数据挖掘-10-酒店预订需求(包含数据和代码)
0. 数据代码下载
关注公众号:『AI学习星球』
回复:酒店预订需求 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或?v:codebiubiu滴滴我

1. 业务梳整
本次“酒店预订需求”项目主要通过Python做预处理,分析酒店的房型供给、不同时间段的需求变化、最核心的消费群体、影响退订的因素,并利用分类算法建立酒店订单退订的预测模型。
整体分析流程如下:
- 提出问题
- 查看并理解数据
- 数据清洗
- 数据挖掘及可视化
- 数据建模
2. 提出问题
该项目为酒店线上预订业务的研究内容,从酒店运营角度,主要关心酒店的整体线上预订量如何,退订量有多少,造成这些退订的因素有哪些,可以怎么提升预订入住率;从客户体验角度,主要关心哪些房型的预订量较高(有所偏爱),客户的复定率怎么样,客户的预订入住频率、消费金额、消费近度怎样,是否为重要价值客户,重点跟进维护。
针对这个项目主要围绕下面三个问题进行分析:
-
哪些房型的入住率最高,找出最受欢迎的房型,优化酒店房型分配
-
客户入住晚数的需求分布情况怎样,哪些的需求量最大,并统计出这些用户偏爱入住的房型
-
用户为何取消预订,哪些因素与此最相关,我们如何判断一个预订订单被取消的可能性
3. 数据处理
3.1 数据导入
#导入相关的库,方便后续调用
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["font.serif"] = ["SimHei"]
%matplotlib inline
#读取数据
hotel_data = pd.read_csv('hotel_bookings.csv')
#查看数据的基本信息
hotel_data.info()
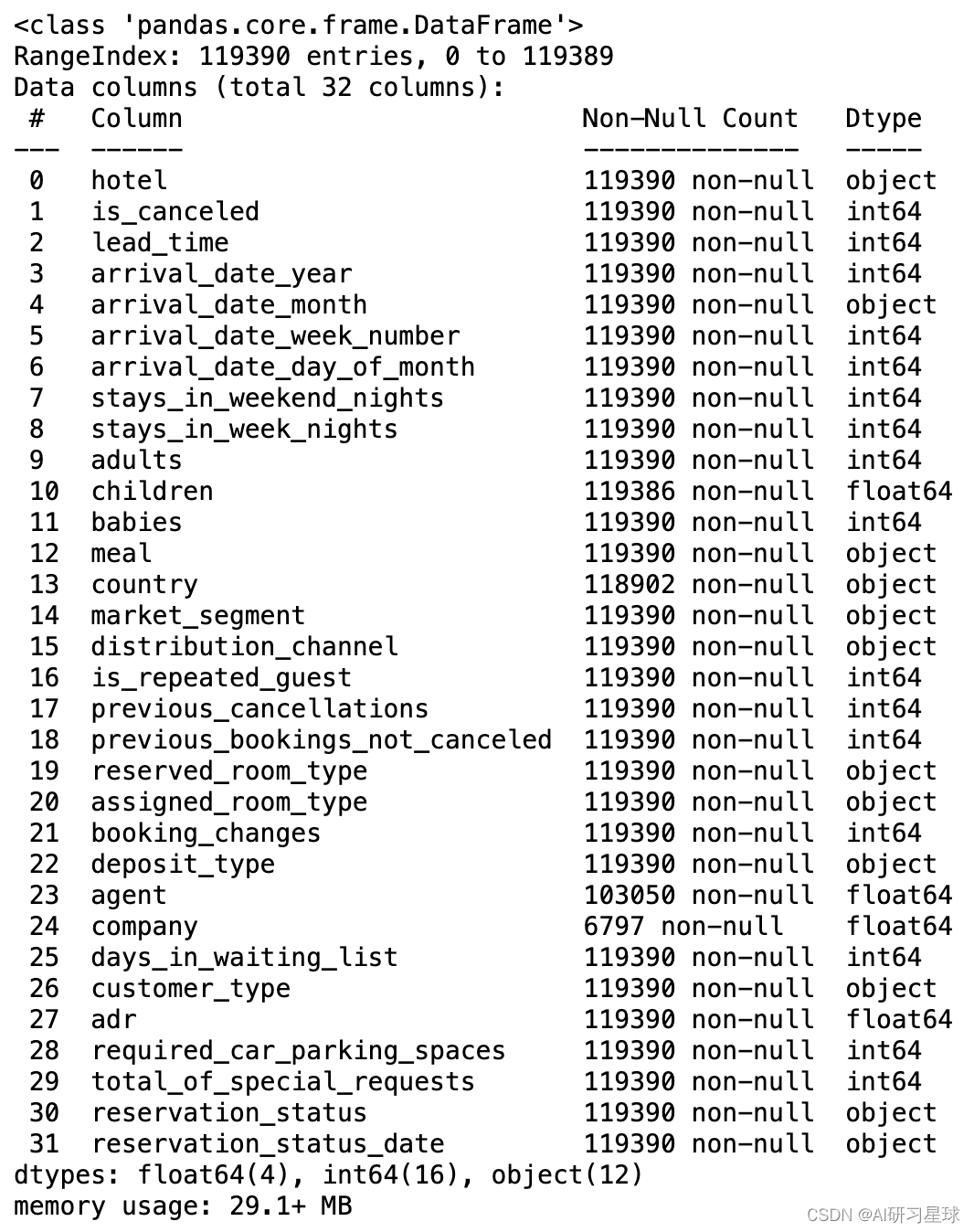
数据集总计有32个字段,119389行数据,有比较明显的缺失值company,另arrival_date_等可能需合并,并转化为日期格式。
#查看并理解数据
hotel_data.head()

3.2 字段说明
| 字段名称 | 字段含义 |
|---|---|
| hotel | 酒店类型:city hotel(城市酒店),resort hotel(度假酒店) |
| is_canceled | 订单是否取消:1(取消),0(没有取消) |
| lead_time | 下单日期到抵达酒店日期之间间隔的天数 |
| arrival_date_year | 抵达年份:2015、2016、2017 |
| arrival_date_month | 抵达月份:1月-12月 |
| arrival_date_day_of_month | 抵达日期:1-31日 |
| arrival_date_week_number | 抵达的年份周数:第1-72周 |
| stays_in_weekend_nights | 周末(星期六或星期天)客人入住或预定入住酒店的次数 |
| stays_in_week_nights | 每周晚上(星期一至星期五)客人入住或预定入住酒店的次数 |
| adults | 成年人数 |
| children | 儿童人数 |
| babies | 婴儿人数 |
| meal | 预定的餐型:SC\BB\HB\FB |
| country | 原国籍 |
| marked_segment | 细分市场 |
| distribution_channel | 预定分销渠道 |
| is_repeated_guest | 订单是否来自老客户(以前预定过的客户):1(是),0(否) |
| previous_cancellations | 客户在当前预定前取消的先前预定数 |
| previous_bookings_not_canceled | 客户在本次预定前未取消的先前预定数 |
| reserved_room_type | 给客户保留的房间类型 |
| assigned_room_type | 客户下单时指定的房间类型 |
| booking_changes | 从预定的PMS系统中输入之日起至入住或取消之日止,对预定所作的更改/修改的数目 |
| deposit_type | 预定定金类型,是否可以退还:No Deposit(无订金),Non Refund(不可退),Refundable(可退) |
| agent | 预定的旅行社 |
| company | 下单的公司(由它付钱) |
| days_in_waiting_list | 订单被确定前,需要等待的天数 |
| customer_type | 客户类型 |
| adr | 平均每日收费,住宿期间的所有交易费用之和/住宿晚数 |
| required_car_parking_spaces | 客户要求的停车位数 |
| total_of_special_requests | 客户提出的特殊要求的数量(例如:双人床或高层) |
