基于无锁循环队列的线程池的实现
目录
出处:B站码出名企路
个人笔记:因为是跟着b站的教学视频以及文档初步学习,可能存在诸多的理解有误,对大家仅供借鉴,参考,然后是B站up阳哥的视频,我是跟着他学。大家有兴趣的可以到b站搜索。加油,一起学习。我的问题,大家如果看见,希望可以提出指正,谢谢大家。
应用场景?
从理论角度分析?频繁创建销毁线程场景下,利用线程池复用线程,避免CPU浪费在大量线程的创建,销毁操作上。提高性能,充分利用系统资源。
3. 线程池的具体使用场景有哪些?
需要开线程的地方都可以用。耗时任务的单独处理。它的应用场景和多线程的应用场景是有重合的。
eg:
写日志?
curd
计算
设计实现
等待策略模块
- 第一点,为啥需要封装不同的等待策略?
- 第二点,有哪些等待策略?
- 第三点,如何实现?
对于第一个问题,是很容易根据常识得出结论的,就是具体问题,具体分析。具体场景,具体应对。在多线程编程的环境下,不同的应用场景,要求就需要应用不同的等待机制。每种等待策略,都有着它独特之处,有着它的特点。在对应场景下采用合适的等待策略,可以提高响应性和性能。不同的等待策略权衡了性能、资源利用和响应性。
具体有哪些等待策略,忙等待,休眠等待,条件等待,自旋等待,超时等待。
- 忙等待:在循环中不停的检查是否满足条件,一旦满足就退出循环。忙等待对于CPU的占据是恐怖的,是持续占用大量的CPU时间。所以它适合做那种需要迅速响应,短暂等待时间的情况。不然占着CPU不做事,浪费了系统资源。
- 休眠等待:相当于线程等待挂起,休眠会主动释放掉CPU资源。然后等到定时器触发再唤醒。对于等待时间比较长的时候应该更适合。然后吧。毕竟存在一个线程切换。上下文的保存和恢复需要开销。
- 条件等待:利用条件变量wait操作,等到条件满足再唤醒线程。这样看我感觉和休眠等待有所相似之处,比如两者都会释放CPU,挂起等待,也自然都有线程切换的代价。但是不同的是,两者的唤醒机制不一样。相对来说条件触发更灵活,比定时触发可操控性更强。
- 超时等待:给条件等待设置一个最长等待时间,超出等待时间做另外处理。可结合其他等待方式。
- 自旋等待:自旋等待也是不会主动释放 CPU,持续检查某个条件是否满足。对于等待时间短、期望低延迟的情况比较适用。等久了就会浪费资源。
补充1:主动释放CPU的等待策略共性:都必须线程切换,线程切换也是有代价的,比如每个线程都有上下文。切换时需要保存恢复上下文。所以需要大量切换上下文的场景下,这种方式利用资源的效率反而可能没那么高效。
补充2:占据CPU等待策略共性:忙等和自旋等待,这两货用起来要慎重。因为需要大量占用CPU时间,用的不好就会造成系统资源CPU浪费。利用不充分。
实际往往都是条件变量+锁进行条件等待,我是没太用过自旋锁。
提出一个疑问?自旋锁有哪些使用场景?等我学会了,一定回来回答它。
实现:要达到易扩展,可选择,选择权交给客户端。根据不同的场景选择不同的等待策略。不同的策略之间要解耦合,要达到解除耦合,就要避免大量的if else 判断语句。将选择权交给客户。
策略类基类设计:基类必须要是稳定的,固有的,不变的。扩展时候不能改变基类。这才是良好的设计。所以需要对未来有一定的预测。根据对功能的理解,将固定,共性的功能函数直接放到基类。将不确定,可变(可扩展)的功能函数定义为虚函数(接口函数),晚绑定。
具体策略类设计:继承基类,然后对于接口虚函数进行重写,具体策略具体实现即可。
积累:
虚函数,我们可以理解为接口,它稳定,但天生具有晚绑定,可重写扩展。
此处还想要跟大家讨论一个问题?为何需要虚函数,需要重写?它的出现源于什么?可以从生活角度入手,从各个方面做出回答。
虚:不定,可覆盖,支持变化。任何一类事物中都可能存在特例。凡物哪怕一类,也既有共性,自然也有差异性。辩证统一的看待同一性和差异性。
比如说:车子,有烧汽油的,也有靠电池的。它们都同属于车子这一大类。但是两者工作原理等等存在差异性。可能具有同样的功能接口,但接口的具体实现各不相同。所以需要虚。这就是多态。同一类事物,完成同样的接口功能,所产生的结果,所用的方法都不尽相同。
晚绑定
晚绑定(Late Binding):
-
概念: 晚绑定是指在程序运行时,才确定调用哪个函数、类或方法。这通常与多态性(Polymorphism)有关,其中具体的实现在运行时动态选择,而不是在编译时静态确定。
-
例子: 虚函数的实现就是一种晚绑定的例子。在基类定义一个虚函数,在派生类中提供具体实现,而在运行时系统动态选择正确的实现。
看代码吧:看完代码,再在代码中一起感受具体的实现。我觉得设计模式,理解的基础之上不断的通过代码感受它的那种美妙,那种变化的可控性。变化的尽在手掌,将变化关进笼子里面去,不让它乱跑,造成混乱。
//无锁线程池
/**
* module one: 等待策略的封装, 扩展
* 4种
*/
class WaitStrategy { //等待策略的基类封装
public:
virtual void NotifyOne() {} //cv.notifyone
virtual void BreakAllWait() {} //cv.notifyall
virtual bool EmptyWait() = 0; //cv.wait的定制实现。
virtual ~WaitStrategy() {}
};
/**
* 阻塞等待策略. 这是平常我们用的最多的, 但不一定是最好的
* override关键字: specify override.
*/
class BlockWaitStrategy: public WaitStrategy{
public:
BlockWaitStrategy() = default;
void NotifyOne() override {
m_cv.notify_one();
}
void BreakAllWait() override {
m_cv.notify_all();
}
bool EmptyWait() override {
std::unique_lock<std::mutex> lock(m_mutex);
