Python语言学习笔记之九(爬虫)
本课程对于有其它语言基础的开发人员可以参考和学习,同时也是记录下来,为个人学习使用,文档中有此不当之处,请谅解。
1、什么是爬虫
通俗的讲:就是模拟浏览器抓取数据,科学的讲:通过一定的规则,使用程序对互联网相关数据解析并存储
爬虫流程:
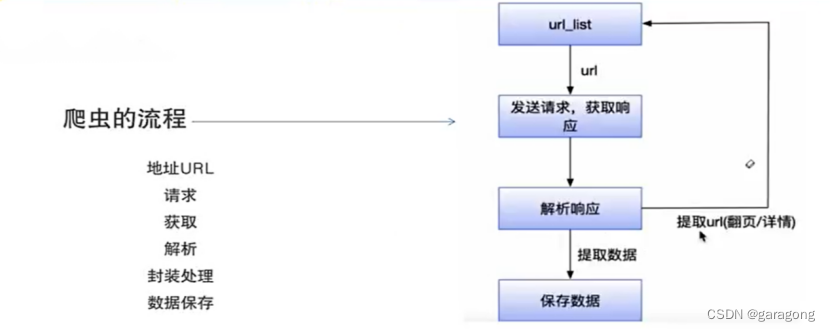
首先需要提取URL,根据URL请求数据,服务器反馈对应的List,对获取的数据进行解析、封装处理,并把数据保存在本地存储设备上。
2、知识储备
网页前端知识:
需要了解前端和网络知识了,毕竟爬虫的最终操作对象大部分都是前端,关于前端知识并不需要掌握太多,只要了解HTML、CSS、JS就可以了,对于网络主要掌握http协议中的POST/GET的相关知识。
浏览器运行流程:
Python爬虫是根据浏览器的运行流程,模拟浏览器与服务器交互,需要了解浏览器的运行流程,运行流程如下:

Python提供的网络请求库:
- urllib库:用于操作网页 URL,并对网页的内容进行抓取处理,是Python内置的HTTP请求库,包含4个模块request、error、parse、obotparser。
- urllib.request - 打开和读取 URL,requests属于第三方库,基于 urllib 编写的,阻塞式 HTTP 请求库,常用方法:get、head是从服务器获取信息到本地,put、post、patch、delete是从本地向服务器提交信息。
- urllib.error - 包含 urllib.request 抛出的异常
- urllib.parse-解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。
其中urllib.request 的 urlopen 方法来打开一个 URL看其中的一些参数:
read()函数获取网页的 HTML 实体代码,加入参数控制长度readline()- 读取文件的一行内容readlines()-读取文件的全部内容
- selenium:主要用于模拟浏览器运行,是一个用于web应用测试的工具,selenium直接运行在浏览器中,看起来就像人在操作一样,可以无窗口模式运行。
Python提供的网络解析库:
网页解析库:解析网页信息也就是从网页中提取需要的字段信息,了解以下几个库
- beautifulsoup:html 和 XML 的解析,从网页中提取信息,同时拥有强大的API和多样解析方式
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好
- lxml:支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- tesserocr:一个 OCR 库,在遇到验证码(图形验证码为主)的时候,可直接用 OCR 进行识别
数据存储库:
小体量数据可以直接保存到文档文件,如txt、xlsx、csv、json、dat等等。
大体量数据需要保存到数据库,了解以下几个库:
- pymysql:一个纯 Python 实现的 MySQL 客户端操作库。
- pymongo:一个用于直接连接 mongodb 数据库进行查询操作的库。
- redisdump:一个用于 redis 数据导入/导出的工具。
2.1 HTTP知识
Http,超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP的初衷是为了提供一种发布和接收HTML页面的方法

HTTP是如何传输:
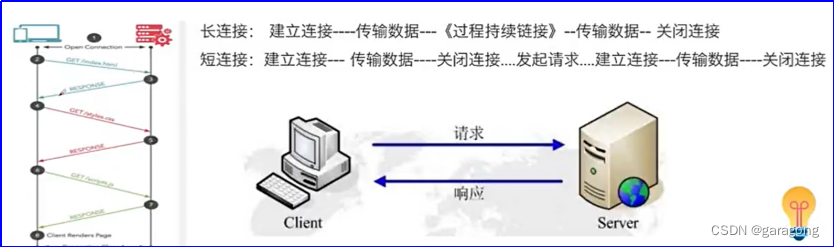
HTTP是基于TCP/IP来实现的,它的三次握手和四次握手:
三次握手是建立连接;四次握手是断开连接;
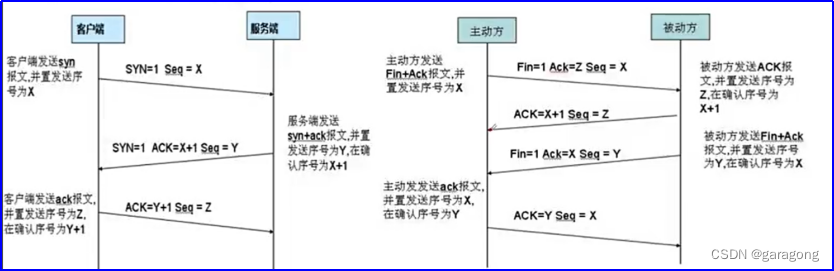
关键标志含义:
ACK:确认标志(期望对方继续发送数据包的序号)确认编号(Acknowledgement Number)栏有效。大多数情况下该标志位是置位的。TCP报头内的确认编号栏内包含的确认编号(w+1,Figure-1为下一个预期的序列编号,同时提示远端系统已经成功接收所有数据。Seq是数据包本身的序列号
目的为了连接以后传送数据,ack是对收到的数据包的确认,值是等待接收的数据包的序列号。第一次消息发送,client随机选取一个序列号作为初始序号发送给server; 第二次消息server使用ack对client的数据进行确认,因为已经收到了序列号为x的数据包,准备接收序列号为x+1的包,所以ack=x+1,同时server告诉client自己的初始序列号,就是seq=y; 第三条消息client告诉server收到了server的确认消息并准备建立连接,A自己此条消息的序列号是x+1,所以seq=x+1,而ack=y+1是表示A正准备接收B序列号为y+1的数据包。
FIN: 结束标志
当client端发送该标志的数据包用来结束一个TCP回话,但对应端口仍处于开放状态,准备接收后续数据
为什么断开连接不是三次呢?
假如client在收到server的FIN请求段后直接close,那么服务器会做超时处理重发FIN数据段这是client回复的不是ACK=1,ack=se(server的序列号)+1,而是给server回复了RST=1数据段那么server认为是数据错误,从而向上层报错,但是这样的跟TCP是可靠连接的概念是相悖的所以在收到server端的FIN数据段后自己也要回复ACK确认数据段并且进入TIMEWAIT状态等待2MSL后如果没有消息就进入close 状态。
2.2?Https
HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证同时保护交换数据的隐私与完整性
SSL协议由网景公司发明与1994年,后由IETF进行标准化,发布为TLS,在应用层普遍习惯称两者为SSL/TLS
Https实现原理
1、客户端发起HTTPS请求
浏览器里面输入一个HTTPS网址,然后连接到服务端的443端口上。注意这个过程中客户端会发送一个密文族给服务端,密文族是浏览器所支持的加密算法的清单
2、服务端配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥,可以这么理解,公钥就是一把锁头,私钥就是这把锁的钥匙,锁头可以给别人对某个东西进行加锁,但是加锁完毕之后,只有持有这把锁的钥匙才可以解锁看到加锁的内容。
3、传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构、过期时间等等
4、客户端解析证书
这部分工作是由客户端的TLS来完成的,首先会验证公钥是否有效,如颁发机构、过期时间等等,如果发现异常则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密传送加密信息
目的就是让服务端得到这个随机值,然后客户传送的是用证书加密后的随机值 (pre master secret 的随机密码串),端和服务端的通信就可以通过这个随机值来进行加密和解密了。
5、服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值,至此一个非对称加密的过程结束,看到TLS利用非对称加密实现了身份认证和密钥协商。然后把内容通过该值进行对称加密
6、传输加密后的信息
服务端用随机值加密后的信息,可以在客户端被还原
7、客户端解密信息
客户端用之前生成的随机值解密服务端传送过来的信息,于是获取了解密后的内容,至此一个对称加密的过程结束看到对称加密是用于对服务器待传送给客户端的数据进行加密用的。整个过程即使第三方监听了数据,也束手无策
???????2.3?Https VS Http
HTTP特点:
无状态:协议对客户端没有状态存储,对事物处理没有“记忆”能力,比如访问一个网站需要反复进行登录操作无连接:HTTP/1.1之前,由于无状态特点,每次请求需要通过TCP三次握手四次挥手,和服务器重新建立连接比如某个客户机在短时间多次谐求同一个资源,服务器并不能区别是否已经响应过用户的谐求,所以每次需要重新响应请求,需要耗费不必要的时间和流量。