| reservation_status | 订单的最后状态:canceled(订单取消),Check-Out(客户已入住并退房),No-show(客户没有出现,并且告知酒店原因) |
目前该数据集是32个字段,根据Kaggle对各个字段的解释,整理出该表。
关注公众号:『AI学习星球』
回复:酒店预订需求 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或?v:codebiubiu滴滴我
4. 数据清洗
4.1 缺失值处理
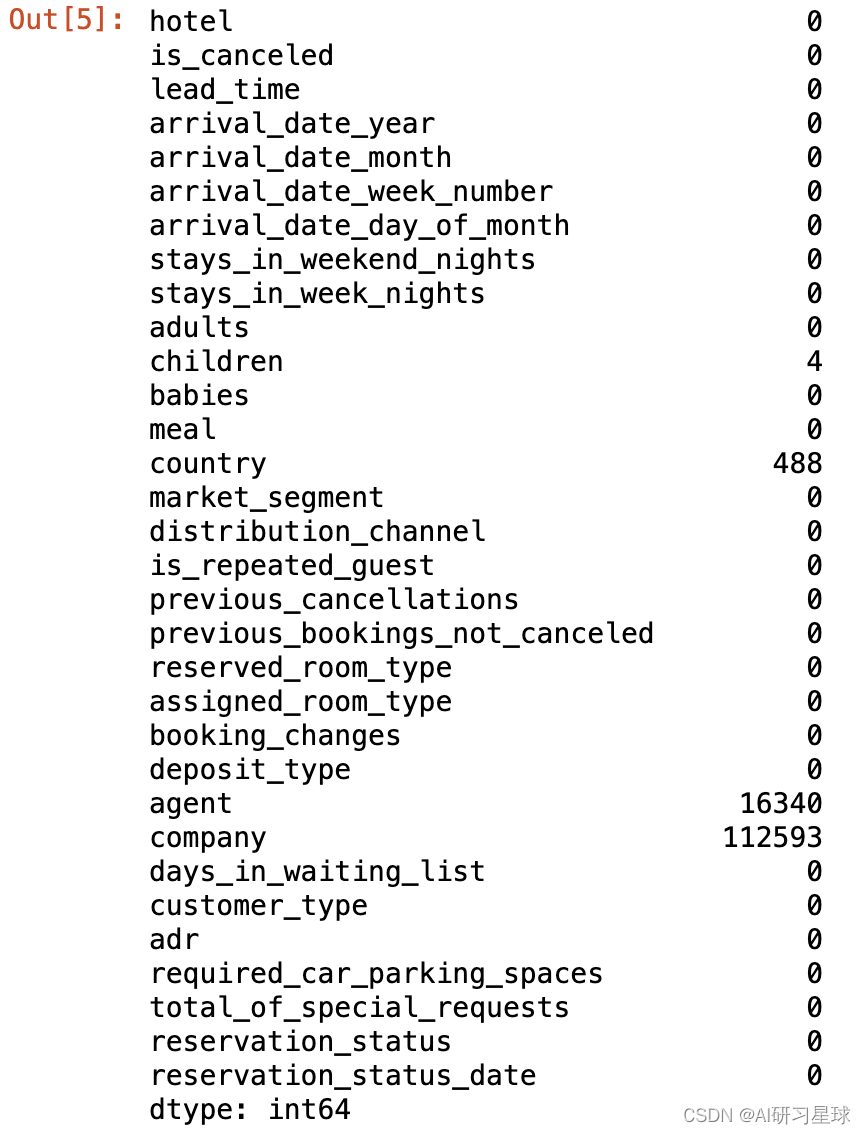
# 统计缺失值
hotel_data.isnull().sum()
#统计缺失率
hotel_data.isnull().sum()/hotel_data.shape[0]
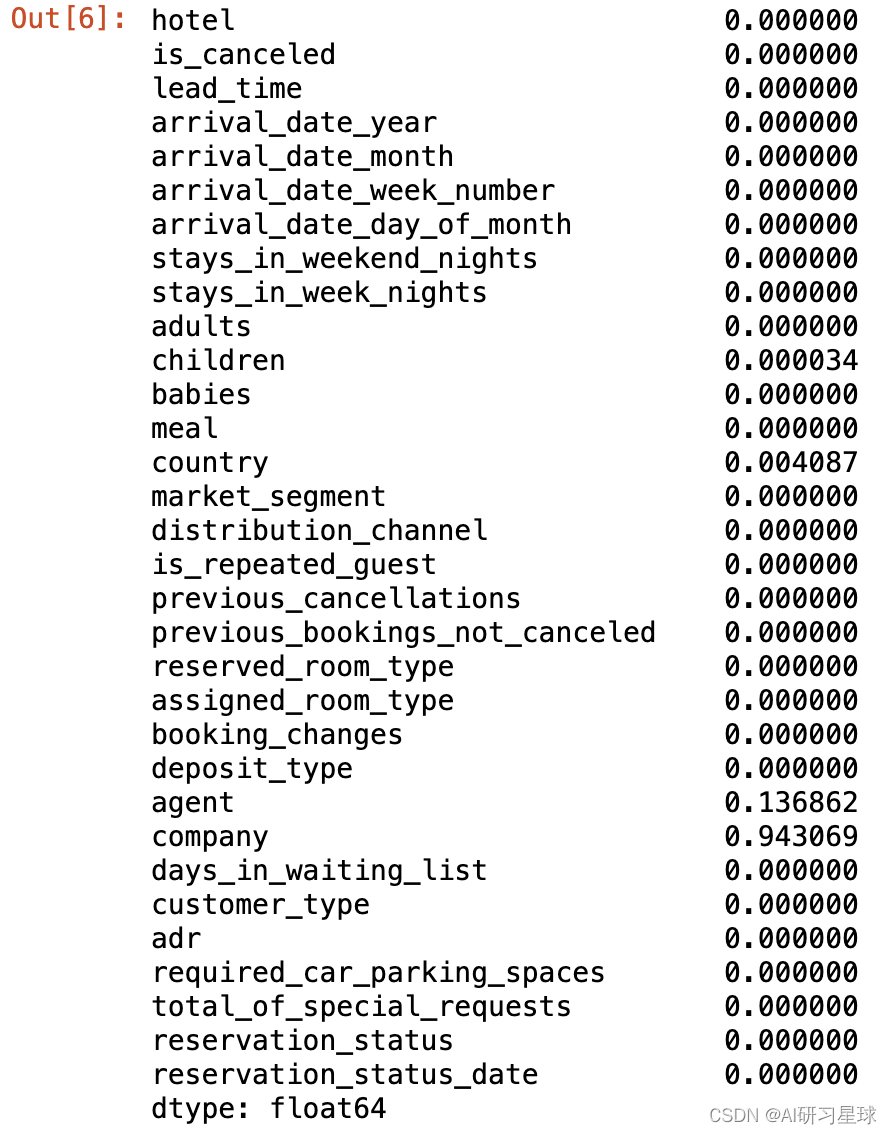
数据的缺失值主要存在于children,country,agent,company4个字段,缺失最多的是company
- children缺失4个,且为数值型变量,所以用中位数填充
- country缺失488个,且为类别型变量,所以使用众数填充
- agent缺失16340个,缺失率为13.6%,缺失数量较大,但agent表示预订的旅行社,且缺失率小于20%,建议保留,并用0填充,表示没有旅行社ID
- company缺失112593个,缺失率为94.3%>80%,不具备信息价值有效性,所以直接删除
#复刻样本数据,不对数据源做处理
data_new = hotel_data.copy()
# 处理company字段,直接删除
data_new.drop("company",axis=1,inplace=True)
# 处理children字段,中位数填充
data_new.children.fillna(data_new.children.median(), inplace=True)
# 处理country字段,众数填充
data_new.country.fillna(data_new.country.mode()[0],inplace=True)
# 处理agent字段,0值填充
data_new.agent.fillna(0, inplace=True)
注意每次做完数据清洗需要对该清洗进行检验,此处由于篇幅做省略
4.2 重复值处理
由于该数据集是酒店的每个预订记录,没有对应主键,可能存在重复值,暂不做重复处理
备:
data_new.duplicated().sum():查询重复量
data_new[data_new.duplicated()==True]:查询重复值
若有重复值,可以使用data_new.drop_duplicates(),删除重复行
4.3 异常值处理
可以看出小孩的入住量、旅行社代理入住的量均不能是浮点数,需要统一规划为整型数据
# children、agent字段不可能为浮点数,需修改数据类型
data_new.children = data_new.children.astype(int)
data_new.agent = data_new.agent.astype(int)
meal里总计有5种餐型,其中Undefined / SC –无餐套餐为一类,需统一替换为SC类
# 根据原数据集介绍,餐饮字段中的Undefined / SC –无餐套餐为一类
data_new.meal.replace("Undefined", "SC", inplace=True)
数据集中adults,children,babies字段均为0,即同一订单下,预订入住的人数不能为0,需剔除处理
#查看异常值
data_new.describe()
#删除异常值的行
zero_guests = list(data_new["adults"] + data_new["children"] + data_new["babies"] == 0)
data_new.drop(data_new.index[zero_guests],inplace=True)
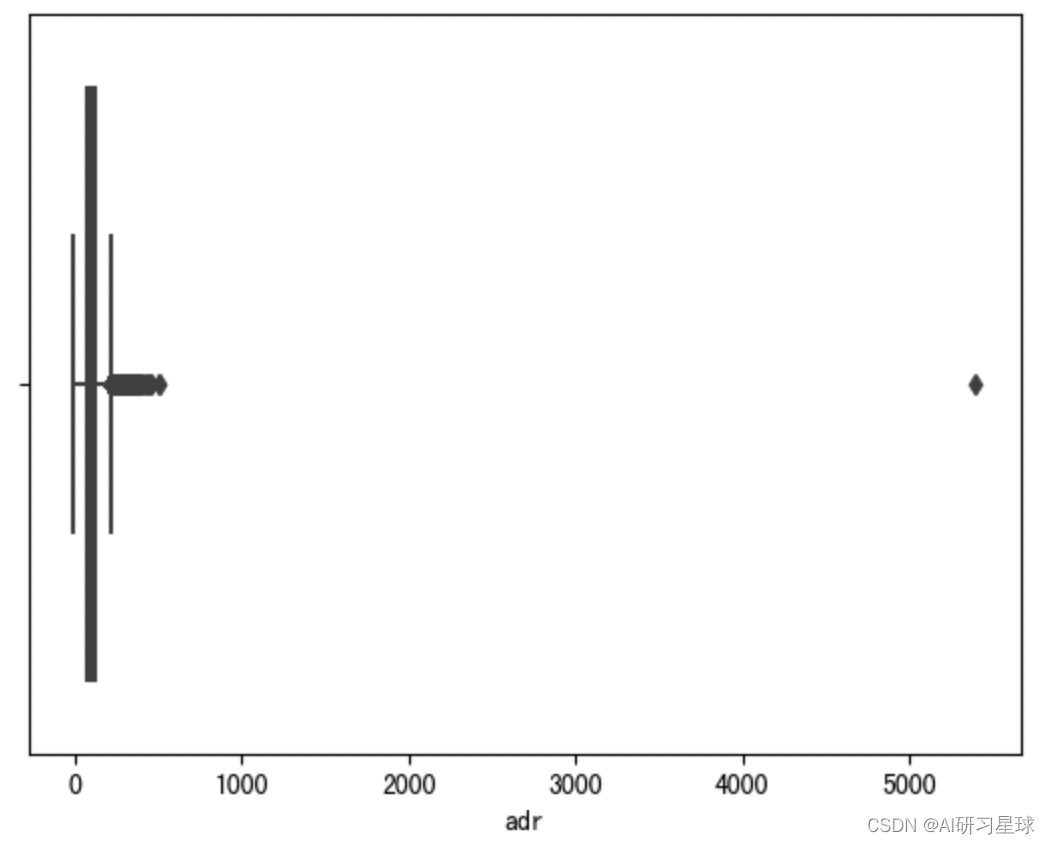
酒店平均每日收费有一个大于5000的离群值,会严重影响描述性统计,需删除离群值
#核实adr变量的离群值情况
sns.boxplot(x=data_new['adr'])
#删除离群值
data_new = data_new[data_new["adr"]<5000]
关注公众号:『AI学习星球』
回复:酒店预订需求 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或?v:codebiubiu滴滴我
5. 数据挖掘及可视化
考虑数据集中部分字段结构冗余,整体数据量较大,需做统一合并处理
arrival_date_month抵达的月份为英文格式,与抵达的年、日格式不符
#修改arrival_date_month的英文月份为中文月份
import calendar
month = []