m_cv.wait(lock);//等锁
return true;
}
private:
std::mutex m_mutex;
std::condition_variable m_cv;
};
/**
* sleep 等待策略.
* 存粹的进入sleep休眠状态.
* explicit 禁止隐式类型转换
* using 技巧,给类型起别名
*/
class SleepWaitStrategy: public WaitStrategy {
using uint = uint64_t; //定制一下,不习惯打数字.
public:
SleepWaitStrategy() = default;
explicit SleepWaitStrategy(uint sleep_time_us)
: m_sleep_time_us(sleep_time_us) {}
bool EmptyWait() override {
std::this_thread::sleep_for(std::chrono::microseconds(m_sleep_time_us));
return true;//休眠空等
}
void SetSleepTime(uint sleep_time_us) {
m_sleep_time_us = sleep_time_us;
}
private:
uint m_sleep_time_us = 10000;
};
//yield 具体原理
/**
* 效果不同: yield 暂停和恢复执行,保留协程的状态;
* sleep 暂停线程的执行,不保留线程的状态。
* yield 用于协程, sleep 用于线程
* 两个都会让出CPU, 区别在于状态保留.
*/
class YieldWaitStrategy: public WaitStrategy {
public:
YieldWaitStrategy(){}
bool EmptyWait()override{
//让出cpu,节省资源
std::this_thread::yield();
return true;
}
};
/**
* timeout等待
* 实际项目中经常采取的一种方式.
* 结合了定时器和阻塞等待. 在一定时间内等到的处理和超时等到的处理相互分离。
* 1. 未超时,等待条件满足了。 2. 超时。
*/
class TimeoutBlockWaitStrategy: public WaitStrategy {
using uint = uint64_t;
public:
TimeoutBlockWaitStrategy() = default;
explicit TimeoutBlockWaitStrategy(uint time_out_ms)
: m_time_out_ms(time_out_ms) {}
void NotifyOne() override {
m_cv.notify_one();
}
void BreakAllWait() override {
m_cv.notify_all();
}
bool EmptyWait() override {
std::unique_lock<std::mutex> lock(m_mutex);
if (m_cv.wait_for(lock, m_time_out_ms) == std::cv_status::timeout) {
//定时器触发了,睡眠等
std::cout << "定时器触发了, 超时" << std::endl;
return false;
}
return true; //条件触发了, 锁等到了
}
void SetTimeOut(uint time_out) {
m_time_out_ms = std::chrono::milliseconds(time_out);
}
private:
std::condition_variable m_cv;
std::mutex m_mutex;
std::chrono::milliseconds m_time_out_ms;
//直接用这个成员,因为可能用到的地方多, 可以少些一点
//如果用uint 每次都要转换成 milliseconds
};
/**
* 可扩展等待策略类实现的体会,感悟.
* 重写, 覆盖体会 override 可以使得基类中不固定的部分变得可扩展起来.
* 并且具有可定制性,根据场景选择适合的策略。有点设计模式喔。
* 是多态,设计模式的实际应用,应用了策略模式。
* 策略模式的好处,强烈的一种具体算法,策略实现的可定制性。可选择性。
* 策略模式允许客户端在运行时选择算法的具体实现,而不必修改其代码。
* 实现方式:父类提供抽象接口,子类指定具体实现.
*/
/**
* 提出疑问,固定的cv.notifyone() 以及 cv.notifyall() 为何不直接具体化下来,而要抽象接口,可扩展?
* 因为有些类无需实现这两个函数,但有些类需要实现。
* 具体问题具体分析,存在特例,定制,变化的功能模块,
* 我们就可以考虑是否运用多态,使其扩展开放,且不影响外部接口调用
*/我学习这份代码的过程中,有一些思考感受。在注释中,大家可以参考一下,我觉得还是很有用的。
代码中内涵的各种细节知识点汇总:
/**
?* 阻塞等待策略. 这是平常我们用的最多的, 但不一定是最好的
?* override关键字: specify override.?
*/
C++ 中的?override关键字
- override针对基类中虚函数,子类希望对该虚函数进行重写时加上该关键字,可以避免写时失误而重定义新函数或者参数重载;
- override不能写在子类非虚函数后面,也不能写在基类中没有的虚函数后面;
- 如果我们将某个函数指定为为final,则之后任何尝试覆盖该函数的操作都将引发错误
总之加上override为了明确告诉编译器你的意图,即你打算重写一个基类中的虚函数。
帮助编译器检查你的代码,确保你所声明的函数确实是基类中虚函数的一个覆盖。如果没有正确覆盖,编译器将产生错误。增加可读性。


