请你来了解一下Mysql-InnoDB中事务的两段式提交
欢迎订阅专栏,了解更多Mysql的硬核知识点,原创不易,求打赏
ACID:事务的四个特性
A:原子性
原子性表示把一个事务中所有的操作视为一个整体,要么全部成功,要么全部失败,是事务模型区别文件系统的重要特征之一
C:一致性
官方对一致性的解释为事务将数据库从一种状态转变为下一种一致性状态,在事务开始之前和食物结束以后,数据库的完整性约束没有被破坏。
而我对一致性的理解为事务的执行可以让各方在指定规则下都认可这个事务产生的变更。比如事务提交后将数据写入binlog,事务提交后redo会写入prepare,commit状态的数据,undo会维护该版本的数据,数据写入(聚集,非聚集)索引表等等。
就好像DDD中的限界上下文一样,大家对于这个领域的边界有共同且明确的认知
InnoDB事务的两段式提交中,主要就是对原子性和一致性的保证。
I:隔离性
隔离性基本的理解是事务之间不会互相干扰。但这是结果。通过什么方式可以使得事务的执行不会互相干扰呢?
如果数据库只允许串行化执行事务,那么就没有隔离性什么事,但是现在的社会,连人类都得加班,互卷,为了让自己的业绩,考核能够更好。对于数据库来说,不可能让一个数据库慢慢悠悠的执行事务,支持并发事务执行是必须的也是基本的职能(功能)。
因此系统必须支持事务的并发执行,事务的并发执行为了保证“线程安全”,必须通过一些手段让其操作在一定的限界内,不能让它们逾越法则。
所以就有了并发控制,锁的出现,通过并发控制,可以让相应的可读数据划分边界,对于不可读的内容做了屏蔽。通过锁,可以让对于同样数据的多个并发修改得以强制性串行执行。
D:持久性
需要注意的是持久性并不能保证机器物理级别的损坏(包括很多方便)或者山崩地裂导致服务器沉入大海后还要做数据恢复。针对这种情况还需要一些高可用的架构来辅助完成。
持久性保证的除了上面说的几种情况外,只要事务单方面确认提交了,那么就能够通过一些手段来恢复。
事务提交的过程图
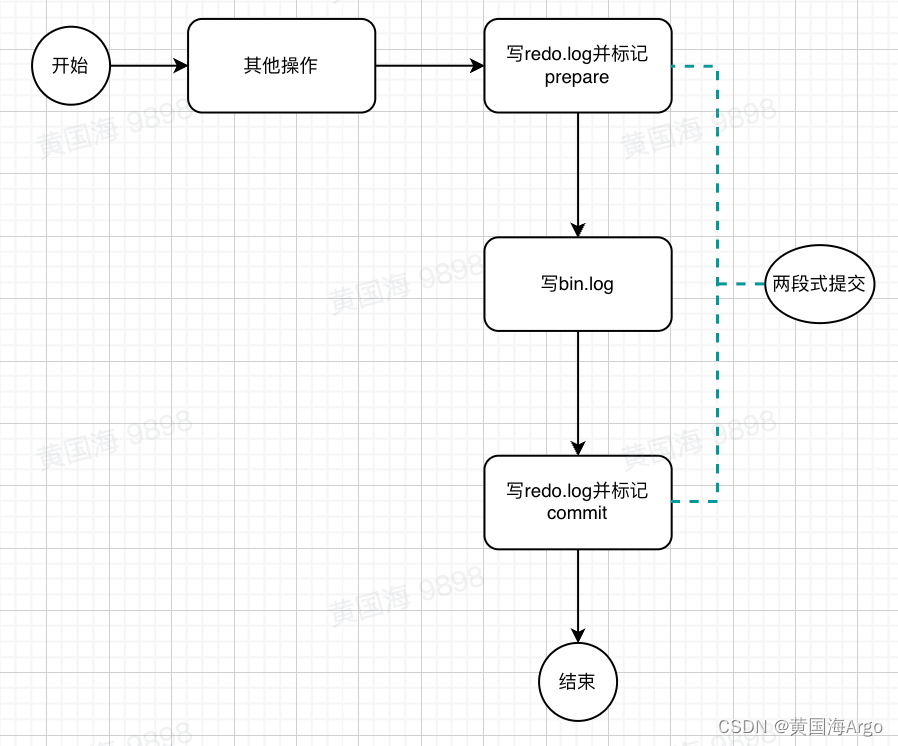
过程解释
其两段式提交主要就是在redo.log的两次prepare状态和commit状态。但是记住,并不是只有最后commit状态写入了才能恢复。
假如redo.log中写入了prepare状态的数据,并且bin.log也写入了。但是写redo.log的commit状态的数据时丢失了,这时候还是可以恢复的。(那为什么不能只根据bin.log是否写入来判断事务成功,为什么还要有一个redo.log来增加复杂度呢?)
