共享内存。
- 基于进程空间可以被线程共享的角度—思考:
- 每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。那么如何实现呢?
- 一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫
"互斥锁",其作用是防止多个线程同时读写某一块内存区域。
二、进程
1. 什么是进程
- 广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
- 在操作系统中,每启动一个应用程序其实就是OS开启了一个进程且为进程分类对应的内存/资源,应用程序的执行也就是进程在执行。
- 狭义定义:一个正在运行的应用程序在操作系统中被视为一个进程
- 举例: 我们有py1文件中和py2文件,两个文件运行起来后是两个进程。
2. 进程调度
- 进程就是计算机中正在运行的一个程序或者软件,并且在上述工厂案例中,我们说单个CPU一次只能运行一个任务,那么你有没有在电脑上一边聊微信一边听音乐一边打游戏的场景啊?why?
- 是因为CPU在交替运行多个进程。
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随机进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
- 目前已实现的调度算法有:先来先服务(FCFS)调度算法、短作业优先调度算法和时间片轮转法。不过被公认的一种比较好的进程调度算法是"时间片轮转法"。
#### 时间片轮转法"调度算法的实施过程如下所述。 ####
(1) os会创建多个就绪队列存储进程,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,以此类推。并且该算法赋予各个队列中进程执行时间片(进程被运行的时间)的大小也各不相同,在优先级愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍
(2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地排队等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列。
3. 并发与并行
- 通过进程之间的调度,也就是进程之间的切换,我们用户感知到的好像是两个视频文件同时在播放,或者音乐和游戏同时在进行,那就让我们来看一下什么叫做并发和并行。
并行:同时运行,只有具备多个cpu才能实现并行并发:是伪并行,即看起来是同时运行(时间片轮转法)。- 无论是并行还是并发,在用户看来都是’同时’运行的,不管是进程还是线程,都只是一个任务而已,真实干活的是cpu,而一个cpu同一时刻只能执行一个任务。
举例说明
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持
并发也不支持并行。 - 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持
并发。 - 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持
并行。
总结
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。- 所以它们最关键的点就是:是否是『同时』。
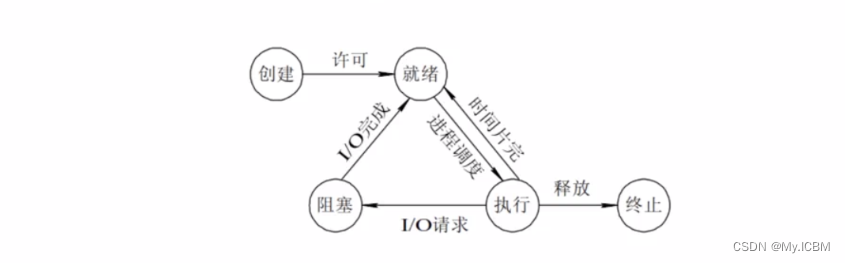
4. 进程的状态
在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行、阻塞和终止。
就绪(Ready)状态
进程已经准备好,已分配到所需资源/内存
执行/运行(Running)状态
进程处于就绪状态被调度后,进程进入执行状态
阻塞(Blocked)状态(耗时操作)
正在执行的进程由于某些事件而暂时无法运行,进程受到阻塞,则进入就绪状态等待系统调用
网络请求,input等
终止状态
进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
5. 同步和异步
同步
CPU在执行一个任务的时候,任务的每一个步骤是顺序执行的,并且必须是每前一个步骤执行完毕后才可以执行下一个步骤,这就是同步的含义。
异步
异步是指,任务的所有步骤也是顺序被执行,但是与同步不同的是,异步的模式下,不会等前一个步骤执行完毕后才会执行下一个步骤,而是当一个步骤一旦被执行,无论该步骤是否被执行结束,都会马上执行下一个步骤。
案例理解
- 以做饭为例:
- 同步方式就是按照步骤依次做,先烧水,然后煮饭,最后炒菜。只有前面的步骤完成后才能进行下一个步骤。在一个步骤未完成的情况下,你不可以干任何事情。
- 异步的方式就是,在烧水且水还没开的情况下,你可以去干其他事,比如刷手机、发邮件等。也就是在等待每个步骤完成的过程中,你可以干其他事,不必傻傻的等下去。
- 该案例中的,烧水、煮饭和炒菜都是一些耗时操作,可以被称为阻塞操作!