C++中的 default 关键字
default关键字就是告诉编译器,让他显示的生成默认构造函数以及特殊成员函数
class MyClass {
public:
MyClass() = default; // 使用default关键字生成默认构造函数
};
class ExplicitlyDefaulted {
public:
ExplicitlyDefaulted() = default;
ExplicitlyDefaulted(const ExplicitlyDefaulted&) = default;
// 显式声明编译器生成复制构造函数
ExplicitlyDefaulted& operator=(const ExplicitlyDefaulted&) = default;
// 显式声明编译器生成赋值运算符
};
C++中的 delete 关键字
对应default的还有一个delete,可以禁用特殊成员函数,比如构造,赋值成员函数,写单例就要用到它。
class NoCopy {
public:
NoCopy(const NoCopy&) = delete; // 显式删除复制构造函数
NoCopy& operator=(const NoCopy&) = delete; // 显式删除赋值运算符
};
C++中的 explicit 关键字
explicit 禁止隐式类型转换
C++中 using 别名技巧
using 技巧,给类型起别名
using uint = uint64_t; //定制一下,不习惯打数字.sleep 和 yield的区别
//yield 具体原理
/**
?* 效果不同: yield 暂停和恢复执行,保留协程的状态;
?* sleep 暂停线程的执行,不保留线程的状态。
?* yield 用于协程, sleep 用于线程
?* 两个都会让出CPU, 区别在于状态保留.
*/
/**
?* 可扩展等待策略类实现的体会,感悟.?
?* 重写, 覆盖体会 override 可以使得基类中不固定的部分变得可扩展起来.
?* 并且具有可定制性,根据场景选择适合的策略。有点设计模式喔。
?* 是多态,设计模式的实际应用,应用了策略模式。
?* 策略模式的好处,强烈的一种具体算法,策略实现的可定制性。可选择性。
?* 策略模式允许客户端在运行时选择算法的具体实现,而不必修改其代码。
?* 实现方式:父类提供抽象接口,子类指定具体实现.
*/
/**
?* 提出疑问,固定的cv.notifyone() 以及 cv.notifyall() 为何不直接具体化下来,而要抽象接口,可扩展?
?* 因为有些类无需实现这两个函数,但有些类需要实现。
?* 具体问题具体分析,存在特例,定制,变化的功能模块。
?* 我们就可以考虑是否运用多态,使其扩展开放,且不影响外部接口调用。
* 只要存在变化的可能我们就要抽象接口,变化就是通过抽象接口的继承重写来达到的。在基类显示的明确这些变化接口。把它们都关在一起。不让他们混乱,到处招惹是非。
*/
noexcept关键字
用于声明一个函数不会抛出异常。
volatile关键字

