Bytetrack学习笔记
概述
ByteTrack是字节跳动发布的一个MOT跟踪算法(“MOT”是“Multi-Object Tracking”)。先前的MOT算法一般在完成当前帧的目标检测后只会保留置信度比较大的检测框用于进行目标跟踪,比如图中置信度为0.9和0.8的目标框。而在BYTE中,作者保留了所有的检测框(图中的所有四个黄色的检测框)并且通过阈值将它们分成了两份
ByteTrack 是基于 tracking-by-detection 范式(首先使用一个深度学习网络(如YOLO系列)进行目标检测,然后使用一个关联算法(如卡尔曼滤波和匈牙利算法)来建立目标之间的关联,从而实现目标的跟踪)的跟踪方法。ByteTrack中用多次匹配的方法,首先将得分较高的目标框与历史轨迹相匹配,然后将得分较低的目标框与与第一次没有匹配上的轨迹匹配,用于检测目标遮挡的情形。相对于deepsort,直接减少了ReID模型,更加方便移动端的部署。
缺点:由于ByteTrack 没有采用外表特征进行匹配,所以跟踪的效果非常依赖检测的效果,也就是说如果检测器的效果很好,跟踪也会取得不错的效果,但是如果检测的效果不好,那么会严重影响跟踪的效果。
为什么没有使用ReID 特征? 作者解释:第一点是为了尽可能做到简单高速,第二点是我们发现在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高,能够代替 ReID 进行物体间的长时刻关联。实验中也发现加入 ReID 对跟踪结果没有提升。
算法原理
ByteTrack的工作原理是遮挡往往随着检测得分由高到低的缓慢降低,被遮挡物体在被遮挡之前是可视物体,检测分数较高,建立轨迹;当物体被遮挡时,通过检测框与轨迹的位置重合度就能把遮挡的物体从低分框中挖掘出来,保持轨迹的连续性
跟踪步骤流程:
-
对于所有由检测器得到检测框信息,将他们分为两部分,检测得分高于阈值Thigh的归类为Dhigh,检测得分低于阈值Tlow归为Dlow;
-
对于轨迹集合T中的所有轨迹,利用KF预测其在当前帧中的坐标
-
