【AIGC-文本/图片生成视频系列-10】SparseCtrl:在文本生成视频的扩散模型中添加稀疏控制
目录
由于扩散模型生成空间的不确定性,仅仅通过文本生成视频时,会导致模糊的视频帧生成。
今天解析的SparseCtrl,是一种有效解决上述问题的方案,通过带有附加编码器的时间稀疏条件图来控制文本到视频的生成。
一. 项目概述
已有解决方案:
目前学术界利用密集结构信号(例如每帧深度/边缘序列)来增强可控性,但其收集相应地增加了推理负担。
提出的SparseCtrl:
-
实现对时间稀疏信号的灵活结构控制,仅需要一个或几个输入。
-
它包含一个额外的条件编码器来处理这些稀疏信号,同时保持预训练的 T2V 模型不变。
-
所提出的方法与各种模式兼容,包括草图、深度和 RGB 图像,为视频生成提供更实用的控制,并促进故事板、深度渲染、关键帧动画和插值等应用。
-
大量实验证明了 SparseCtrl 在原始和个性化 T2V 生成器上的泛化能力。

二.?方法详解
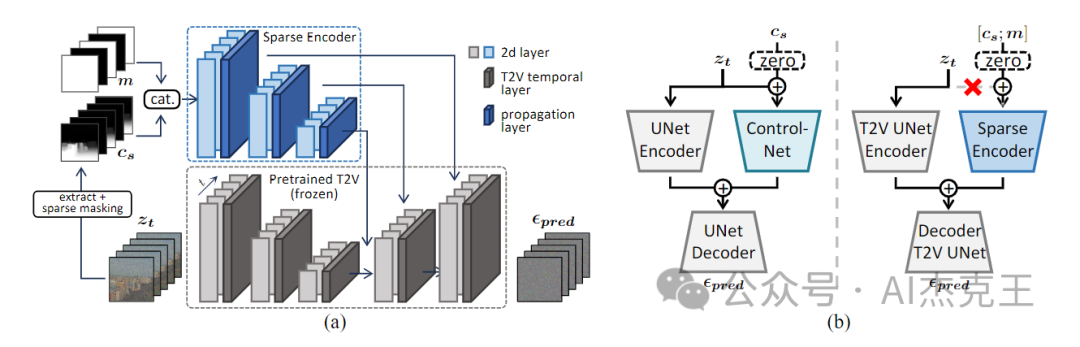
(a)SparseCtrl管线概述。(b)vanilla ControlNet(左),?SparseCtrl的稀疏条件编码器(右)之间的比较
在SparseCtrl管线中,主要由两部分网络结构组成:
-
预训练的T2V主干网络,处于冻结状态;
-
附加的稀疏编码器。
这里需要着重解析的是Sparse Encoder,?和原生的ControlNet只考虑单帧的情况不同,Sparse Encoder 考虑了输入的稀疏性和时序性,加入了T2V时间层(这里的时间层就是带有位置编码的时序attention)。由此,稀疏条件编码器可以使条件信号从帧传播到帧,保证了生产视频的一致性。
原生的ControlNet和Sparse encoder中的差别在于:
-
原生ControlNet不仅拷贝了Unet 的编码器,还拷贝了输入的噪声样本。输入的条件和输入的噪声样本进行sum 操作后再进入ControlNet网络。这样的设计保证了模型训练的稳定以及加速收敛。
-
在Sparse Ctrl中,如果沿用原生ControlNet的设置,那么对于无条件帧而言,Sparse encoder的输入变为仅噪声样本。但这可能会鼓励Sparse encoder忽略条件输入并在训练过程中依赖噪声样本zt,这与我们可控性增强的目标相矛盾。因此SparseCtrl提出的稀疏编码器消除了噪声样本输入,只接受条件和掩码图的组合输入。
三. 应用结果
SparseCtrl可以应用于图像动画,关键帧插值,视频插值,视频预测,深度图引导生成,素描生成视频,故事板生成等领域。




四.个人思考
总体而言,SparseCtrl还是给人带来很多启发的。只用稀疏的控制信号就可以实现以往连续控制信号才可以做到的事,生成效果不错的同时也比较符合现实应用。毕竟为了生成一个视频,我们不可能都预先准备好逐帧的控制信号图,这个太不现实。依靠一两帧控制图就可以生成视频比较符合现实操作环境。
欢迎加入AI杰克王的免费知识星球,海量干货等着你,一起探讨学习AIGC!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Array Equalizer(莫比乌斯反演)
- OpenCV——多分辨率LBP的计算方法
- CCF-CSP202312-2因子化简
- sklearn 中皮尔森相关性。
- 【快速全面掌握 WAMPServer】01.初次见面,请多关照
- 基于AT89C52单片机的计算器设计与仿真
- TS 36.211 V12.0.0-上行(4)-参考信号
- 华为云-对象存储服务(OBS)
- git 使用场景 --amend 提交
- 任务5:安装并配置Hadoop