for i in data_new.arrival_date_month:
mon = list(calendar.month_name).index(i)
month.append(mon)
data_new.insert(4,"arrival_month",month)
arrival_date_抵达的年月日,结构单一,建议合并
#增加一列预订到店的年月日arrival_date
data_new[["arrival_date_year","arrival_month","arrival_date_day_of_month"]] = data_new[["arrival_date_year","arrival_month","arrival_date_day_of_month"]].apply(lambda x:x.astype(str))
date = data_new.arrival_date_year.str.cat([data_new.arrival_month,data_new.arrival_date_day_of_month],".")
data_new.insert(3,"arrival_date",date)
统计stays_in_ _nights入住的晚数
#增加一列总住宿晚数stays_nights_total
nums_stays = data_new.stays_in_weekend_nights + data_new.stays_in_week_nights
data_new.insert(9,"stays_nights_total",nums_stays)
统计每单入住人数adults+children+babies
#增加一列住宿人数number_of_people
nums_peoples = data_new.adults + data_new.children + data_new.babies
data_new.insert(12,"number_of_people",nums_peoples)
5.1 指标分析
a. 预定量怎么样
#不同酒店的预订数
book_amount = data_new.groupby("hotel")["is_canceled"].count().reset_index().rename(columns={"is_canceled":"amount"})
book_amount["book_rate"] = round(book_amount.amount/book_amount.amount.sum(),4)
book_amount
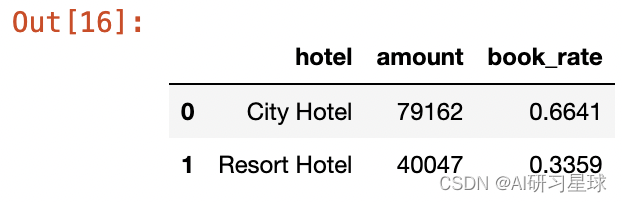
数据集收录了2015.7.1至2017.8.29期间的所有预定数据,划分为City Hotel(城市酒店)和Resort Hotel(度假酒店)。在不考虑酒店退订的情况下,城市酒店的预订量占比66.41%,是度假酒店预订量的2倍
b. 预定入住率怎么样
#核实总的预订入住率
check_in_rate = str(round(data_new.groupby("is_canceled")["is_canceled"].count()[0]/data_new.shape[0]*100,2))+"%"
canceled_rate = str(round(data_new.groupby("is_canceled")["is_canceled"].count()[1]/data_new.shape[0]*100,2))+"%"
print("该数据的总预订入住率:",check_in_rate)
print("相应的总预订取消率:",canceled_rate)
结果:
该数据的总预订入住率: 62.96%
相应的总预订取消率: 37.04%
统计整体的预订入住情况,总的预订入住率还是只停留在62.96%,取消情况会在后续的影响因素分析中进一步挖掘
#度假酒店预订入住情况
rh_iscanceled_count = data_new[data_new["hotel"]=="Resort Hotel"].groupby("is_canceled")["hotel"].count().reset_index().rename(columns={"hotel":"amount"})
rh_cancel_data = pd.DataFrame({"hotel":"度假酒店",
"is_canceled":rh_iscanceled_count.is_canceled,
"count":rh_iscanceled_count.amount,
"iscanceled_rate":rh_iscanceled_count.amount/rh_iscanceled_count.amount.sum()})
#城市酒店预订入住情况
ch_iscanceled_count = data_new[data_new["hotel"]=="City Hotel"].groupby("is_canceled")["hotel"].count().reset_index().rename(columns={"hotel":"amount"})