- 注意:同步和异步针对是cup在执行任务时遇到阻塞操作时,所产生的不同行为!
思考:异步操作是基于并行的还是基于并发的?
异步可以是基于并行的也可以是基于并发的,但是大部分情况下是基于并发的。
6. 进程的实现 - multiprocessing
multiprocess是python中管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块,提供的子模块非常多。
Process模块
Process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
运行一个py文件就相当于启动了一个进程,这个进程我们称为"主进程"
而在主进程对应的py文件中,可以通过Process模块创建另一个进程,这个进程是基于主进程创建的,因此可以被称为"子进程"
当有了两个进程后,我们其实就可以实现异步机制了!
具体实现过程
- 1.导入模块:
from multiprocessing import Process - 2.基于Process创建一个子进程对象(当前运行的整个py文件表示主进程),然后可以基于target参数将外部的一个函数注册到该子进程中
- 3.基于start()方法启动创建好的子进程
from multiprocessing import Process
def func():
print('我是绑定给子进程的一组任务!')
if __name__ == '__main__':
print('主进程开始执行!')
# 创建一个进程p,给该进程绑定一组任务
p = Process(target=func)
# 启动创建好的进程
p.start()
print('主进程执行结束!')
'''
如何手动给注册在子线程中的函数传递指定的参数?
- 通过args传递参数
'''
from multiprocessing import Process
def func(num1, num2):
print('我是绑定给子进程的一组任务!', num1, num2)
if __name__ == '__main__':
print('主进程开始执行!')
# 创建一个进程p,给该进程绑定一组任务
p = Process(target=func, args=(123, 456))
# 启动创建好的进程
p.start()
print('主进程执行结束!')
7. 使用进程实现同步/异步效果
同步效果
import time
def get_request(url):
print('正在请求网址的数据:', url)
time.sleep(2)
print('请求结束:', url)
if __name__ == "__main__":
start = time.time()
urls = ['www.1.com', 'www.2.com', 'www.3.com']
for url in urls:
get_request(url)
print('总耗时:', time.time() - start)
异步效果(重点)
import time
from multiprocessing import Process
def get_request(url):
print('正在请求网址的数据:', url)
time.sleep(2)
print('请求结束:', url)
if __name__ == "__main__":
urls = ['www.1.com', 'www.2.com', 'www.3.com']
for url in urls:
# 创建了三个进程,表示三组任务
p = Process(target=get_request, args=(url,))
p.start()
Join方法的使用(了解)
'''
join是需要让子进程调用的方法,主进程一定会等待调用了join的子进程结束后,主进程在结束!
'''
import time
from multiprocessing import Process
def get_request(url):
print('正在请求网址的数据:', url)
time.sleep(2)
print('请求结束:', url)
if __name__ == "__main__":
start = time.time()
urls = ['www.1.com', 'www.2.com', 'www.3.com']
p_list = [] # 存储创建好的子进程
for url in urls:
# 创建子进程
p = Process(target=get_request, args=(url,))
p_list.append(p)
# p.join() #一定不要这么写
# 启动子进程
p.start()
for pp in p_list: # pp就是列表中的每一个子进程
pp.join() # 是的每一个子进程都执行了join操作
# 意味着:主进程需要等待所有执行了join操作的子进程结束后再结束
print('总耗时:', time.time() - start)
''' 观察下述代码出现的问题是什么?(了解) '''
from multiprocessing import Process
import time
ticketNum = 10 # 全部的车票
def func(num):
print('我是子进程,我要购买%d张票!' % num)
global ticketNum
ticketNum -= num
time.sleep(2)
if __name__ == '__main__':
p = Process(target=func, args=(3,))
p.start()
# 主进程在子进程结束之后在结束
p.join() # 只有当子进程结束后,join的调用结束,才会执行join后续的操作
print('目前剩余车票数量为:', ticketNum) # 输出结果依然是10
# 进程和进程之间是完全独立。两个进程对应的是两块独立的内存空间,每一个进程只可以访问自己内存空间里的数据。
如果主进程的查询结果是在2s中后才出现的,则join生效了。但是查询结果为什么是这样的呢?