因为bin.log太大了,如果系统恢复是通过bin.log来恢复,首先功能是没问题的,但是恢复的时间会很长。而redo.log很小啊(默认情况下只有48M),只需要遍历redo.log里面的数据,如果是commit状态的那么直接恢复。如果是prepare状态的,那么看一下bin.log有没有,有就恢复,没有就不恢复。
事务执行的效率
事务执行的效率除了受限于事务的大小等因素以外,还受限于磁盘的性能,为什么这么说呢?
因为默认情况下,每次都必须等到数据写入磁盘才表示事务提交成功,要不然中间如果出现问题,导致数据并没有写入redo.log或者bin.log,直接返回状态,那么必然有数据不一致性问题。
innodb控制这个过程是通过innodb_flush_log_at_trx_commit参数控制的。
0:每次事务提交的内容不写入文件,而是由master thread进行。master thread中每秒都会执行一次fsync操作
1(默认值):每次事务提交的内容必须执行一次fsync刷到磁盘,才会标记事务为成功。
2:每次事务提交的内容只写入文件系统的缓存,不进行fsync操作。
文件系统的缓存中数据写入文件几乎依赖的是操作系统的一些机制了
脏数据回写策略:当文件系统缓存中的数据被修改后,会被标记为"脏"数据(dirty data)。文件系统会定期或在内存压力紧张的情况下(内核调度策略),将这些"脏"数据异步写入文件。
超过内核参数设置的阈值:Linux内核有一些参数可以控制文件系统的回写行为,例如
dirty_ratio和dirty_background_ratio。当"脏"数据占用内存的比例超过dirty_ratio或超过dirty_background_ratio时,内核会触发异步回写操作。内核定期回写:内核中有一个脏数据回写线程 (
pdflush?或?bdflush),它会定期(默认30秒)检查文件系统的缓存,将脏数据异步写入文件。
需要注意的是master thread执行fsync是固定有的功能,和事务本身的fsync并不互斥的。也就是说有时候不等本事物执行fsync,就已经让master执行了,并且master thread是每个表空间特有的线程,因此如果某个表有单独的表空间,那么其事务提交就完全靠它自己了
无论是0还是2,都不具备事务特性中的一致性,因为数据的提交变的不可预知。
bin.log和redo.log的数据顺序一致吗?