告诉编译器你不要优化它。每次都必须去读实际的内存,不要优化去读cache。我很易变,你去读实际内存,不要读缓存,因为可能缓存失效了。多线程场景下。另一个线程修改了它,本线程中的缓存就没用了。
用途: 通常用于多线程或者在中断服务程序中,当一个变量的值可能被多个线程或者中断同时修改时,为了避免编译器对变量进行过度的优化,可以使用volatile。
有一个注意点:C++中的 volatile 跟Java中的volatile有区别,C++中并不能直接用来禁止指令重排。注意区分。
无锁循环队列的设计实现
这块不太好写,核心是要搞懂入队,出队逻辑。这两货是最重要的函数,是实现的关键。无锁,我们就需要利用CAS。CAS几乎是所有语言并发编程都有的操作,不管那个语言肯定都提供了可以完成CAS的API函数。
CAS:compare and swap. 比较并且交换。和期望的旧值比较,如果这个值没有变,说明当前别的线程没有进行原子操作修改这个变量,就可以swap完成原子更新操作。如果比较发现值变化了。就跟新期望旧值,重新再来。这不就是天然的 do {} while();

原子性
为什么操作没有原子性?
因为存在中间层,所有的操作都不是不是CPU直接跟内存交互,直接完成的,而是通过缓存(寄存器)这个中间层间接完成的。这会导致数据不一致性。缓存不一致性。因为缓存的修改可以并没有及时的刷新回内存。
eg如下:对于核心1,2结果跟新到缓存,但是缓存结果并未滴落,跟新到内存。核心3看到的还是Old, 过时的数据,运算的最终结果就会出现问题。

因为它可以在任何增量值从缓存中滴入内存之前读到内存中的旧的X.

什么是原子性,原子操作?
原子性:看到的状态只有开始,结束,没有中间
原子操作:指的是要么处于已完成的状态,要么处于初始状态,而不存在中间状态的操作
如何保证原子性?




原子操作不总是最快
原子操作不总是无锁


上述的无锁指的是硬件实现有无锁。是否需要锁总线。

内存序
-
为什么会有内存序的问题?
-
如何解决读写操作的内存序问题,在达到预期的条件下尽量提高性能?
内存序的问题是因为在多线程环境下存在? CPU指令重排 和 编译器优化重排。
这种重排就可能导致指令执行顺序的不确定性,所以我们需要规定内存序,来指导CPU和编译器进行指令重排,来达到预期的结果。



我自认为积累还不够,暂时理解不了那个深度。所以我选择先记下来,简单理解常见的内存序用在什么场景下就行。
常用的就那么5个:
memory_order_relaxed:宽松内存序,只关心原子性,对于指令执行顺序不关心。对于数据的最新同步性也不要求。给编译器和CPU自由,你们随意调整。
memory_order_seq_cst:默认内存序(全局内存序),保障指令的执行肯定是顺序的,根本没给编译器和CPU留余地,是最严苛的内存序级别。结果肯定能保证符合预期,但是性能可能有所损耗
memory_order_acquire:获取内存序。用于读取操作,也就是load操作。可以保证结果没问题,性能相对还好点,具体为啥,我不是很懂,往下肯定就是内存屏障。
memory_order_release:释放内存序。用于写操作,也就是store操作。
memory_order_acq_rel:获取释放内存序,用于读和写操作。