- 首先,ticketNum = 10这个变量是存在于主进程中的,然后再func函数中ticketNum则是将全局变量ticketNum的值拷贝到了子进程中的ticketNum变量中,因此在func中的减法操作只能作用在子进程的变量中。最终,最后一行主进程打印的ticketNum则是原来主进程未发生变量的值。
如何解决?(自己可以尝试文件共享)
- 进程通信机制,管道,信号量等(没必要掌握,日后用不到)
继续思考:一个子进程函数的返回值如何被主进程获取?
总结:进程之间的数据是隔离的,也就是数据不共享
守护进程(了解)
那么如果有一天我们的需求是我的主进程结束了,由主进程创建的那些子进程必须跟着结束,怎么办?守护进程就来了!
import time
from multiprocessing import Process
def get_request(url):
print('正在请求网址的数据:',url)
time.sleep(2)
print('请求结束:',url)
if __name__ == "__main__":
start = time.time()
p = Process(target=get_request,args=('www.1.com',))
# 将当前p这个子进程设置为了守护进程
p.daemon = True #该操作必须放置在子进程启动操作之前
p.start()
print('主进程执行结束')
主进程创建守护进程后:
- 其一:守护进程会在主进程代码执行结束后就终止
- 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:主进程代码运行结束,守护进程随即终止!
三、线程
1. 基本概念
线程是操作系统能够进行运算调度的最小单位(车间里的工人),它被包含在进程之中,线程是进程中的实际运作单位。
注意:
- 1.同一个进程内的多个线程是共享该进程的资源的,不同进程内的线程资源肯定是隔离的
- 2.创建线程的开销比创建进程的开销要小的多
- 3.每一个进程中至少会包含有一个线程,该线程叫做"主线程"
思考:多线程可以实现并行吗?
- 在CPU资源比较充足的时候,一个进程内的多个线程,是可以被分配到不同的CPU上的,这就是通过多线程实现并行。但是这个分配过程是由操作系统实现的,不可人为控制。
2. 线程的实现 - threading
from threading import Thread
def func(num):
print('num的值是:', num)
if __name__ == '__main__':
# 创建好了一个子线程(在主线程中创建)
t = Thread(target=func, args=(1,))
t.start()
Join方法的使用
from threading import Thread
import time
class MyThread(Thread):
def __init__(self):
super().__init__()
def run(self):
print('当前子线程正在执行')
time.sleep(2)
print('当前子线程执行结束')
if __name__ == '__main__':
start = time.time()
ts = []
for i in range(3):
t = MyThread() # 创建线程对象
t.start() # 启动线程对象
ts.append(t)
for t in ts:
t.join()
print('总耗时:', time.time() - start)
线程内存数据共享
from threading import Thread
import time
def work():
global n
n = 0 # 将全局变量修改为了0
if __name__ == '__main__':
n = 1 # 全局变量
t = Thread(target=work)
t.start()
print(n) # 在进程中输出全局变量的值就是线程修改后的结果为0
守护线程
无论是进程还是线程,都遵循:守护xx会在主xx运行完毕后被销毁,不管守护xx时候被执行结束
from threading import Thread
import time
def work():
time.sleep(1)
print('子线程正在执行!')
if __name__ == '__main__':
t = Thread(target=work)
t.daemon = True #当前的子线程设置为了守护线程
t.start()
print('主线程结束!')
多线程实现的异步效果
from multiprocessing.dummy import Pool # 导入了线程池模块
import time
from threading import Thread
start = time.time()
def get_requests(url):
print('正在爬取数据')
time.sleep(2)
print('数据爬取结束')
urls = ['www.1.com', 'www.2.com', 'www.3.com', 'www.4.com', 'www.5.com']
ts = []
for url in urls:
t = Thread(target=get_requests, args=(url,))
t.start()
ts.append(t)
for t in ts:
t.join()
print('总耗时:', time.time() - start)
3. 线程池
线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和系统稳定性。
from multiprocessing.dummy import Pool # 导入了线程池模块
import time
urls = ['www.1.com', 'www.2.com', 'www.3.com', 'www.4.com', 'www.5.com']
def get_reqeust(url):
print('正在请求数据:', url)
time.sleep(2)
print('请求结束:', url)
start = time.time()
# 创建一个线程池,开启了5个线程
pool = Pool(5)
# 可以利用线程池中三个线程不断的去处理5个任务
pool.map(get_reqeust, urls)
# get_reqeust函数调用的次数取决urls列表元素的个数
# get_requests每次执行都会接收urls列表中的一个元素作为参数
print('总耗时:', time.time() - start)
pool.close() # 释放线程池
四、协程(重点)
协程可以实现在单进程或者单线程的模式下,大幅度提升程序的运行效率!