那有一个问题了,bin.log和redo.log的写入顺序是不是就是一致的呢?是不是下面的这种呢
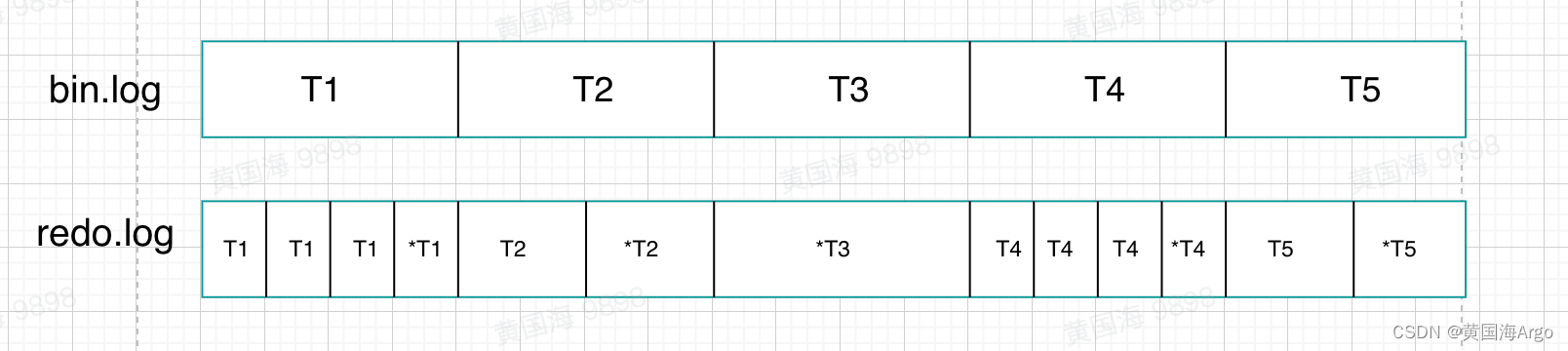
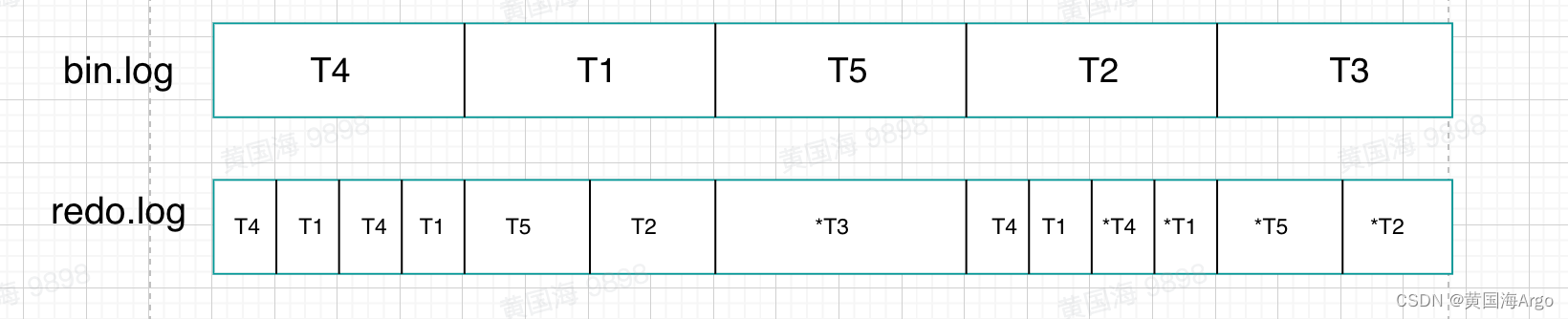
其实并不是,因为bin.log的写入是在事务完成后一次性写入的,而redo.log可能在事务执行过程中不断地写入
有可能是下面的这种顺序
bin.log和redo.log 的数据格式一样吗??
bin.log全程是binary log,记录的是对应的sql语句,是一个二进制文件。
redo.log是一个物理格式数据,记录的是对每一个页的修改
延伸
redo.log的结构