获取内存屏障

释放内存屏障


+----------------------------+----------------------------+
| thread A | thread B |
+----------------------------+----------------------------+
| store A | |
| inst B | |
| release store X | |
| store D | acquire load X |
| | load A // valid |
| | load D // maybe invalid |
+----------------------------+----------------------------+保障释放内存屏障之前的写操作一定是在release store X 之前完成。获取内存屏障之后的读取操作一定是在acquire load? X 之后完成。? 这就保障了A线程的写入操作对线程B可见。

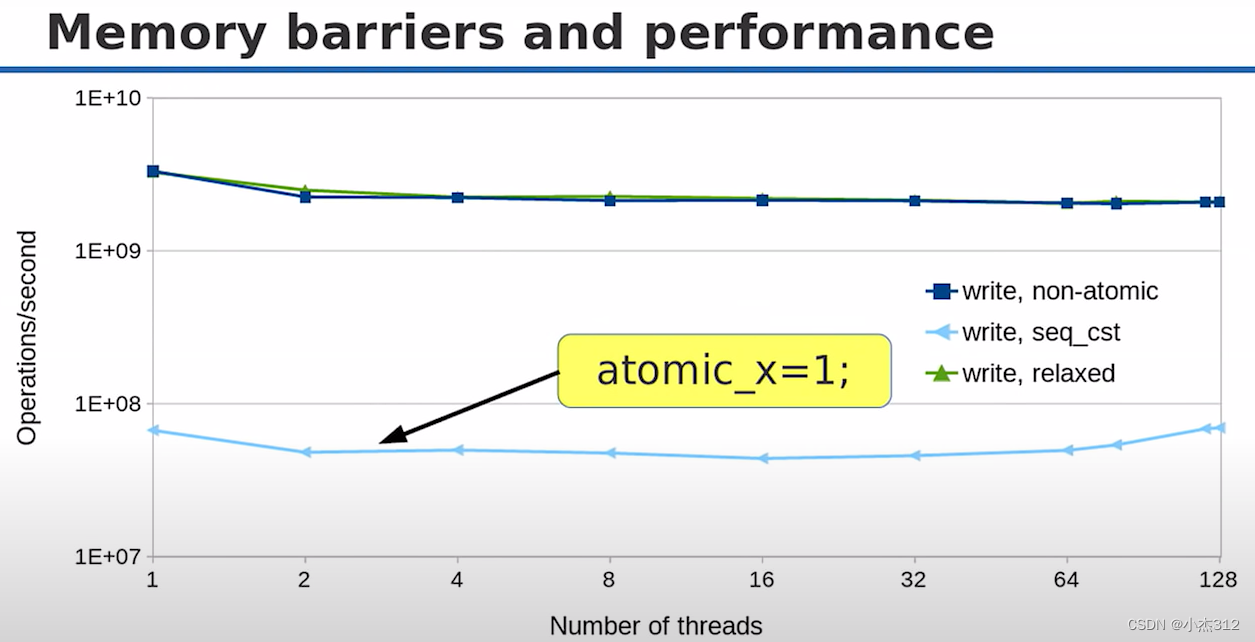
总结:对于性能而言,不论是无锁和有锁。还是内存屏障或者说内存顺序的选择。都并没有绝对的定论。无锁不是一定就更快。内存序也不是一定默认内存序快。在不同的场景选择合适的方式来实现才能达到对性能的极值追求。
接口实现原理:最主要的就是Enqueue和Dequeue两个接口了。
为什么要采用无锁队列? 无锁和有锁的区别是什么?
锁会带来的问题 (频繁线程切换,抢占所带来的损耗)
- Cache失效
在保存和恢复上下文的过程中还隐藏了额外的开销:Cache中的数据会失效,因为它缓存的是将被换出任务 的数据,这些数据对于新换进的任务是没用的
- Mutex上下文切换
任务将大量的时间(睡眠,等待,唤醒)浪费在获得保护队列数据的互斥锁,而不是处理队列中的数据上。 保存,恢复上下文。
- 频繁的动态内存分配和释放
当?个任务从堆中分配内存时,标准的内存分配机制会阻 塞所有与这个任务共享地址空间的其它任务(进程中的所有线程)。
有哪些无锁队列的设计方法? 设计思路,对应好处。(对于zmq只写个大致思路,不写具体实现)
- 参考zmq:结合数组和链表两者。(每次申请一个chunk大块,chunk节点包括N个元素的数组。这样既有链表的动态分配,大小不受限制的好处。又有减少内存分配次数,提高性能的好处。)
- 循环无锁队列:大小固定,支持多写多读,1写多读,多写1读。有多生产者问题,在多生产者场景下如何保证顺序插入性?? 很重要。如何保证按照顺序插入数据,生产数据,保证读取的时候数据一定写入了空间,这些是关键点。
具体实现:采取两个多余空间,一个存储头部,另一个存储尾部的循环队列实现。
结构定义
#define CACHELINE_SIZE 64
/*
@第二部分:有界队列,用来存储模板类型 T的元素
该队列存放线程池任务,最常用的接口,入队和出队队列:task
采用的非循环队列. 轻队列设计,重线程池设计.
*/
template <typename T>
class BoundedQueue {
using uint = uint64_t;
public:
BoundedQueue &operator=(const BoundedQueue &other) = delete;
BoundedQueue(const BoundedQueue &other) = delete;
//禁止掉拷贝构造和拷贝赋值操作。
BoundedQueue() = default;
~BoundedQueue();
void BreakAllWait(); //notifyall
bool Init(uint capacity); //默认等待策略
bool Init(uint capacity, WaitStrategy *strategy); //可选择等待策略.
// 入队,实际入队
bool Enqueue(const T &element);
// bool Enqueue(T&& element);
/*
@ 队列满时,阻塞等待, 条件等待
*/
bool WaitEnqueue(const T &element);
// bool WaitEnqueue(T&& element);
// 出队
bool Dequeue(T *element);
bool WaitDequeue(T *element);
uint Size() {
return m_tail - m_head - 1;
}
bool Empty() {
return Size() == 0;
}
void SetWaitStrategy(WaitStrategy *strategy) { //设置等待策略.
m_wait_strategy.reset(strategy);
}
uint Head() { return m_head.load(); }
uint Tail() { return m_tail.load(); }
uint MaxHead() { return m_max_head.load(); }
private:
// 队里索引下标
uint GetIndex(uint num);
// 指定内存对齐方式, 可提高代码性能和效率
// atomic 保障原子操作, 无锁.
alignas(CACHELINE_SIZE) std::atomic<uint> m_head = {0};
alignas(CACHELINE_SIZE) std::atomic<uint> m_tail = {1};
alignas(CACHELINE_SIZE) std::atomic<uint> m_max_head = {1}; //最大的head, tail的备份
uint m_pool_capacity = 0; // 记录线程池容量
T *m_pool = nullptr; // 线程池数组容器
std::unique_ptr<WaitStrategy> m_wait_strategy = nullptr; //等待策略
volatile bool m_break_all_wait = false; // 标记是否存在等待
};
Init初始化