假设我们有一个需求:从一个URL列表中下载多个网页内容,假设下载一个网页内容需要耗时2秒。
- 在传统的多线程或多进程模型中,我们会为每个URL创建一个线程或进程来进行异步的下载操作。但是这样做会有一个问题:
- 计算机中肯定不会只有下载URL的这几个进程/线程,还会有其他的进程/线程(Pycharm、音乐播放器、微信、网盘等)。
- 将每一个下载网页的操作封装成一个进程/线程的目的就是为了实现异步的网页数据下载,也就是当一个下载网页的操作出现阻塞后,可以不必等待阻塞操作结束后就可以让计算机去下载其他网页内容(CPU切换到其他网页下载的进程/线程中)。
- 但是,计算机中启动的进程/线程那么多,你确定每次CPU进行进程/线程切换,都会切换到网页下载的进程/线程中吗?答案是不一定,因为这个进程/线程切换是由操作系统实现的,无法人为干涉。那么,这些网页下载任务的执行的效率就降低下来了。因此,可以使用协程来解决该问题!
- 协程处理多个网页内容下载任务:
- 将所有的网页下载任务全部封装在一个进程/线程中,基于单进程/单线程来实现多个网页下载的任务。
- 在这个下载任务的单进程/单线程,需要我们自己主动监测出所有的阻塞环节,使得cpu在这些阻塞环节切换执行,这样当前下载任务的单进程/单线程处于就绪态就会增多,以此来迷惑操作系统,操作系统便以为当前的下载任务是阻塞比较少的单进程/单线程,从而会尽可能多的分配CPU给我们,这样也就达到了提升程序执行效率的目的。
- 因此,有了协程后,在单进程或者单线程的模式下,就可以大幅度提升程序的运行效率了!
- 总而言之,就是想尽一切办法留住CPU在我们自己的程序中,从而提升整个程序的执行效率!
1. asyncio模块
在python3.6之后新增了asyncio模块,可以帮我们检测阻塞(只能是网络阻塞),实现应用程序级别的切换。
接下来让我们来了解下协程的实现,从 Python 3.6 开始,Python 中加入了协程的概念,但这个版本的协程还是以生成器对象为基础的,在 Python 3.6 则增加了 asyncio,使得协程的实现更加方便。首先我们需要了解下面几个概念:
-
特殊函数:- 在函数定义前添加一个async关键字,则该函数就变为了一个特殊的函数!
- 特殊函数的特殊之处是什么?
- 1.特殊函数被调用后,函数内部的程序语句(函数体)没有被立即执行
- 2.特殊函数被调用后,会返回一个协程对象
-
协程:- 协程对象,特殊函数调用后就可以返回/创建了一个协程对象。
- 协程对象 == 特殊的函数 == 一组指定形式的操作
- 协程对象 == 一组指定形式的操作
-
任务:- 任务对象就是一个高级的协程对象。高级之处,后面讲,不着急!
- 任务对象 == 协程对象 == 一组指定形式的操作
- 任务对象 == 一组指定形式的操作
-
事件循环:- 事件循环对象(Event Loop),可以将其当做是一个容器,该容器是用来装载任务对象的。所以说,让创建好了一个或多个任务对象后,下一步就需要将任务对象全部装载在事件循环对象中。
- 思考:为什么需要将任务对象装载在事件循环对象?
- 当将任务对象装载在事件循环中后,启动事件循环对象,则其内部装载的任务对象对应的相关操作就会被立即执行。
# 特殊函数 :函数 == 一组指定形式的操作(任务),特殊之处就在于该函数在定义前需要使用 async 关键字进行修饰。该函数调用后函数内容的程序没有被立即执行,而是返回一个协程对象。
# 协程对象 :协程 == 特殊的函数 == 一组指定形式的操作
# 任务对象 :高级的协程对象。任务对象 == 协程 == 一组指定形式的操作
# 事件循环
from time import sleep
import asyncio
# 特殊的函数
async def get_requests(url):
print('正在请求数据:', url)
sleep(2)
print('请求结束:', url)
# 该特殊函数会返回一个协程对象
c = get_requests('www.1.com')
print(c) # <coroutine object get_requests at 0x00000218B4488040>
# 创建一个任务对象
task = asyncio.ensure_future(c)
# 如何执行任务
loop = asyncio.get_event_loop() # 创建在一个事件循环对象(某种形式的容器)
loop.run_until_complete(task) # 将任务对象装载在 loop 容器中,并且启动了 loop
# 启动 loop : 会将 loop 内部装载的所有的任务对象进行异步的执行
任务对象对比协程对象的高级之处重点在于:
- 可以给任务对象绑定一个回调函数!