redo.log的大小默认是48M,并且是由一个个redo log block组成的。一个redo log block的大小是512字节,所以默认情况下总有48MB / 512B = 98304个redo log block。
有没有发现redo log block的512字节的大小和磁盘扇区的大小是一样的,所以对于redo log block来说是可以保证原子性的,不需要doublewrite技术
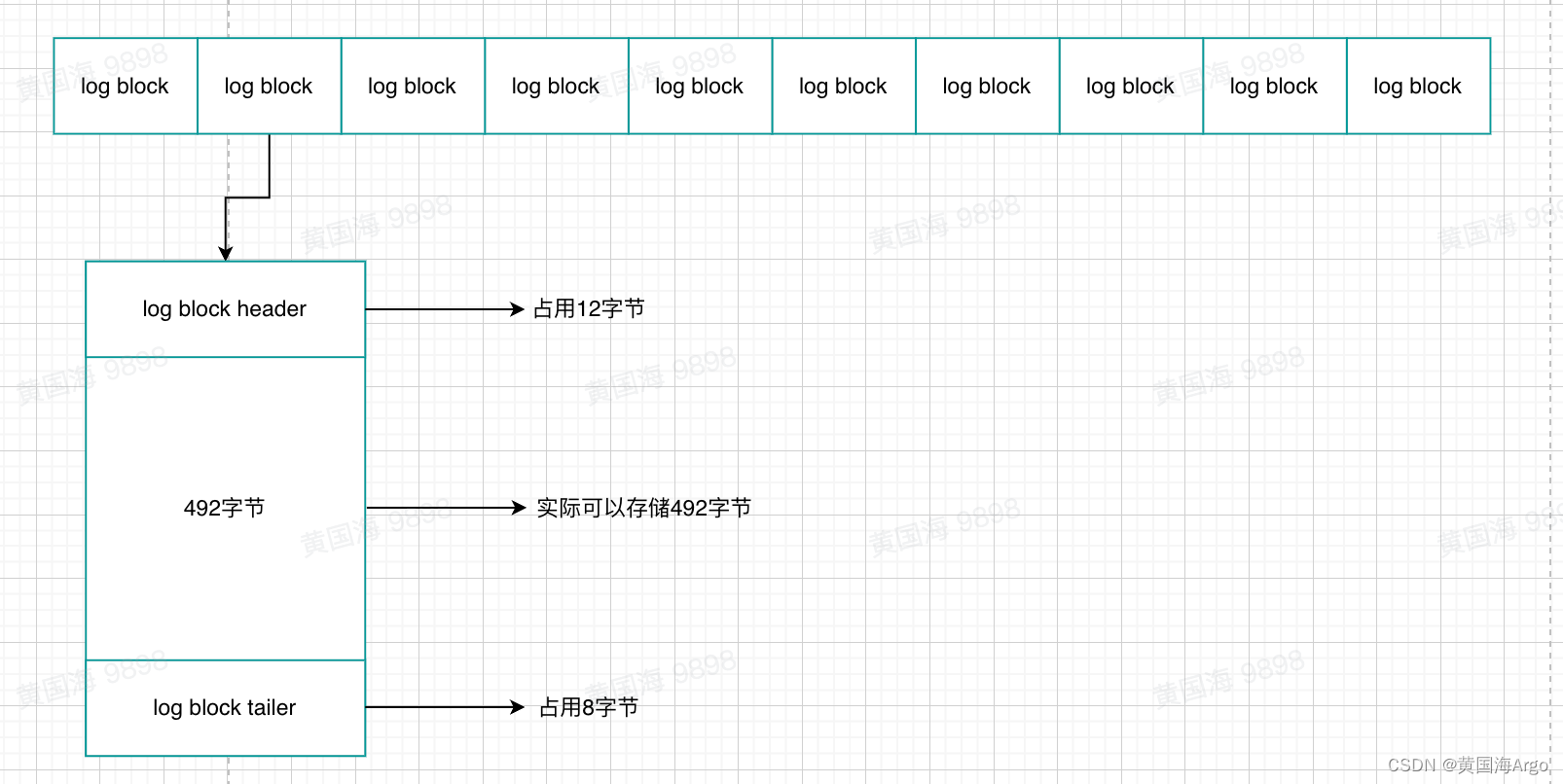
一个redo log block最多可以存储492字节的数据,如果超过了492字节,就会被分配到下一个redo log block。那如果有多条日志都很小,比如10个字节,那么一个redo log block会包含多条日志,那怎么区分每个日志的初始位置呢?