template <typename T>
bool BoundedQueue<T>::Init(uint capacity, WaitStrategy *strategy) {
m_pool_capacity = capacity + 2; //多出两个空间
m_pool = reinterpret_cast<T*>(std::calloc(m_pool_capacity, sizeof(T)));
if (m_pool == nullptr) {
return false;
}
for (uint i = 0; i < m_pool_capacity; i ++) {
new (&m_pool[i]) T(); //定位new.
}
m_wait_strategy.reset(strategy);
return true;
}Wait操作
wait操作的逻辑都是一样的,先尝试一次入队或者出队。如果成功则返回。如果失败则陷入等待,如果等待条件触发则再次尝试。? 如果等待超时则break。入队或出队失败。
template<typename T>
bool BoundedQueue<T>::WaitEnqueue(const T &element) {
while (!m_break_all_wait) {
if (Enqueue(element)) { //首次尝试插入
return true;
}
// 没有插入成功. 说明队满, 按照等待策略等待
if (m_wait_strategy->EmptyWait()) {
continue; //如果cond条件触发再次尝试插入
}
break; //timeout
}
return false;
}Enqueue操作
存在多生产者的问题,多个生产者线程同时要插入数据到循环队列中。


第一个CAS:是为了保证原子性的单个操作。这个不需要管顺序性。只需要先获取存储空间。
第二个CAS:其实不只是为了保证原子性,更是为了保证真正的顺序插入。以保障读写一致性。否则读Dqueue那边不清楚到底插入了几个元素了。而顺序插入则一定可以保证当前的m_max_head,也就是最大读取下标之前所有空间的元素已经全部完成插入。这一点很重要,是这个无锁循环队列实现的关键。大家结合代码逻辑认知体会。
template<typename T>
bool BoundedQueue<T>::Enqueue(const T &element) {
uint new_tail = 0; //用于存储new_tail
uint old_tail = m_tail.load(std::memory_order_acquire); //获取旧值
uint old_max_head = 0; //临时存储old_max_head
do {
new_tail = old_tail + 1;
if (GetIndex(new_tail) == GetIndex(m_head.load(std::memory_order_acquire))) {
return false; //队列满 插入失败. 后续陷入等待.
}
} while (!m_tail.compare_exchange_weak(old_tail, new_tail,
std::memory_order_acq_rel,
std::memory_order_relaxed)); //保障空间申请的原子性
m_pool[GetIndex(old_tail)] = element; //旧(就)地插入
do {
old_max_head = old_tail;
} while (!m_max_head.compare_exchange_weak(old_tail, new_tail,
std::memory_order_acq_rel,
std::memory_order_relaxed)); //更新max_head.
m_wait_strategy->NotifyOne(); //通知消费
return true;
}Dequeue操作
上面那个Enqueue读懂这个Dequeue完全OK.
template<typename T>
bool BoundedQueue<T>::Dequeue(T *element) {
uint new_head = 0; //存储最新head
uint old_head = m_head.load(std::memory_order_acquire); //加载存储旧head
do {
new_head = old_head + 1; //空间移除, 计算新头
//是否满足在最大出队下标以内
//此时不用 m_tail 判断队列空,
//原因是: 可能和入队操作冲突, 先申请了空间, 元素还没插入, 入队操作还未彻底完成
if (new_head == m_max_head.load(std::memory_order_acquire)) {
return false; //队空
}
//用element传出参数传出pop的数据, 也就是new_head中的数据
*element = m_pool[GetIndex(new_head)];
} while (!m_head.compare_exchange_weak(old_head, new_head,
std::memory_order_acq_rel,
std::memory_order_relaxed));
m_wait_strategy->NotifyOne(); //通知生产.
return true;
}线程池结构设计实现
就是一个生产者消费者模型嘛。
class ThreadPool
{
public:
explicit ThreadPool(std::size_t thread_num,
std::size_t max_task_num = 1000) : stop_(false) {
// 初始化失败抛出异常
if (!task_queue_.Init(max_task_num, new BlockWaitStrategy())) {
throw std::runtime_error("Task queue init failed");
}
// 存放多个 std::thread线程对象
workers_.reserve(thread_num);
for (size_t i = 0; i < thread_num; ++i) {
// 使用一个 lambda表达式来创建每个线程
// 功能是 从任务队列中获取任务,并执行任务的函数对象
workers_.emplace_back([this] {
while(!stop_) {
std::function<void()> task;
if (task_queue_.WaitDequeue(&task)){
task();
}
}
});
}
}
template <typename F, typename... Args>
auto Enqueue(F &&f, Args &&...args) -> std::future<typename std::result_of<F(Args...)>::type> {
using return_type = typename std::result_of<F(Args...)>::type;
// 函数 f和其参数args, 打包成一个 std::packaged_task对象,放入任务队列
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));
// 并返回一个与该任务关联的 std::future对象
std::future<return_type> res = task->get_future();
if (stop_) {
return std::future<return_type>();
}
task_queue_.Enqueue([task]()
{ (*task)(); });
return res;
}
inline ~ThreadPool() {
if (stop_.exchange(true)) {
return;
}
task_queue_.BreakAllWait();
for (std::thread &worker : workers_) {
worker.join();
}
}
private:
std::vector<std::thread> workers_;
BoundedQueue<std::function<void()>> task_queue_;
std::atomic_bool stop_;
};此处思路不难,就是开启线程,不断从任务队列中WaitDeueue处理任务罢了。
如果说有难点也是Enqueue的再封装,用到的语法很是新奇,我没咋用过。核心也就是打包一个函数任务塞入任务队列,等待消费者线程wockers消化。并且以future对象形式返回任务执行结果。
如下:源码,完整版。
#include <mutex>
#include <condition_variable>
#include <thread>
#include <functional>
#include <iostream>
#include <chrono>
#include <atomic>
#include <vector>
#include <string>
#include <queue>
#include <future>
#include <sstream>
#include <cstdint>
#include <cstdlib>
#include <memory>
#include <utility>
#define CACHELINE_SIZE 64
//无锁线程池
/**
* module one: 等待策略的封装, 扩展
* 4种
*/
class WaitStrategy { //等待策略的基类封装
public:
virtual void NotifyOne() {} //cv.notifyone
virtual void BreakAllWait() {} //cv.notifyall
virtual bool EmptyWait() = 0; //cv.wait的定制实现。
virtual ~WaitStrategy() {}
};
/**
* 阻塞等待策略. 这是平常我们用的最多的, 但不一定是最好的
* override关键字: specify override.
*/
class BlockWaitStrategy: public WaitStrategy{
public:
BlockWaitStrategy() = default;