- 回调函数有什么作用?
- 回调函数就是回头调用的函数,因此要这么理解,当任务对象被执行结束后,会立即调用给任务对象绑定的这个回调函数!
import asyncio
import time
# 特殊的函数
async def get_request(url):
print('正在请求的网址是:', url)
time.sleep(2)
print('请求网址结束!')
return 123
# 回调函数的封装:必须有一个参数
def t_callback(t):
# 参数t就是任务对象
# print('回调函数的参数t是:',t)
# print('我是任务对象的回调函数!')
data = t.result() # result()函数就可以返回特殊函数内部的返回值
print('我是任务对象的回调函数!,获取到特殊函数的返回值为:', data)
# 创建协程对象
c = get_request('www.1.com')
# 创建任务对象
task = asyncio.ensure_future(c)
# 给任务对象绑定回调函数:add_done_callback的参数就是回调函数的名字
task.add_done_callback(t_callback)
# 创建事件循环对象
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
多线程的协程
# 可以实现异步的效果?
import asyncio
import time
from time import sleep
urls = ['www.1.com', 'www.2.com', 'www.3.com']
start = time.time()
# 在特殊函数内部不可以出现不支持异步的模块代码
async def get_requests(url):
print('正在请求:', url)
await asyncio.sleep(2)
print('请求结束:', url)
if __name__ == '__main__':
tasks = [] # 存放所有的任务对象
for url in urls:
c = get_requests(url) # 创建了3个协程对象
task = asyncio.ensure_future(c) # 创建3个任务对象
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:', time.time() - start)
- 出现两个问题:
- 1.没有实现异步效果
- 2.wait()是什么意思?
- wait()函数:
- 给任务列表中的每一个任务对象赋予一个可被挂起的权限!当cpu执行的任务对象遇到阻塞操作的时候,当前任务对象就会被挂起,则cup就可以执行其他任务对象,提高整体程序运行的效率!
- 挂起任务对象:让当前正在被执行的任务对象交出cpu的使用权,cup就可以被其他任务组抢占和使用,从而可以执行其他任务组。
- 注意:特殊函数内部,不可以出现不支持异步模块的代码,否则会中断整个异步效果!
- await关键字:挂起发生阻塞操作的任务对象。在任务对象表示的操作中,凡是阻塞操作的前面都必须加上await关键字进行修饰!(人为主动检测阻塞环节)
- 完整的实现了,多任务的异步协程操作
import asyncio
import time
start = time.time()
urls = [
'www.1.com','www.2.com','www.3.com'
]
async def get_request(url):
print('正在请求:',url)
# time.sleep(2) #time模块不支持异步
await asyncio.sleep(2)
print('请求结束:',url)
#有了三个任务对象和一个事件循环对象
if __name__ == '__main__':
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
tasks.append(task)
#将三个任务对象,添加到一个事件循环对象中
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:',time.time()-start)
真正的将多任务的异步协程作用在爬虫中
- 需求:爬取自己服务器中的页面数据,并将其进行数据解析操作
- aiohttp :是一个基于网络请求的模块,功能和requests相似,但是,requests是不支持异步的,而aiohttp是支持异步的模块。
环境安装:pip install aiohttp
1.先写大致加购
with aiohttp.ClientSession() as sess:
#基于请求对象发起请求
#此处的get是发起get请求,常用参数:url,headers,params,proxy
#post方法发起post请求,常用参数:url,headers,data,proxy
#发现处理代理的参数和requests不一样(注意),此处处理代理使用proxy='http://ip:port'
with sess.get(url=url) as response:
page_text = response.text()
#text():获取字符串形式的响应数据
#read():获取二进制形式的响应数据
return page_text
2.在第一步的基础上补充细节
- 在每一个with前加上async关键字
- 在阻塞操作前加上await关键字
- 完整代码:
async def get_request(url):
#requests是不支持异步的模块
# response = await requests.get(url=url)
# page_text = response.text
#创建请求对象(sess)