第一次匹配:对得分高的检测框Dhigh和所有轨迹T进行匹配关联,计算(当前帧中检测)框与(轨迹T进行KF滤波在当前帧中位置)两者进行iou计算,然后用匈牙利算法进行匹配;对于IOU小于0.2的拒绝匹配,未匹配的检测框存放在Dremain;未匹配成功的轨迹T,存放于Tremain
-
第二次匹配:对于低得分的检测框Dlow(例如在当前帧受到严重遮挡导致得分下降的物体)和剩余轨迹Tremain进行二次匹配,方法同第一次匹配
两次均未匹配成功的轨迹存放于Tre-remain,未匹配的低分检测框删除
-
对于Tre-remain中的轨迹,认为是暂时丢失目标,将其放入Tcost,如果Tcost中的轨迹存在超过一定时间(30帧)则从T中删除,否则继续保存。(如果后期匹配到,也会从Tcost中删除,对于Dremain中检测如果得分高于E,且存活超过两帧,则初始化为新的轨迹)。
下面是第一次匹配的可视化图
 下面是第二次匹配的可视化图
下面是第二次匹配的可视化图
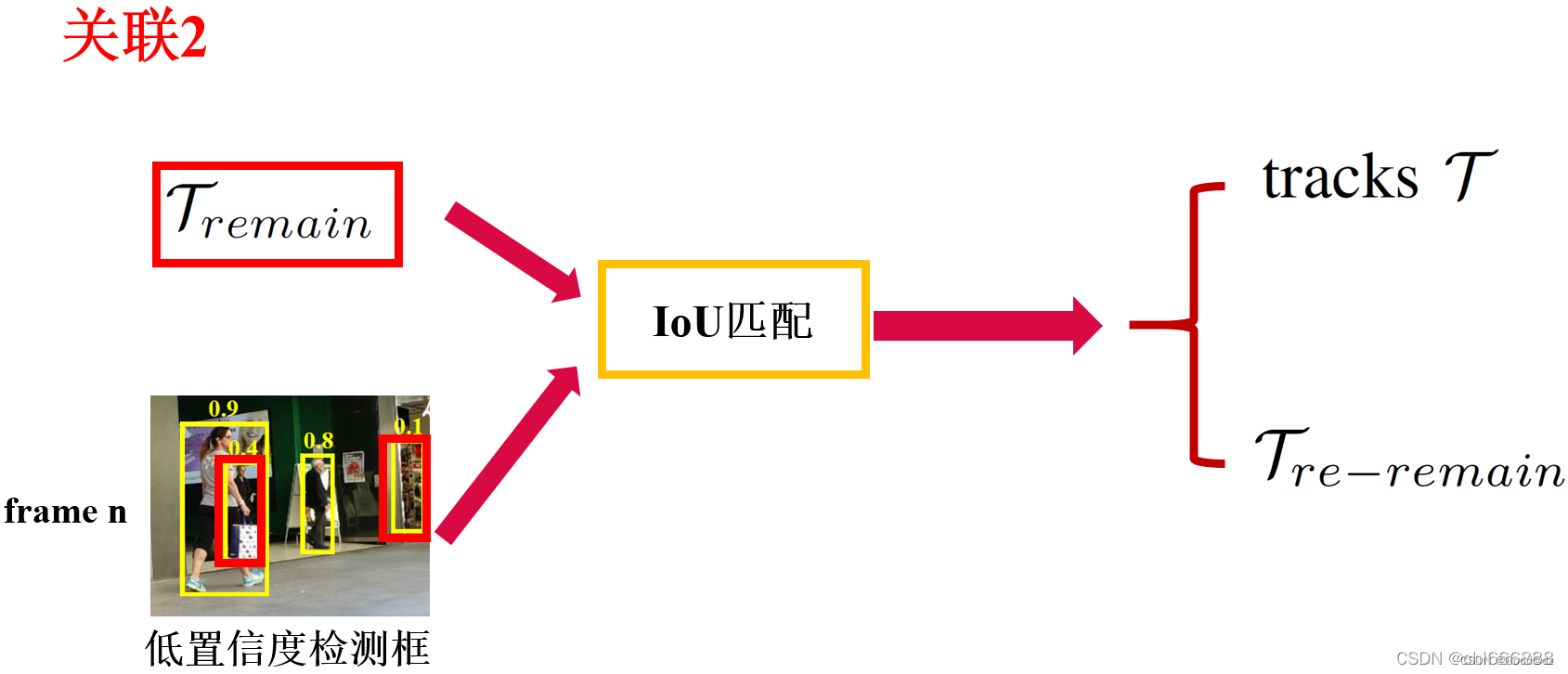
作者表示,对于低置信度的检测框,由于目标往往处于严重遮挡和严重运动模糊的状态,所以外观相似度特征(比如ReID)非常不可靠,而相比较而言IoU匹配是更佳的选择,鉴于此,在关联2中,作者仅仅只使用了IoU,而并未引入外观相似度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法与数据结构--有向图以及拓扑排序
- 异常处理与CrashRpt工具——(3)
- OpenGPTs:一款外挂般的GPTs管理器,由ChatPaper团队开源!
- GBASE南大通用GBase 8a 安装部署
- 掌握Web、DNS、FTP、DHCP服务器的配置。掌握简单网络方案的规划和设计
- 计算机网络基础:Internet/局域网/信息安全/网络安全
- redis夯实之路-集群详解
- el-table固定列偶发拖拽出现边框消失的问题
- Kubernetes增加master节点
- 【cucumber】CucumberOptions详解