ch_cancel_data = pd.DataFrame({"hotel":"城市酒店",
"is_canceled":ch_iscanceled_count.is_canceled,
"count":ch_iscanceled_count.amount,
"iscanceled_rate":ch_iscanceled_count.amount/ch_iscanceled_count.amount.sum()})
#不同酒店类型预订入住率
iscancel_data = pd.concat([rh_cancel_data,ch_cancel_data],ignore_index=True)
iscancel_data
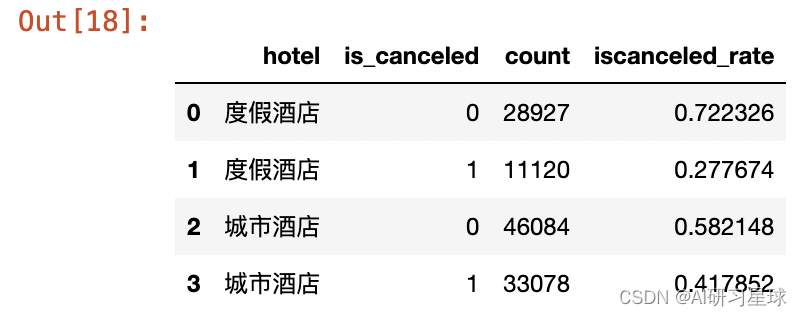
城市酒店的总预订量大,但同时预订取消率也不低,主要是因为城市酒店的主要用户群是商务差旅的用户,往往具有紧急性及未规划性,酒店的预订在未规划及深入了解酒店状态情况下,容易盲目预订、退订,所以退订率高,建议在在渠道平台增加“附近优选”功能,通过输入地址,自动筛选推荐附近城市酒店的入住率高、复住率高、评价高等高品质回馈的城市酒店,一方面能为用户提供更高效便捷的推荐服务,另一方面也促使平台渠道优化服务内容
c. 老客户的复定率怎么样
#核实总的复定率
reversal_book_rate = str(round(data_new.groupby("is_repeated_guest")["is_repeated_guest"].count()[1]/data_new.shape[0]*100,2))+"%"
print("该数据的总复定率:",reversal_book_rate)
该数据的总复定率: 3.19%
#不同酒店类型的复住率
data_rb = data_new.groupby(["hotel","is_repeated_guest"])["hotel"].count()
print("城市酒店的复定率:",data_rb["City Hotel",1]/data_rb["City Hotel"].sum())
print("城市酒店的复定率:",data_rb["Resort Hotel",1]/data_rb["Resort Hotel"].sum())
城市酒店的复定率: 0.02497410373664132
城市酒店的复定率: 0.04439783254675756
城市酒店和度假酒店的复定率均不高,在3%左右,均是自然客流带来的业务,没有较强的粘性.建议:梳理预订入住流程及服务质量反馈渠道,改善提升服务质量;同时在预订分销渠道(如小程序、小视频、各大软文平台、官网)平台植入相关软文,增加曝光量,相应的收集分析看官们的信息抵达率、信息点击率、优惠参与率、软文-消费页面跳转率、最终消费转化率等系列数据,归纳分类高价值渠道、高价值客户,根据活动针对性的提升高价值渠道、高价值客户的投入占比。
5.2 问题分析
#返回酒店列的统计值
data_new["hotel"].value_counts()
#划分城市酒店及度假酒店的数据集
rh = data_new[(data_new["hotel"]=="Resort Hotel") & (data_new["is_canceled"]==0)]
ch = data_new[(data_new["hotel"]=="City Hotel") & (data_new["is_canceled"]==0)]
由于后续均是针对不同酒店进行比较,所以这里会划分度假酒店和城市酒店的数据,同时剔除已经取消的订单记录
问题1
哪些房型的入住率最高,找出最受欢迎的房型,优化酒店房型分配
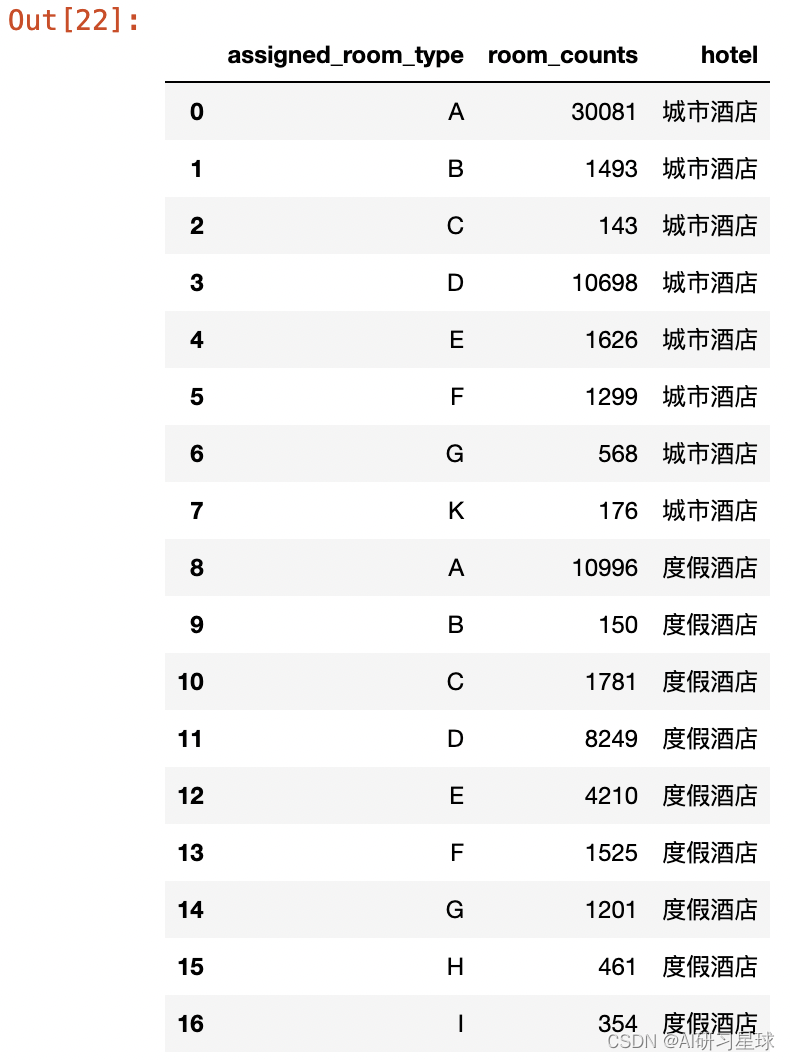
#统计不同酒店、不同房型的入住情况
rh_room = rh.groupby("assigned_room_type")["hotel"].count().reset_index().rename(columns={"hotel":"room_counts"})
ch_room = ch.groupby("assigned_room_type")["hotel"].count().reset_index().rename(columns={"hotel":"room_counts"})
#酒店标识
rh_room["hotel"] = "度假酒店"
ch_room["hotel"] = "城市酒店"
#合并
all_room = pd.concat([ch_room,rh_room],ignore_index=True)
all_room
plt.figure(figsize=(16,8))
sns.barplot(x="assigned_room_type",y="room_counts",hue="hotel",data=all_room,hue_order=["城市酒店","度假酒店"])