async with aiohttp.ClientSession() as sess:
#基于请求对象发起请求
#此处的get是发起get请求,常用参数:url,headers,params,proxy
#post方法发起post请求,常用参数:url,headers,data,proxy
#发现处理代理的参数和requests不一样(注意),此处处理代理使用proxy='http://ip:port'
async with await sess.get(url=url) as response:
page_text = await response.text()
#text():获取字符串形式的响应数据
#read():获取二进制形式的响应数据
return page_text
案例 - 多任务异步爬虫的完整代码
实验环境搭建
# 创建一个Server.py文件,表示服务器程序
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from flask import Flask,render_template
from time import sleep
#安装flask模块
#1.实例化app对象
app = Flask(__name__)
@app.route('/main')
def main():
return 'i am main'
@app.route('/bobo')
def index1():
sleep(2)
return render_template('test.html')
@app.route('/jay')
def index2():
sleep(2)
return render_template('test.html')
@app.route('/tom')
def index3():
sleep(2)
return render_template('test.html')
if __name__ == "__main__":
app.run()
爬虫程序
import requests
import asyncio
import time
from lxml import etree
import aiohttp
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
#该任务是用来对指定url发起请求,获取响应数据
async def get_request(url):
#requests是不支持异步的模块
# response = await requests.get(url=url)
# page_text = response.text
#创建请求对象(sess)
async with aiohttp.ClientSession() as sess:
#基于请求对象发起请求
#此处的get是发起get请求,常用参数:url,headers,params,proxy
#post方法发起post请求,常用参数:url,headers,data,proxy
#发现处理代理的参数和requests不一样(注意),此处处理代理使用proxy='http://ip:port'
async with await sess.get(url=url) as response:
page_text = await response.text()
#text():获取字符串形式的响应数据
#read():获取二进制形式的响应数据
return page_text
def parse(t):#回调函数专门用于数据解析
#获取任务对象请求到的页面源码数据
page_text = t.result()
tree = etree.HTML(page_text)
a = tree.xpath('//a[@id="feng"]/@href')[0]
print(a)
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
task.add_done_callback(parse)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:',time.time()-start)
五、异步爬虫具体应用
注意:通常,异步操作主要作用在耗时环节
案例 - 同步操作
# url : https://www.doutuwang.com/tag/今天/page/2
import requests
from lxml import etree
import os
dirName = '同步数据imgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
for page in range(1, 2):
url = 'https://www.doutuwang.com/tag/今天/page/' + str(page)
page_text = requests.get(url, headers=headers).text
tree = etree.HTML(page_text)
lists = tree.xpath('//*[@id="post_container"]/div/li')
for list in lists:
# 图片是滑动滚轮后单独加载出来的(图片懒加载)
img_src = list.xpath('./div[@class="thumbnail"]/a/img/@src')[0]
img_title = img_src.split('/')[-1]
img_path = dirName + '/' + img_title
img_data = requests.get(img_src, headers=headers).content
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_title, ':爬取保存成功!')
