Redis 击穿、穿透、雪崩产生原因解决思路
大家都知道,计算机的瓶颈之一就是IO,为了解决内存与磁盘速度不匹配的问题,产生了缓存,将一些热点数据放在内存中,随用随取,降低连接到数据库的请求链接,避免数据库挂掉。需要注意的是,无论是击穿还是后面谈到的穿透与雪崩,都是在高并发前提下,比如当缓存中某一个热点key失效。
-? ? ?问题起因? ? -
有两个主要原因:
1、Key过期;
2、Key被页面置换淘汰。
对于第一个原因是因为在Redis中,Key有过期时间,如果某一个时刻(假如商城做活动,零点开始)key失效,那么零点之后对某一个商品查询请求将全都压到数据库上,导致数据库崩。
对于第二个原因,因为内存是有限的,要时时刻刻缓存新的数据,淘汰旧的数据,所以在一定的页面置换策略(常见页面置换算法图解)中,淘汰数据,如果某些商品做活动之前无人问津,势必会被淘汰。
-? ? ?应对击穿的处理思路? ? -
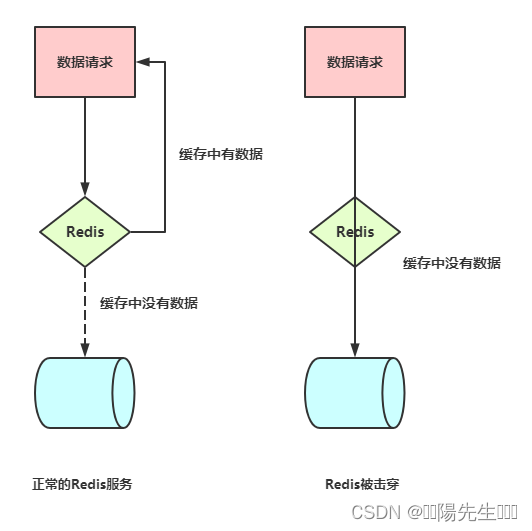
正常的处理请求如图:
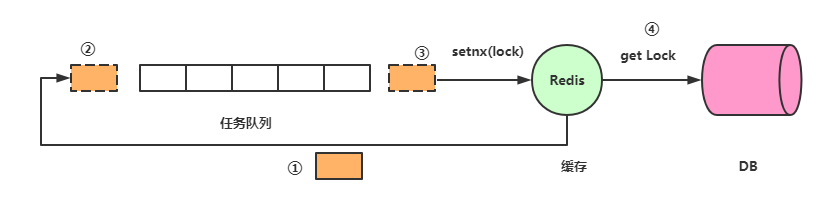
由于key过期在所难免,高流量来到Redis时,根据Redis的单线程特性,可以认为任务是在队列里依次执行的,当请求到达Redis发现Key过期时,进行一个操作:设置锁。
这个流程大概如下:
-
请求到达Redis,发现Redis Key过期,查看有没有锁,没有锁的话回到队列后面排队
-
设置锁,注意,这儿应该是setnx(),而不是set(),因为可能有其他线程已经设置锁了
-
获取锁,拿到锁了就去数据库取数据,请求返回后释放锁。
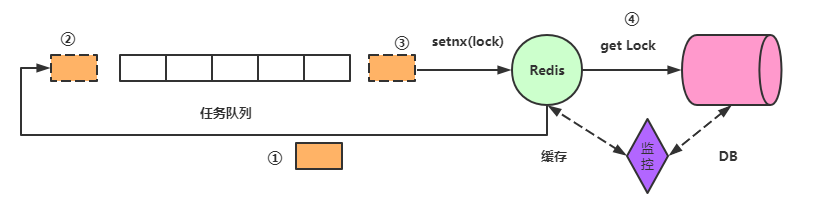
但是引出了一个新的问题,如果拿到锁去拿数据的请求然后挂了怎么办?也就是锁没有释放,其他进程都在等锁,解决办法是:
对锁设置一个过期时间,如果到达了过期时间还没释放就自动释放,问题又来了,锁挂了好说,但是如果是锁超时呢?也就是在设定的时间里数据没有取出来,但是锁由过期了,常见的思路是,锁过期时间值递增,但是想想不靠谱,因为第一个请求可能超时,如果后面的也超时呢,接连多次超时之后,锁过期时间值势必特别大了,这样做弊端太多。
另外一个思路是,再开启一个线程,进行监控,如果取数据的线程没有挂的话,就适当延迟锁的过期时间。
-? ? ?穿透? ? -