void NotifyOne() override {
m_cv.notify_one();
}
void BreakAllWait() override {
m_cv.notify_all();
}
bool EmptyWait() override {
std::unique_lock<std::mutex> lock(m_mutex);
m_cv.wait(lock);//等锁
return true;
}
private:
std::mutex m_mutex;
std::condition_variable m_cv;
};
/**
* sleep 等待策略.
* 存粹的进入sleep休眠状态.
* explicit 禁止隐式类型转换
* using 技巧,给类型起别名
*/
class SleepWaitStrategy: public WaitStrategy {
using uint = uint64_t; //定制一下,不习惯打数字.
public:
SleepWaitStrategy() = default;
explicit SleepWaitStrategy(uint sleep_time_us)
: m_sleep_time_us(sleep_time_us) {}
bool EmptyWait() override {
std::this_thread::sleep_for(std::chrono::microseconds(m_sleep_time_us));
return true;//休眠空等
}
void SetSleepTime(uint sleep_time_us) {
m_sleep_time_us = sleep_time_us;
}
private:
uint m_sleep_time_us = 10000;
};
//yield 具体原理
/**
* 效果不同: yield 暂停和恢复执行,保留协程的状态;
* sleep 暂停线程的执行,不保留线程的状态。
* yield 用于协程, sleep 用于线程
* 两个都会让出CPU, 区别在于状态保留.
*/
class YieldWaitStrategy: public WaitStrategy {
public:
YieldWaitStrategy() {}
bool EmptyWait() override {
//让出cpu,节省资源
std::this_thread::yield();
return true;
}
};
/**
* timeout等待
* 实际项目中经常采取的一种方式.
* 结合了定时器和阻塞等待. 在一定时间内等到的处理和超时等到的处理相互分离。
* 1. 未超时,等待条件满足了。 2. 超时。
*/
class TimeoutBlockWaitStrategy: public WaitStrategy {
using uint = uint64_t;
public:
TimeoutBlockWaitStrategy() = default;
explicit TimeoutBlockWaitStrategy(uint time_out_ms)
: m_time_out_ms(time_out_ms) {}
void NotifyOne() override {
m_cv.notify_one();
}
void BreakAllWait() override {
m_cv.notify_all();
}
bool EmptyWait() override {
std::unique_lock<std::mutex> lock(m_mutex);
if (m_cv.wait_for(lock, m_time_out_ms) == std::cv_status::timeout) {
//定时器触发了,睡眠等
std::cout << "定时器触发了, 超时" << std::endl;
return false;
}
return true; //条件触发了, 锁等到了
}
void SetTimeOut(uint time_out) {
m_time_out_ms = std::chrono::milliseconds(time_out);
}
private:
std::condition_variable m_cv;
std::mutex m_mutex;
std::chrono::milliseconds m_time_out_ms;
//直接用这个成员,因为可能用到的地方多, 可以少些一点
//如果用uint 每次都要转换成 milliseconds
};
/**
* 可扩展等待策略类实现的体会,感悟.
* 重写, 覆盖体会 override 可以使得基类中不固定的部分变得可扩展起来.
* 并且具有可定制性,根据场景选择适合的策略。有点设计模式喔。
* 是多态,设计模式的实际应用,应用了策略模式。
* 策略模式的好处,强烈的一种具体算法,策略实现的可定制性。可选择性。
* 策略模式允许客户端在运行时选择算法的具体实现,而不必修改其代码。
* 实现方式:父类提供抽象接口,子类指定具体实现.
*/
/**
* 提出疑问,固定的cv.notifyone() 以及 cv.notifyall() 为何不直接具体化下来,而要抽象接口,可扩展?
* 因为有些类无需实现这两个函数,但有些类需要实现。
* 具体问题具体分析,存在特例,定制,变化的功能模块,
* 我们就可以考虑是否运用多态,使其扩展开放,且不影响外部接口调用
*/
/*
@第二部分:有界队列,用来存储模板类型 T的元素
该队列存放线程池任务,最常用的接口,入队和出队队列:task
采用的非循环队列. 轻队列设计,重线程池设计.
*/
template <typename T>
class BoundedQueue {
using uint = uint64_t;
public:
BoundedQueue &operator=(const BoundedQueue &other) = delete;
BoundedQueue(const BoundedQueue &other) = delete;
//禁止掉拷贝构造和拷贝赋值操作。
BoundedQueue() = default;
~BoundedQueue();
void BreakAllWait(); //notifyall
bool Init(uint capacity); //默认等待策略
bool Init(uint capacity, WaitStrategy *strategy); //可选择等待策略.
// 入队,实际入队
bool Enqueue(const T &element);
// bool Enqueue(T&& element);
/*
@ 队列满时,阻塞等待, 条件等待
*/
bool WaitEnqueue(const T &element);
// bool WaitEnqueue(T&& element);
// 出队
bool Dequeue(T *element);
bool WaitDequeue(T *element);
uint Size() {
return m_tail - m_head - 1;
}
bool Empty() {
return Size() == 0;
}
void SetWaitStrategy(WaitStrategy *strategy) { //设置等待策略.
m_wait_strategy.reset(strategy);
}
uint Head() { return m_head.load(); }
uint Tail() { return m_tail.load(); }
uint MaxHead() { return m_max_head.load(); }
private:
// 队里索引下标
uint GetIndex(uint num);
// 指定内存对齐方式, 可提高代码性能和效率
// atomic 保障原子操作, 无锁.
alignas(CACHELINE_SIZE) std::atomic<uint> m_head = {0};
alignas(CACHELINE_SIZE) std::atomic<uint> m_tail = {1};
alignas(CACHELINE_SIZE) std::atomic<uint> m_max_head = {1}; //最大的head, tail的备份
uint m_pool_capacity = 0; // 记录线程池容量
T *m_pool = nullptr; // 线程池数组容器
std::unique_ptr<WaitStrategy> m_wait_strategy = nullptr; //等待策略
volatile bool m_break_all_wait = false; // 标记是否存在等待
};
template <typename T>
inline uint64_t BoundedQueue<T>::GetIndex(uint num) {
return num - (num / m_pool_capacity) * m_pool_capacity;
}
template <typename T>
inline void BoundedQueue<T>::BreakAllWait() { //唤醒所有
m_break_all_wait = 1;
m_wait_strategy->BreakAllWait();
}
template <typename T>
inline bool BoundedQueue<T>::Init(uint capacity) {
return Init(capacity, new SleepWaitStrategy());
}
template <typename T>
bool BoundedQueue<T>::Init(uint capacity, WaitStrategy *strategy) {
m_pool_capacity = capacity + 2; //多出两个空间
m_pool = reinterpret_cast<T*>(std::calloc(m_pool_capacity, sizeof(T)));
if (m_pool == nullptr) {
return false;
}
for (uint i = 0; i < m_pool_capacity; i ++) {
new (&m_pool[i]) T(); //定位new.
}
m_wait_strategy.reset(strategy);
return true;
}