plt.title("不同房型的入住数量",fontsize=16)
plt.xlabel("房型",fontsize=16)
plt.ylabel("入住数",fontsize=16)
plt.legend(loc="upper right")
plt.show()
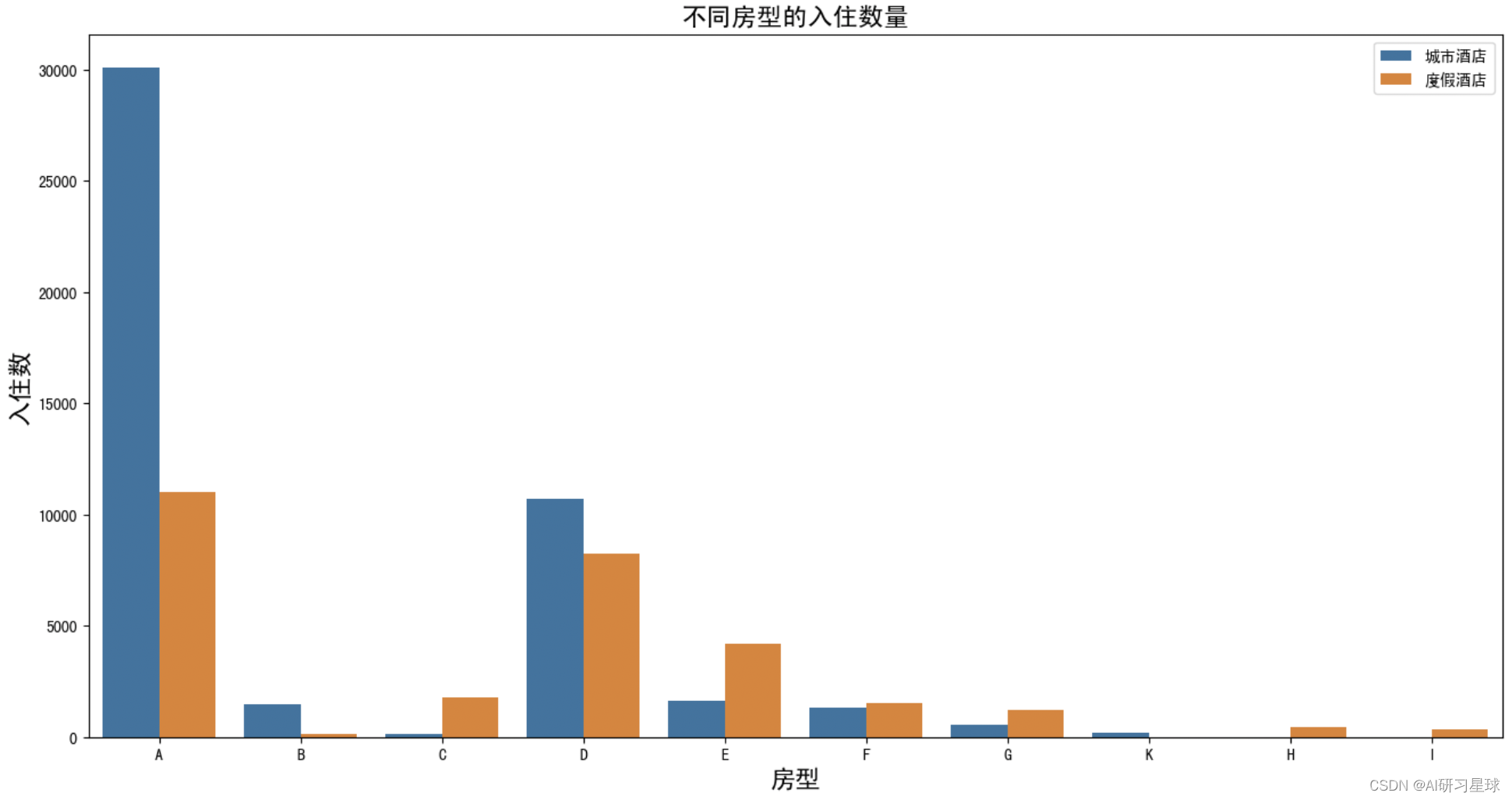
酒店的A和D房型的预订入住量均明显高于其他房型,是后续主推的房型,也是主要的房型优化对象;其余B、C、F、G、H、L房型均没有太多的预订入住量,可以适当调整房型占比,最大化入住率;另度假酒店E房型的的预订入住量数量也不少,可能是酒店的高级套房(带观景台)
结合时间序列,划分为四季,统计分析四季不同酒店类型的入住量变化情况
#对月份进行映射,得到对应的季节
season = {"January":"冬季","February":"春季","March":"春季","April":"春季","May":"夏季","June":"夏季","July":"夏季","August":"秋季","September":"秋季","October":"秋季","November":"冬季","December":"冬季"}
rh["seasons"] = rh["arrival_date_month"].map(season)
ch["seasons"] = ch["arrival_date_month"].map(season)
#结合时序分析不同酒店、房型在四季的入住情况
rh_room_season = rh.groupby(["reserved_room_type","seasons"])["hotel"].count().reset_index().rename(columns={"hotel":"room_counts"})
ch_room_season = ch.groupby(["reserved_room_type","seasons"])["hotel"].count().reset_index().rename(columns={"hotel":"room_counts"})
rh_room_season["hotel"] = "度假酒店"
ch_room_season["hotel"] = "城市酒店"
all_room_season = pd.concat([ch_room_season,rh_room_season],axis=0,ignore_index=True).sort_values("seasons")
plt.figure(figsize=(30,30))
sns.catplot(x="reserved_room_type",y="room_counts",hue="hotel",col="seasons",data=all_room_season,kind="bar",col_order=["春季","夏季","秋季","冬季"],hue_order=["城市酒店","度假酒店"])
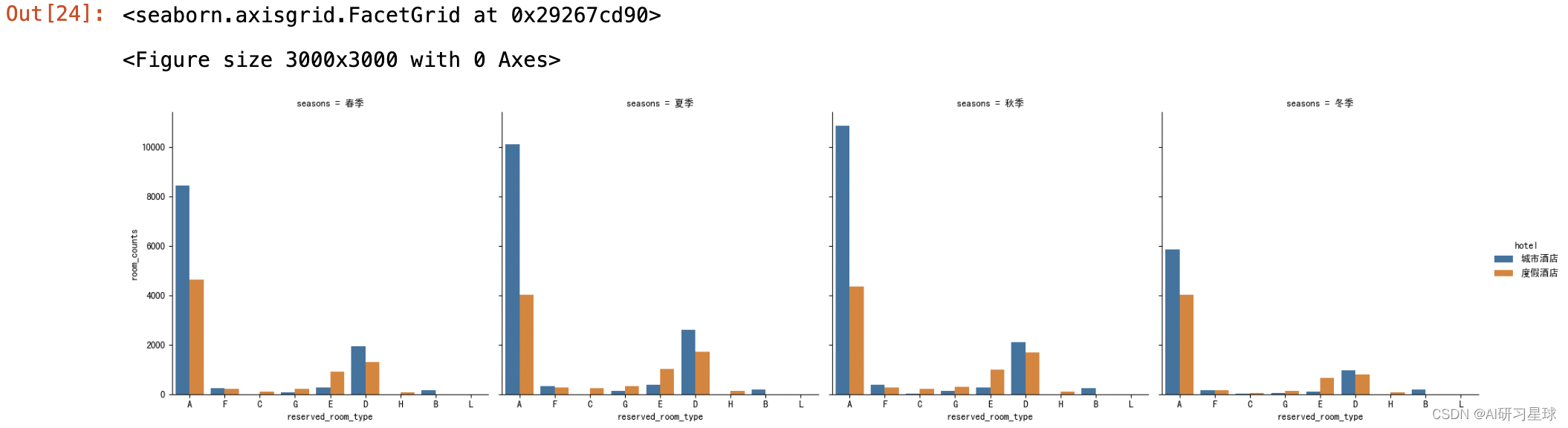
城市酒店的随着季节变化比较明显,春夏秋三季的入住量不断攀升,在夏季达到高峰,而在冬季的客流量则有所缩减;度假酒店的话,则春夏秋季基本保持平稳,凛冬客流减少
问题2
客户入住晚数的需求分布情况怎样,哪些的需求量最大,并统计出这些用户偏爱入住的房型
#统计不同酒店类型每一单的入住居住晚数
rh["total_nights"] = rh["stays_in_weekend_nights"] + rh["stays_in_week_nights"]
ch["total_nights"] = ch["stays_in_weekend_nights"] + ch["stays_in_week_nights"]
#统计不同入住晚数的计量
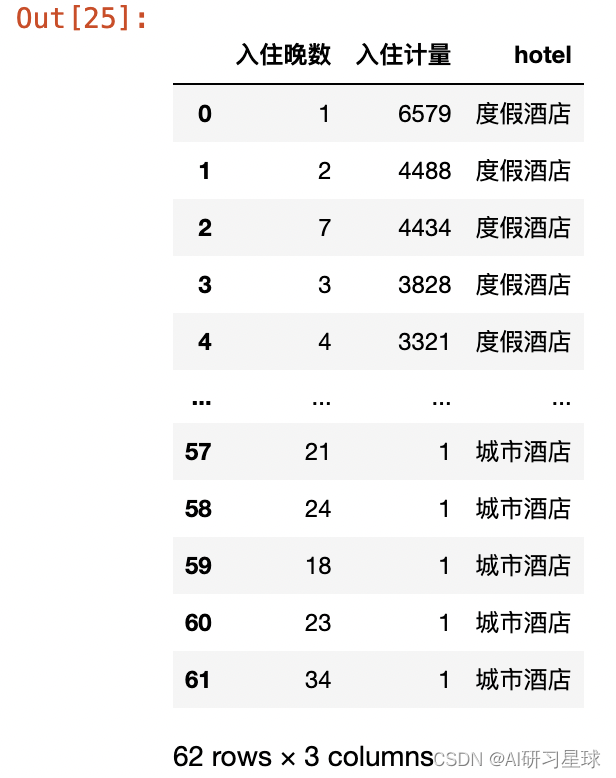
rh_nights_count = rh["total_nights"].value_counts().reset_index().rename(columns={"index":"入住晚数","total_nights":"入住计量"})
ch_nights_count = ch["total_nights"].value_counts().reset_index().rename(columns={"index":"入住晚数","total_nights":"入住计量"})
rh_nights_count["hotel"] = "度假酒店"
ch_nights_count["hotel"] = "城市酒店"
#合并
all_nights_count = pd.concat([rh_nights_count,ch_nights_count],ignore_index=True)
all_nights_count
plt.figure(figsize=(18,6))