通过LSN可以记录每个页写入重做日志时的LSN的大小。前面说过重做日志记录的是对页的修改,所以在页的数据结构中也有FIL_PAGE_LSN来记录该页的LSN
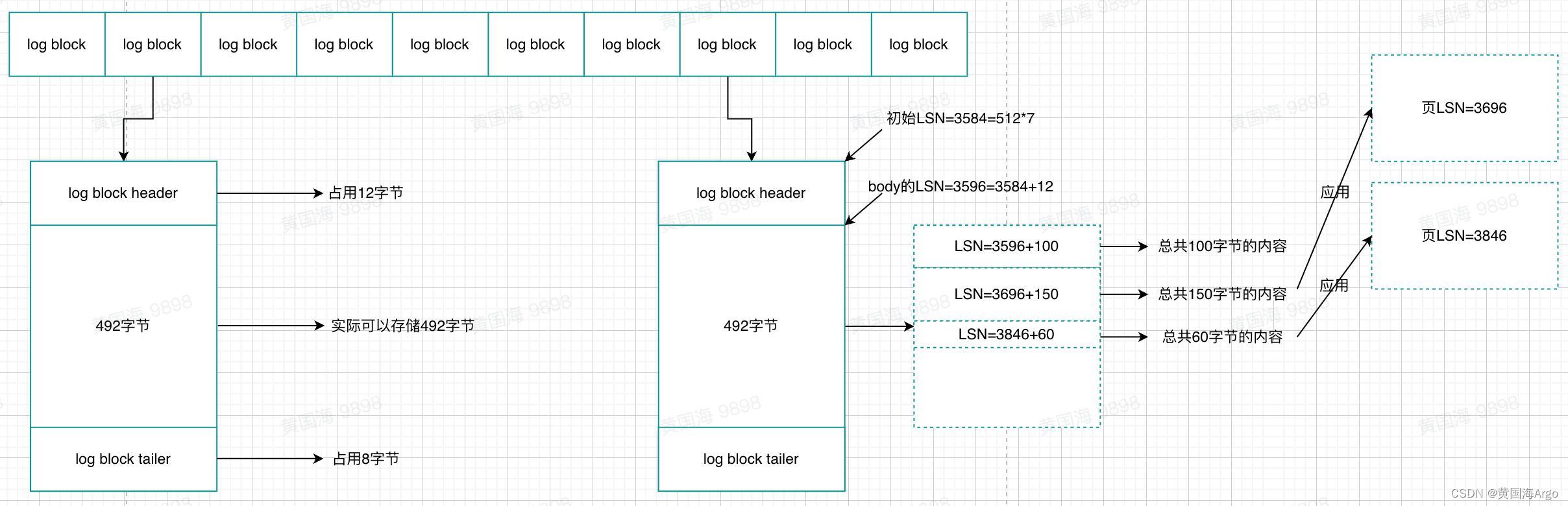
如果重做日志记录到LSN=3906时突然宕机了,并且事务提交了,这时候last checkpoint at=3696,log sequence number=3906,也就是右边的两个页没有实际应用到页里面(也就是事务的结果没最终落地),数据库恢复时,就会吧那两个页应用到对应页中。
Log Sequence number:表示当前的LSN
Log flushed up to:表示刷新到重做日志文件的LSN
Last checkpoint at:表示刷新到磁盘的LSN
数据库恢复时,只需要从Last checkpoint at的位置开始恢复就可以,也就是上面讲的例子?
redo.log的写入特点
从上面的图示中可以看出,redo.log是顺序写的,顺序写的好处就是每次写的时候会用做磁盘寻址,就相当大程度的提高写入效率。这一点很多中间件都会有使用到,比如RocketMQ,Kafka等数据的写入
总结一下
Mysql Innodb数据库引擎的在处理事务提交时是通过两段式提交来完成的。通过结合redo.log,bin.log来完成这个两段式提交的动作。但由于各自文件写入磁盘的时机不同,其在实际存储时的顺序也可能不一样。InnoDB通过三个LSN记录数据库恢复时应该从哪个位置开始,并且恢复时先遍历redo.log,只要是commit状态的直接提交,如果是prepare状态的会检查是否提交bin.log,如果有则提交,如果没有,则不提交
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据采集与预处理02 :网络爬虫实战
- 【AI素描prompt】亲自反复试验结果-素描变美少女高清效果图+200次反复生成
- C++中基类的析构函数为什么要用virtual虚析构函数
- 通过ESP8266连续访问多个IP地址的问题
- 《GitHub Copilot 操作指南》课程介绍
- 中仕教育:考教师编之前需要做哪些准备?
- 一篇文章告诉你爬虫技术到底违不违法,怎么用才合法?
- 蓝桥杯、编程考级、NOC、全国青少年信息素养大赛—scratch列表考点
- Mysql5.7安装配置详细图文教程(msi版本)
- 【SD】进阶实战 为人物添加背景 【1】