基于请求和响应:基本的特性,由客户端发起请求,服务端响应,通信使用明文、请求和响应不会对通信方进行确认无法保护数据的完整性
HTTPS特点:
内容加密:采用混合加密技术,中间者无法直接查看明文内容验证身份:通过证书认证客户端访问的是自己的服务器保护数据完整性:防止传输的内容被中间人冒充或者篡改
存在的一些问题
SSL证书需要购买申请,功能越强大的证书费用越高,这是额外的支出SSL证书。
通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗(SSL有扩展可以部分解决这个问题,但是比较麻烦,而且要求浏览器、操作系统支持,Windows XP就不支持这个扩展,考虑到XP的装机量这个特性几乎没用)
优与劣
- 根据ACM CONEXT数据显示,使用HTTPS协议会使页面的加载时间延长近50%,增加10%到20%的耗电。
- HTTPS连接缓存不如HTTP高效,流量成本高。
- HTTPS连接服务器端资源占用高很多,支持访客多的网站需要投入更大的成本
- HTTPS协议握手阶段比较费时,对网站的响应速度有影响,影响用户体验。比较好的方式是采用分而治之,类似12306网站的主页使用HTTP协议,有关于用户信息等方面使用HTTPS。
请求头信息
常用请求报头
Accept:请求报头域用于指定客户端接受哪些类型的信息
Accept-Charset;请求报头域用于指定客户端接受的字符集
Accept-Language:请求报头域类似于Accept,但是它是用于指定一种自然语言
Authorization:请求报头域主要用于证明客户端有权查看某个资源
不同的请求方式,应用在不用的请求场景,更为重要的是匹配功能的模式
GET请求指定的页面信息,并返回实体主体。
Head类似于GET请求,只不过返回的响应中没有具体的内容,
PUT用于获取报头向指定资源提交数据进行处理请求。数据被包含在请求体中。
POST请求可能会导致新的资源的建立和/或已有资源的修改。
DELETE请求服务器删除指定的页面。
OPTIONS允许客户端查看服务器的性能。
TRACE回显服务器收到的请求,主要用于测试或诊断。
PATCH是对PUT方法的补充,用来对已知资源进行局部更新。
在正确实现的条件下,GET,HEAD,PUT和DELETE 等方法都是幂等的,而 POST方法不是。
所有的safe方法也都是幂等的。
幂等性概念:
幂等性的核心概念是- 可以多次发送请求,而无需对服务器状态做额外的更改
这里需要关注几个重点:
幂等不仅仅只是一次(或多次)请求对资源没有副作用(比如查询数据库操作,没有增删改,因此没有对数据库有任何影响)。
幂等还包括第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。
幂等关注的是以后的多次请求是否对资源产生的副作用,而不关注结果。
网络超时等问题,不是幂等的讨论范围。
什么情况下需要幂等:
- 用户在APP上连续点击了多次提交订单,后台应该只产生一个订单;
- 向支付宝发起支付请求,由于网络问题或系统BUG重发,支付宝应该只扣一次钱。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 固乔快递查询助手:批量、快速、全面的快递信息查询软件
- Nginx配置反向代理实例一
- EfficientVit实现轻量化改进YOLOV8:级联分组注意力模块的全新实时网络架构#重塑实时物体检测的未来
- 基于Java SSM框架实现摄影器材租赁系统项目【项目源码+论文说明】
- Day 46 动态规划 8
- LabVIEW实时建模检测癌细胞的异常
- 新手抖店入门教程,从开店到起店,小白一看就懂!
- 解析区块链----看看老司机是如何玩转Dapp。
- 考试面试轻松应对:技术人的备考宝库 | 开源专题 No.58
- MC服务器备份脚本