sns.barplot(x="入住晚数",y="入住计量",hue="hotel",data=all_nights_count,hue_order=["城市酒店","度假酒店"])
plt.title("住房天数分布",fontsize=16)
plt.xlabel("入住晚数",fontsize=16)
plt.ylabel("入住晚数计量",fontsize=16)
plt.legend(loc="upper right")
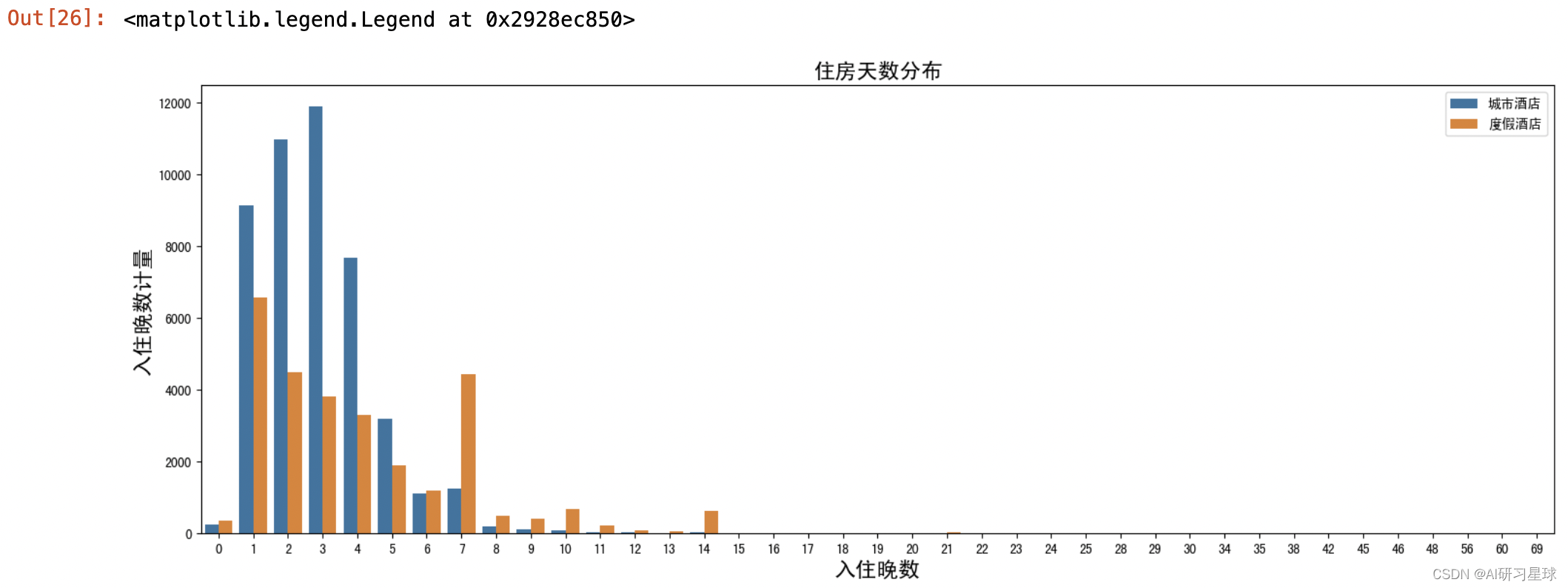
根据入住晚数的统计分析,酒店入住晚数大量分布在1-3晚;同时度假酒店在“7晚预订”上也比较受欢迎,可能是优惠策略带来的正面影响
#度假酒店“7晚预订”的客户偏爱的房型
rh[rh["total_nights"]==7].groupby("reserved_room_type")["hotel"].count()
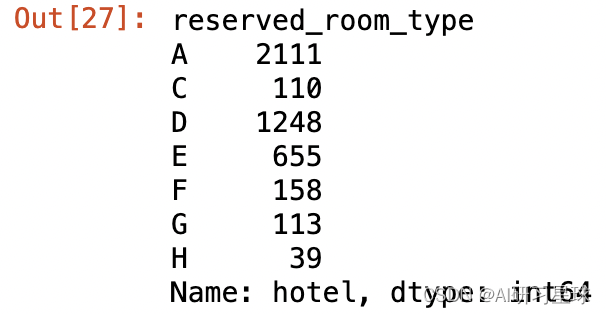
度假酒店“7晚预订”的客户还是比较偏爱A、D、E房型,整体分布没有太大变化
问题3
用户为何取消预订,哪些因素与此最相关,我们如何判断一个预订订单被取消的可能性
① 从“预订房型与提供房型是否一样”考虑,影响退订的可能性
#预订房型和给定房型的数据
assigned_data = data_new[["is_canceled","reserved_room_type","assigned_room_type"]]
#判断预订房型和给定房型是否一致
assigned_data["equal"] = np.where(assigned_data["reserved_room_type"]==assigned_data["assigned_room_type"],1,0)
#统计一致量
assigned_data["equal"].value_counts()

在预订房型和给定房型的差别上,仍有14796单无法满足客户入住需求
#取消订单与房型一致性的关系
assigned_data.groupby(["is_canceled","equal"])["reserved_room_type"].count()

在取消的订单中,预订房型与提供房型不一致的数量有802单,占比取消订单总数的1%,占比如此低,所以不是客户退订的主要因素
②从“提供的餐型”考虑,影响退订的可能性
#餐型数据
meal_data = data_new[["is_canceled","meal"]]
#y表示取消订单,n表示未取消订单,不同餐型的计量
meal_data_y = meal_data[meal_data["is_canceled"]==1].groupby("meal")["meal"].count()
meal_data_n = meal_data[meal_data["is_canceled"]==0].groupby("meal")["meal"].count()
meal_data_n

#预订入住的订单中,各餐型占比情况
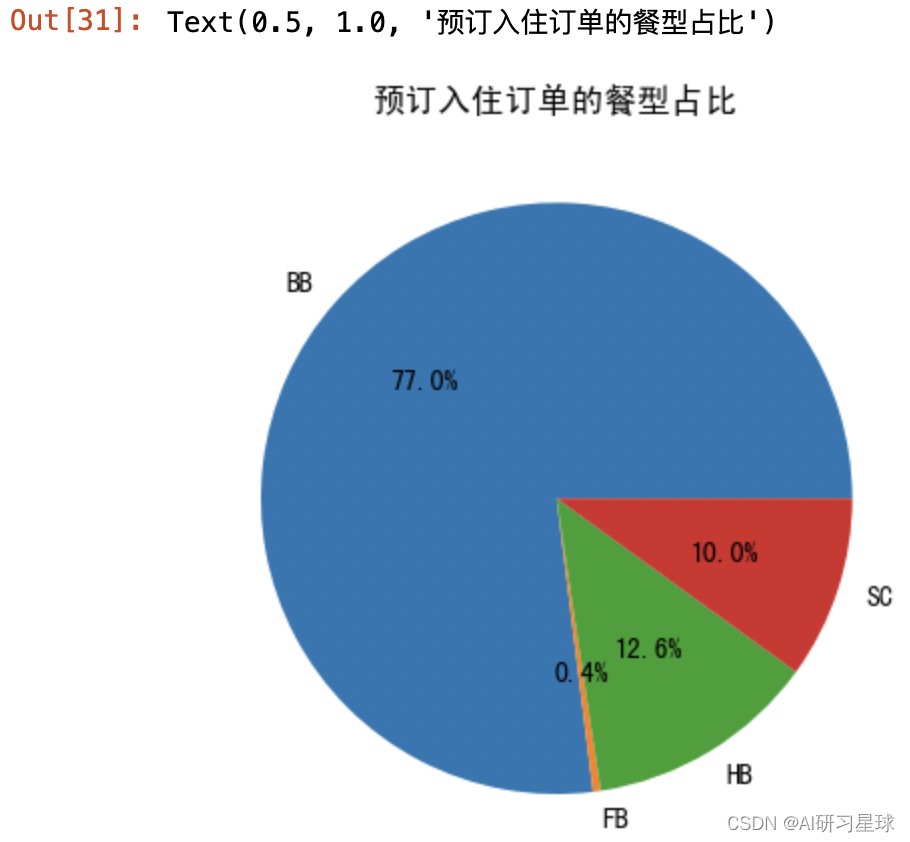
plt.pie(x=meal_data_n.values,labels=meal_data_n.index,autopct="%.1f%%")
plt.title("预订入住订单的餐型占比")
#退订的订单中,各餐型占比情况
plt.pie(x=meal_data_y.values,labels=meal_data_y.index,autopct="%.1f%%")
plt.title("退订订单的餐型占比")
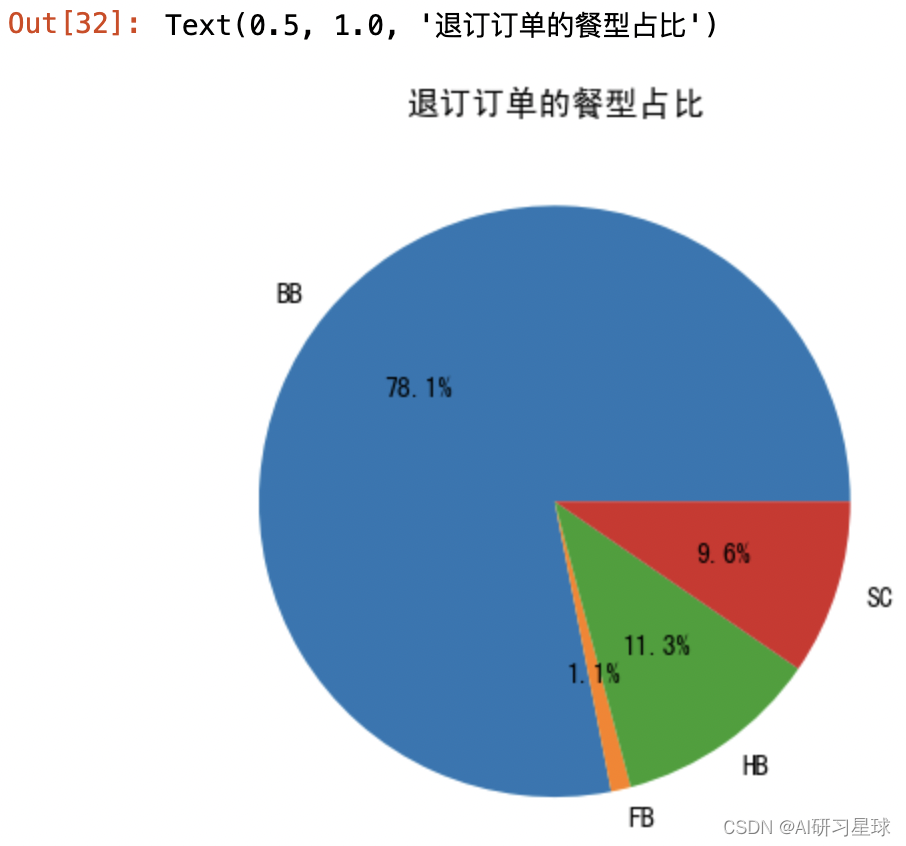
对比退订和预订入住的餐型占比,基本一致,没有太大的出入,所以餐型对预订退订的影响不大,排除是因提供的餐食而导致的退订
③从“分销渠道”考虑,影响退订的可能性
#分销渠道数据
channel_data = data_new[["is_canceled","distribution_channel","hotel"]]
#取消订单与分销渠道的关系
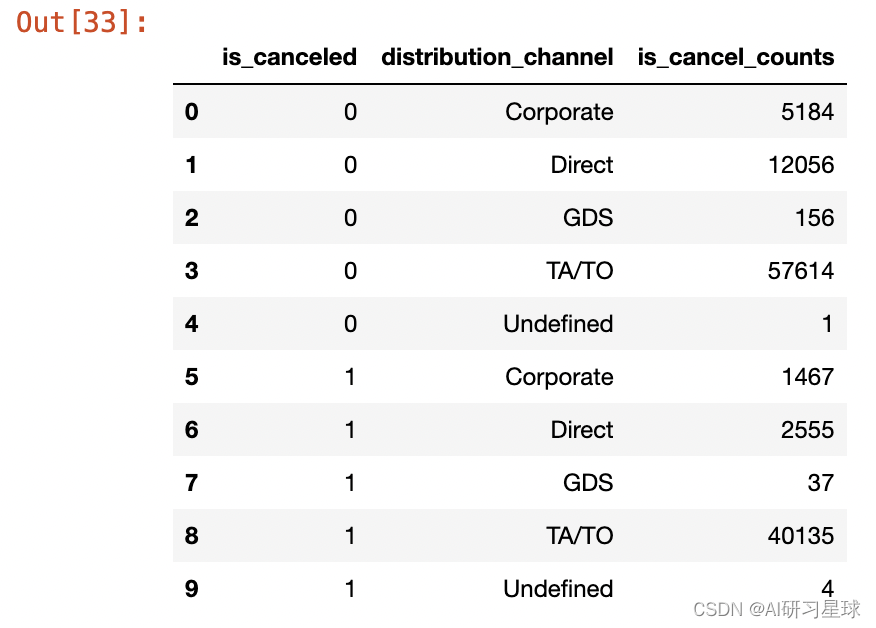
cancel_channel_data = channel_data.groupby(["is_canceled","distribution_channel"])["hotel"].count().reset_index().rename(columns={"hotel":"is_cancel_counts"})
cancel_channel_data
#不同渠道的订单量
all_channel_data = cancel_channel_data.groupby("distribution_channel")["is_cancel_counts"].sum()
all_channel_data
for i in all_channel_data.index:
cancel_num = cancel_channel_data[(cancel_channel_data["is_canceled"]==1) & (cancel_channel_data["distribution_channel"]==i)]["is_cancel_counts"]
all_num = all_channel_data[i]
cancel_rate = cancel_num / all_num * 100
print("%s渠道的退订占比:%.1f%%" % (i,cancel_rate))

对比不同渠道的退订占比,发现"TA/TO"渠道的退订占比高,预订入住量及取消量一半一半,可能是渠道分销奖励机制问题,导致该渠道的预订数据有较大的水分,需进一步核实“TA/TO”渠道的分销流程,及其中存在的问题
④从“预付定金”考虑,影响退订的可能性
#预付定金数据
deposit_data = data_new[["is_canceled","deposit_type","hotel"]]
#取消订单与不同预付定金的关系
cancel_deposit_data = deposit_data.groupby(["is_canceled","deposit_type"])["hotel"].count().reset_index().rename(columns={"hotel":"is_cancel_counts"})
cancel_deposit_data
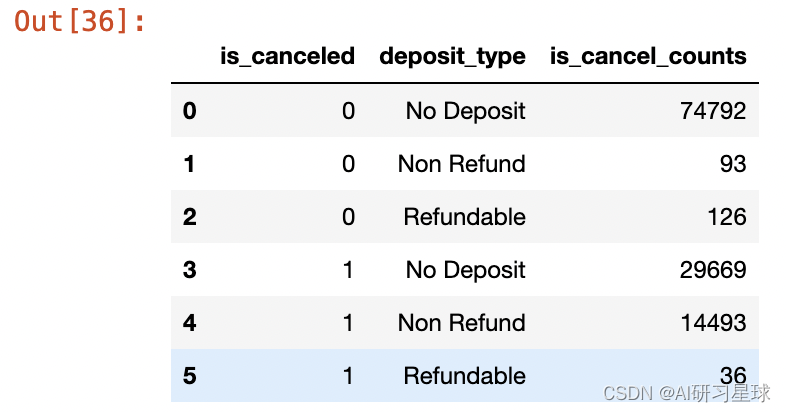
根据上表,客户更偏爱无定金的预订。但其中仍有大量预付定金的客户选择取消订单,需进一步根据用户画像判断该部分退订客户的属性特征,亦可结合退订的时间分布、位置分布,分析退订的原因
⑤从“提前预定的时间”考虑,影响退订的可能性
#提前预定时长的数据
lead_data = data_new.groupby("lead_time")["is_canceled"].describe().sort_values(by="mean",ascending=False)
#剔除提前预定时长小于10的数据
lead_data_10 = lead_data[lead_data["count"]>10]
#提前预定时长
x = lead_data_10.index
#对应取消数(按比例归纳值100以内)
y = round(lead_data_10["mean"],4)*100
plt.figure(figsize=(12,6))
sns.regplot(x=x,y=y)
plt.title("提前预定时长对取消的影响",fontsize=16)
plt.xlabel("提前预定时长",fontsize=16)
plt.ylabel("取消数(%)",fontsize=16)
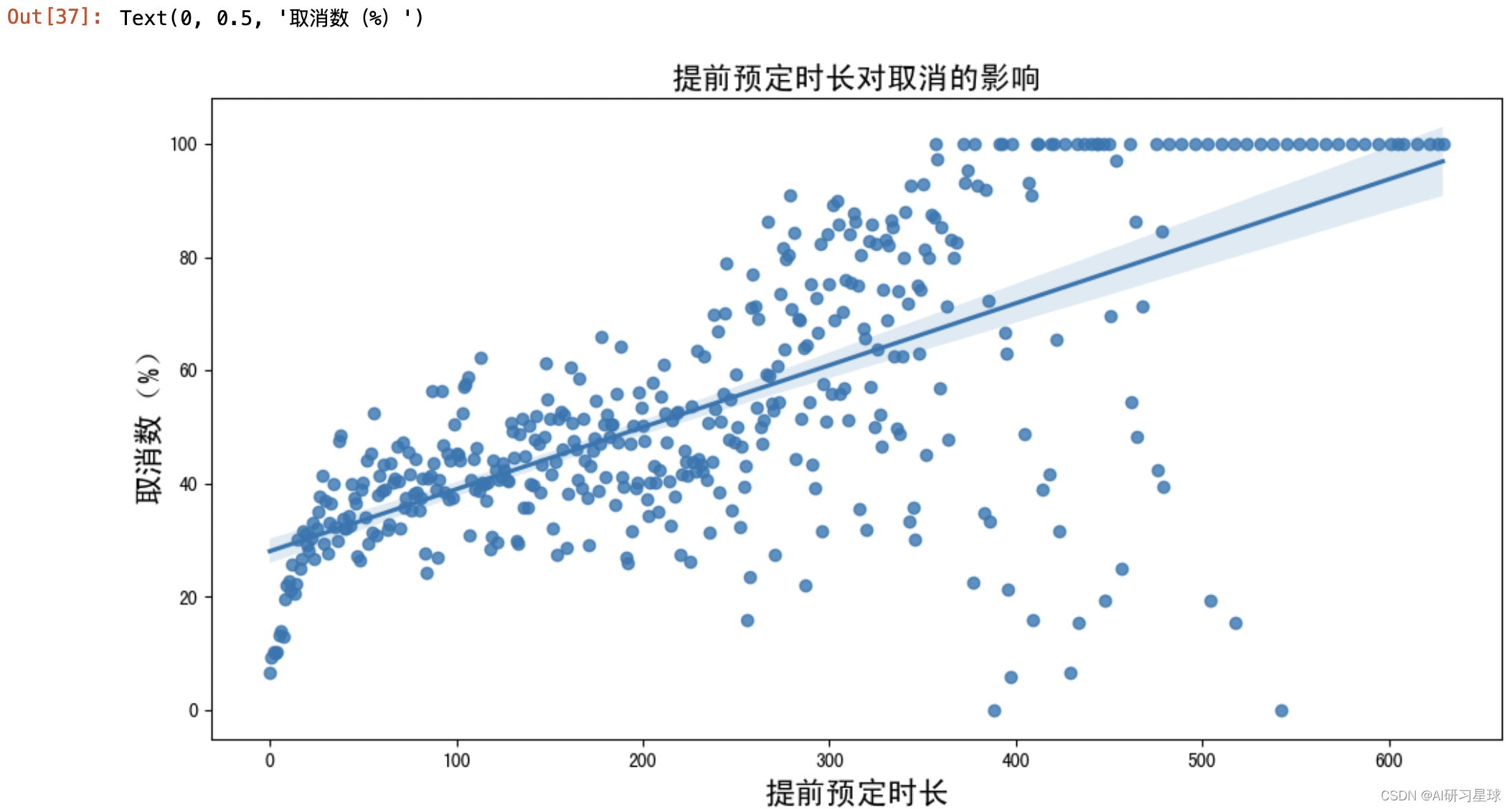
根据数据分布情况,整体有随着“提前预定时长”的增加,“取消数”亦增加的规律,两者呈现正相关。所以一般越早预定,也越容易取消。对于这部分影响,建议组织人员对预定日期为“淡季的客户”提前再确认预定入住时间,同时根据优惠策略(提前入住时间越大,优惠越大)释放让利信号,让客户主动提前预定入住的时间
⑥其他影响因素
cancel_corr = data_new.corr()["is_canceled"].abs().sort_values(ascending=False)
cancel_corr

一般来说,相关系数大于0.8时,两者间的相互影响越大
根据上表,影响取消数的主要属性是:
- lead_time:提前预定天数
- total_of_special_requests:客户提出的特殊要求的数量
- required_car_parking_spaces:客户要求的停车位数
- booking_changes:对预订所作的更改/修改的数目
- previous_cancellations:客户在当前预订前取消的先前预订数
关注公众号:『AI学习星球』
回复:酒店预订需求 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或?v:codebiubiu滴滴我
6. 数据建模
由于酒店的服务大多是预订服务,需提前预约保留预约信息。如果酒店的预约被取消,则可能存在隐性的问题,这时需要我们提前对退订的订单做预测,提前发现存在的问题
from sklearn.feature_extraction import DictVectorizer #标称型特征向量化
from sklearn.compose import ColumnTransformer #特征列处理
from sklearn.pipeline import Pipeline #数据转换、模型多步骤处理
from sklearn.impute import SimpleImputer #填充缺失值
from sklearn.preprocessing import StandardScaler, OneHotEncoder #标准化、向量化