案例 - 多线程爬取斗图
# url : https://www.doutuwang.com/tag/今天/page/2
import requests
from lxml import etree
import os
from threading import Thread # 多线程模块
import time
dirName = '多线程数据imgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 对一张图片数据进行加载
def get_img_data(url, title):
print('正在请求', title)
img_data = requests.get(url=url, headers=headers).content
img_path = dirName + '/' + title
with open(img_path, 'wb') as fp:
fp.write(img_data)
if __name__ == '__main__':
url = 'https://www.doutuwang.com/tag/今天/page/'
start = time.time()
for page in range(1, 3):
new_url = url + str(page)
page_text = requests.get(url=new_url, headers=headers).text
tree = etree.HTML(page_text)
lists = tree.xpath('//*[@id="post_container"]/div/li')
for list in lists:
# 图片是滑动滚轮后单独加载出来的(图片懒加载)
img_src = list.xpath('./div[@class="thumbnail"]/a/img/@src')[0]
img_title = img_src.split('/')[-1]
# 图片下载就可以基于多线程来实现
thread = Thread(target=get_img_data, args=(img_src, img_title))
thread.start()
print('总耗时:', time.time() - start)
案例 - 协程爬取斗图
# url : https://www.doutuwang.com/tag/今天/page/2
import asyncio
import aiohttp
import requests
from lxml import etree
import os
import time
dirName = '协程数据imgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
async def get_img_data(dic):
img_src = dic['img_src']
title = dic['img_title']
async with aiohttp.ClientSession() as req:
async with await req.get(img_src, headers=headers) as response:
img_data = await response.read()
return [img_data, title]
def saveImgData(x):
data_list = x.result()
img_data = data_list[0]
title = data_list[1]
img_page = dirName + '/' + title
with open(img_page, 'wb') as fp:
fp.write(img_data)
print(title, ':下载保存成功')
if __name__ == '__main__':
all_img_data = []
url = 'https://www.doutuwang.com/tag/今天/page/'
start = time.time()
for page in range(1, 3):
new_url = url + str(page)
page_text = requests.get(url=new_url, headers=headers).text
tree = etree.HTML(page_text)
lists = tree.xpath('//*[@id="post_container"]/div/li')
for list in lists:
# 图片是滑动滚轮后单独加载出来的(图片懒加载)
img_src = list.xpath('./div[@class="thumbnail"]/a/img/@src')[0]
img_title = img_src.split('/')[-1]
dic = {
'img_src': img_src,
'img_title': img_title,
}
all_img_data.append(dic)
# 对每一页的图片数据进行网络请求(协程)
tasks = []
for dic in all_img_data:
c = get_img_data(dic)
task = asyncio.ensure_future(c)
task.add_done_callback(saveImgData)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:', time.time() - start)
# 思路:300页数据(1页有100张图片)
# 使用一个线程(1页数据的爬取) 需要创建300个线程异步对300页的图片进行下载
# 每一个线程中创建100个协程
六、M3U8流视频数据爬虫(不重要)
1. HLS技术介绍
现在大部分视频客户端都采用HTTP Live Streaming(HLS,Apple为了提高流播效率开发的技术),而不是直接播放MP4等视频文件。HLS技术的特点是将流媒体切分为若干【TS片段】(比如几秒一段),然后通过一个【M3U8列表文件】将这些TS片段批量下载供客户端播放器实现实时流式播放。因此,在爬取HLS的流媒体文件的思路一般是先【下载M3U8文件】并分析其中内容,然后在批量下载文件中定义的【TS片段】,最后将其【组合】成mp4文件或者直接保存TS片段。
2. M3U8文件详解
如果想要爬取HLS技术下的资源数据,首先要对M3U8的数据结构和字段定义非常了解。M3U8是一个扩展文件格式,由M3U扩展而来。那么什么事M3U呢?
M3U文件
-
M3U这种文件格式,本质上说不是音频视频文件,它是音频视频文件的列表文件,是纯文本文件。
-
M3U这种文件被获取后,播放软件并不是播放它,而是根据它的记录找到媒体的网络地址进行在线播放。也就是说,M3U格式的文件只是存储多媒体播放列表,并提供了一个指向其他位置的音频视频文件的索引,播放的是那些被指向的文件。
-
为了能够更好的理解M3U的概念,我们先简单做一个M3U文件(myTest.m3u)。在电脑中随便找几个MP3,MP4文件依次输入这些文件的路径,myTest.m3u文件内容如下
E:\Users\m3u8\刘德华 - 无间道.mp4
E:\Users\m3u8\那英 - 默.mp3
E:\Users\m3u8\周杰伦 - 不能说的秘密.mp4
E:\Users\m3u8\花粥 - 二十岁的某一天.mp3
E:\Users\m3u8\周深 - 大鱼.mp4
M3U8文件
-
M3U8也是一种M3U的扩展格式(高级的M3U,所以也属于M3U)。
-
M3U8示例:大家会看到在该文件中有大量的ts文件的链接地址,这个就是我们之前描述的真正的视频文件。其中任何一个ts文件都是一小段视频,可以单独播放。我们做视频爬虫的目标就是把这些ts文件都爬取下来。
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:6
#EXT-X-PLAYLIST-TYPE:VOD
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:3.127,
/20230512/RzGw5hDB/1500kb/hls/YZefAiEF.ts
#EXTINF:3.127,
/20230512/RzGw5hDB/1500kb/hls/FsliUCL6.ts
#EXTINF:3.127,
/20230512/RzGw5hDB/1500kb/hls/DD7c47bz.ts
#EXT-X-ENDLIST
实战案例练习
需求网址:https://www.suoshen.cc/
具体操作 - 同步操作代码
# url : https://www.suoshen.cc/vp-54caq/1056321-1.html
import requests
import re
import os
import asyncio
import aiohttp
dirName = 'tsLib'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
first_url = 'https://vod.hw8.live/m3u8/9770b31cf60fcf8b94ac2d26cba25d13'
# 请求二级文件地址内容
m2_page_text = requests.get(url=first_url, headers=headers).text.strip()
# 解析出每一个ts切片的地址
ts_url_list = []
for line in m2_page_text.split('\n'):
if not line.startswith('#'): # 如果不是以 # 开头就获取
ts_url_list.append(line)
print(ts_url_list)
# 写同步代码进行 ts 片段网络请求
for ts_url in ts_url_list:
ts_data = requests.get(url=ts_url, headers=headers).content
ts_title = ts_url.split('/')[-1]
ts_path = dirName + '/' + ts_title
with open(ts_path, 'wb') as fp:
fp.write(ts_data)
print(ts_title, '爬取下来成功!!')