template <typename T>
BoundedQueue<T>::~BoundedQueue() {
if (m_wait_strategy) { //唤醒所有, 都该销毁了
m_wait_strategy->BreakAllWait();
}
if (m_pool) { //析构对象释放内存.
for (uint i = 0; i < m_pool_capacity; i++) {
m_pool[i].~T(); //显示析构
}
std::free(m_pool);
}
}
template<typename T>
bool BoundedQueue<T>::WaitEnqueue(const T &element) {
while (!m_break_all_wait) {
if (Enqueue(element)) { //首次尝试插入
return true;
}
// 没有插入成功. 说明队满, 按照等待策略等待
if (m_wait_strategy->EmptyWait()) {
continue; //如果cond条件触发再次尝试插入
}
break; //timeout
}
return false;
}
template<typename T>
bool BoundedQueue<T>::WaitDequeue(T *element) {
while (!m_break_all_wait) {
if (Dequeue(element)) { //先尝试出队
return true;
}
if (m_wait_strategy->EmptyWait()) { //出队失败, 等
continue; //条件触发, 再次尝试
}
break; //timeout
}
return false;
}
/**
* push 入队逻辑 先申请空间,拿到空间,后插入元素。
* 注意:只是申请空间必须保证原子性,顺序性。
* 空间原子申请到了,顺序了,元素插入顺序不所谓,不影响最终结果
* 注意,完成 tail+'1' 操作拿到空间,并且完成了 元素放入空间,插入操作并未结束.
* 必须保证了m_max_head的跟新操作,而且m_max_head的跟新也必须顺序.
* 原因, 保证数据拷贝进入之后才允许消费者线程将其出队
* 呼应 dequeue操作的 new_head < m_max_head 才出队
*/
template<typename T>
bool BoundedQueue<T>::Enqueue(const T &element) {
uint new_tail = 0; //用于存储new_tail
uint old_tail = m_tail.load(std::memory_order_acquire); //获取旧值
uint old_max_head = 0; //临时存储old_max_head
do {
new_tail = old_tail + 1;
if (GetIndex(new_tail) == GetIndex(m_head.load(std::memory_order_acquire))) {
return false; //队列满 插入失败. 后续陷入等待.
}
} while (!m_tail.compare_exchange_weak(old_tail, new_tail,
std::memory_order_acq_rel,
std::memory_order_relaxed)); //保障空间申请的原子性
m_pool[GetIndex(old_tail)] = element; //旧(就)地插入
do {
old_max_head = old_tail;
} while (!m_max_head.compare_exchange_weak(old_tail, new_tail,
std::memory_order_acq_rel,
std::memory_order_relaxed)); //更新max_head.
m_wait_strategy->NotifyOne(); //通知消费
return true;
}
/**
* pop 逻辑是 head 先加一 再pop new_head. head 本来就是队首元素的前一位.
* head 是空队头
*/
template<typename T>
bool BoundedQueue<T>::Dequeue(T *element) {
uint new_head = 0; //存储最新head
uint old_head = m_head.load(std::memory_order_acquire); //加载存储旧head
do {
new_head = old_head + 1; //空间移除, 计算新头
//是否满足在最大出队下标以内
//此时不用 m_tail 判断队列空,
//原因是: 可能和入队操作冲突, 先申请了空间, 元素还没插入, 入队操作还未彻底完成
if (new_head == m_max_head.load(std::memory_order_acquire)) {
return false; //队空
}
//用element传出参数传出pop的数据, 也就是new_head中的数据
*element = m_pool[GetIndex(new_head)];
} while (!m_head.compare_exchange_weak(old_head, new_head,
std::memory_order_acq_rel,
std::memory_order_relaxed));
m_wait_strategy->NotifyOne(); //通知生产.
return true;
}
/*
@第三部分: threadPool实现,对外接口,将任务提交到一个任务队列
然后使用多个线程来并发处理这些任务
微信公众号 《码出名企路》 获取视频,文档,代码,入圈,与小伙伴一起学习
*/
class ThreadPool
{
public:
explicit ThreadPool(std::size_t thread_num,
std::size_t max_task_num = 1000) : stop_(false) {
// 初始化失败抛出异常
if (!task_queue_.Init(max_task_num, new BlockWaitStrategy())) {
throw std::runtime_error("Task queue init failed");
}
// 存放多个 std::thread线程对象
workers_.reserve(thread_num);
for (size_t i = 0; i < thread_num; ++i) {
// 使用一个 lambda表达式来创建每个线程
// 功能是 从任务队列中获取任务,并执行任务的函数对象
workers_.emplace_back([this] {
while(!stop_) {
std::function<void()> task;
if (task_queue_.WaitDequeue(&task)){
task();
}
}
});
}
}
template <typename F, typename... Args>
auto Enqueue(F &&f, Args &&...args) -> std::future<typename std::result_of<F(Args...)>::type> {
using return_type = typename std::result_of<F(Args...)>::type;
// 函数 f和其参数args, 打包成一个 std::packaged_task对象,放入任务队列
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));
// 并返回一个与该任务关联的 std::future对象
std::future<return_type> res = task->get_future();
if (stop_) {
return std::future<return_type>();
}
task_queue_.Enqueue([task]()
{ (*task)(); });
return res;
}
inline ~ThreadPool() {
if (stop_.exchange(true)) {
return;
}
task_queue_.BreakAllWait();
for (std::thread &worker : workers_) {
worker.join();
}
}
private:
std::vector<std::thread> workers_;
BoundedQueue<std::function<void()>> task_queue_;
std::atomic_bool stop_;
};
/*
@ 第四部分:线程池的测试用例
1,封装线程池的等待策略:4
2,有界队列:保持task:封装了等待策略对象,用来选择不同的wait
3,threadpool,对外提供接口,封装有界队列对象,用来入队
微信公众号 《码出名企路》
*/
class Test_ThreadPool
{
public:
void test() {
ThreadPool thread_pool(4);
std::vector<std::future<std::string>> results;
for (int i = 0; i < 8; i++) {
results.emplace_back(
thread_pool.Enqueue(
[i]() {
std::ostringstream ss;
ss << "hello world"<< i;
std::cout<< ss.str() << std::endl;
return ss.str();
}
)
);
}
for (auto &&result : results) {
std::cout << "result: " << result.get() << std::endl;
}
}
};
int main()
{
Test_ThreadPool test_;
test_.test();
return 0;
}
这篇我的理解还很浅。因为以前没咋用过,所以有点知识的堆砌,大家理解,以后肯定会改进。刚学,大家感兴趣的可以去b站搜索阳哥,他给了更详细的文档,只是要点费用,但是不多,都是学知识嘛。慢慢积累。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!