穿透主要原因是很多请求都在访问数据库不存在的数据,例如一个卖书的商城一直被请求查询茶叶产品,由于Redis缓存主要是用来缓存热点数据,对于数据库都不存在的数据,是没法缓存的,这种异常流量就会直接到达数据库并且返回"没有"的查询结果。
应对这种请求,处理办法是对访问请求加一层过滤器,例如布隆过滤器、增强版布隆过滤器、布谷鸟过滤器,详情见:Redis布隆过滤器与布谷鸟过滤器。
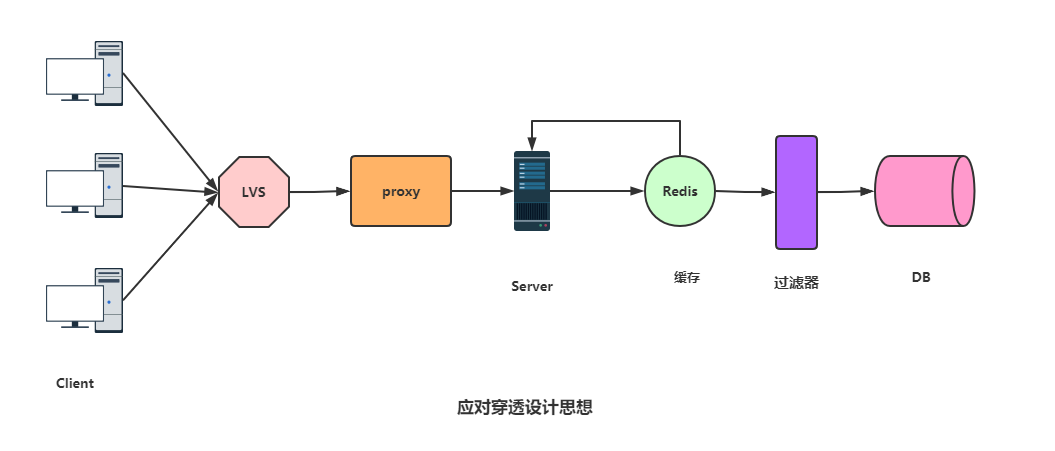
除了布隆过滤器,可以增加一些参数检验,例如数据库数据id一般都是递增的,如果请求 id = -10 这种参数,势必绕过Redis,避免这种情况,可以对用户真实性检验等操作。
-? ? ?雪崩?? ?-
雪崩,和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效,网络上很多博客都在强调解决雪崩的策略是随机过期时间,这个非常不准确,举个例子,银行做活动,之前这个利息系数为2%,过了零点系数改为3%,这种情况能将用户的对应的key改为随机过期吗?如果用的过去的数据叫脏数据。
明显不可以,同样存钱,你存到年底利息300万,隔壁才200万,这不得打架啊,开玩笑~
正确的思路是,首先要看看这个Key过期是不是时点性有关,时点性无关的话,可以随机过期时间解决。
如果是时点性有关,例如刚刚说的银行某一天改变某系数,那么就要利用强依赖击穿方案,策略是先过去的线程更新一下所有key。
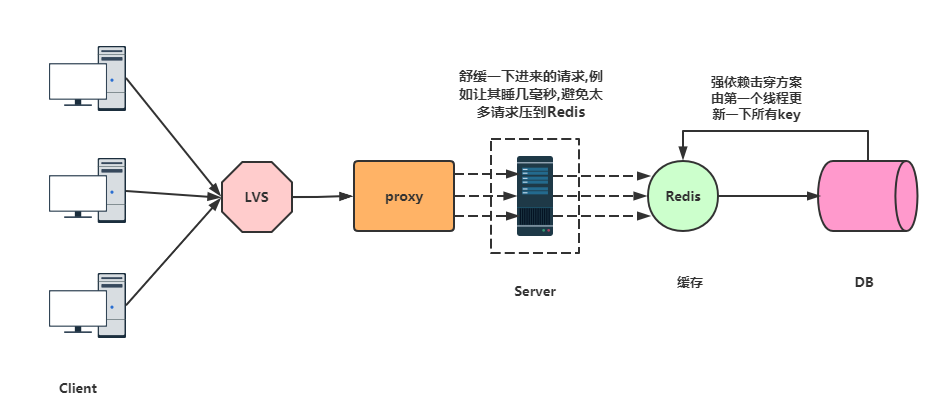
在后台更新热点key的同时,业务层将进来的请求延时一下,例如短暂的睡几毫秒或者秒,给后面的更新热点key分散压力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【CASS精品教程】CASS11坐标换带方法(单点计算、批量计算)
- SearchWP WordPress高级网站内容搜索插件
- python统计分析——多变量描述统计
- 【总结】Linux命令中文帮助手册
- 第十五讲_css水平垂直居中的技巧
- 易点易动设备管理系统:延长设备使用寿命的利器
- 题目 2780: 奇偶数判断
- 鸿蒙(HarmonyOS)项目方舟框架(ArkUI)更改应用图标
- LP-AM243x EtherNet/IP 连接施耐德 M241 EIP主站测试
- adb、monkey的下载和安装