具体操作 - 异步操作代码
import requests
import re
import os
import asyncio
import aiohttp
from aiohttp import TCPConnector
dirName = '碟中谍7'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
first_url = 'https://vod.hw8.live/m3u8/9770b31cf60fcf8b94ac2d26cba25d13'
# 请求二级文件地址内容
m2_page_text = requests.get(url=first_url, headers=headers).text.strip()
# 解析出每一个ts切片的地址
ts_url_list = []
for line in m2_page_text.split('\n'):
if not line.startswith('#'): # 如果不是以 # 开头就获取
ts_url_list.append(line)
print(ts_url_list)
# 协程
async def get_ts_data(url, sem): # 用来对一个 ts 片段进行网络请求下载
while True:
try:
async with sem:
async with aiohttp.ClientSession(trust_env=True) as req:
async with req.get(url, headers=headers, ssl=False) as response:
ts_data = await response.read()
ts_title = url.split('/')[-1]
return {
'ts_title': ts_title,
'ts_data': ts_data,
}
except:
print("--下载失败重新下载--")
def saveTsDta(x):
ret = x.result()
ts_title = ret['ts_title']
ts_data = ret['ts_data']
ts_path = dirName + '/' + ts_title
with open(ts_path, 'wb') as fp:
fp.write(ts_data)
print(ts_title, '爬取下来成功!!')
# tasks = []
# # # 创建协程
# _sem = asyncio.Semaphore(100)
# for ts_url in ts_url_list:
# c = get_ts_data(ts_url,_sem)
# task = asyncio.ensure_future(c)
# task.add_done_callback(saveTsDta) # 回调函数
# tasks.append(task)
async def main():
tasks = []
_sem = asyncio.Semaphore(100)
for ts_url in ts_url_list:
c = get_ts_data(ts_url, _sem)
task = asyncio.create_task(c)
task.add_done_callback(saveTsDta) # 回调函数
tasks.append(task)
await asyncio.gather(*tasks)
# loop = asyncio.get_event_loop()
# loop.run_until_complete(asyncio.wait(tasks))
asyncio.run(main())
# # 写同步代码进行 ts 片段网络请求
# for ts_url in ts_url_list:
# ts_data = requests.get(url=ts_url, headers=headers).content
# ts_title = ts_url.split('/')[-1]
# ts_path = dirName + '/' + ts_title
#
# with open(ts_path, 'wb') as fp:
# fp.write(ts_data)
# print(ts_title, '爬取下来成功!!')
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql使用load data导入数据
- Go配置镜像源
- AI动作冒险电影《角斗士2:破晓之争》(上)
- 视频剪辑技巧:制作视频画中画效果,背景图片的选取与运用
- 洗地机、扫地机器人和吸尘器哪个好?三选一谁更值得买?
- 微短剧,会成为长视频的“救命稻草”吗?
- Linux———head命令详解
- 【Leetcode 5】最长回文字串 —— 动态规划
- jQuery —— ajaxForm和ajaxSubmit的用法与区别
- 零基础学习8051单片机(五)