from sklearn.model_selection import train_test_split, GridSearchCV #划分训练集、网络检索(参数调优)
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.linear_model import LogisticRegression #逻辑回归
其中建模的流程主要:
- 特征提取及预处理
- 划分样本特征和样本结果
- 划分训练集和测试集
- 模型搭建并评估
- 模型参数调优
①特征提取、向量化、标准化
由于数值型特征的单位量纲均不一样,模型拟合时容易偏拟合,所以需要做归一化处理,统一量纲,并保留数据规律
#数值型特征标准化过程
num_feature = ["lead_time","stays_nights_total","stays_in_weekend_nights","stays_in_week_nights","number_of_people","adults","children","babies","is_repeated_guest","previous_cancellations","previous_bookings_not_canceled","booking_changes","agent","days_in_waiting_list","adr","required_car_parking_spaces","total_of_special_requests"]
num_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
在模型拟合时,模型无法对复杂的标称型特征做拟合,所以需要优先对该类数据进行向量化处理,转化为模型容易辨识的数值型特征
#标称型特征向量化过程
cat_feature = ["hotel","meal","country","market_segment","distribution_channel","reserved_room_type","assigned_room_type","deposit_type","customer_type"]
cat_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
注意:由于DictVectorizer只能处理标称型特征变量,且处理量有限,不建议使用
数值型变量和标称型变量同步于一个预处理器。
#数值型变量和标称型变量分别做标准化、向量化预处理
preprocessor = ColumnTransformer(
transformers=[
('num', num_transformer, num_feature),
('cat', cat_transformer, cat_feature)]) #预处理器
②划分样本特征和样本结果
feature = num_feature + cat_feature
#样本特征
X = data_new.drop("is_canceled",axis=1)[feature]
#样本结果
y = data_new["is_canceled"]
③划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
④模型搭建并评估
由于电脑配置有限,暂时以决策树、随机森林、逻辑回归算法做分类预测
base_models = [("DT_model", DecisionTreeClassifier(random_state=42)),
("RF_model", RandomForestClassifier(random_state=42,n_jobs=-1)),
("LR_model", LogisticRegression(random_state=42,n_jobs=-1))] #模型
for name,model in base_models:
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', model)])
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print("%s score: %.3f" % (name,score))

模型选择了决策树、随机森林和逻辑回归,分别对模型拟合效果评分,显然“随机森林”的评分0.889,拟合效果更好
⑤模型参数调优
参数调优可以使用GridSearchCV,但在参数数量选择上,不建议太多,否则数据处理量太多,速度会很慢。对应该模型,参数选择"n_estimators":决策树的量;“max_depth”:决策树的深度(预剪枝);“max_features”:选择的最大特征量
rf = RandomForestClassifier()
#参数选择
param_dict = {"n_estimators":[100,150,200],"max_depth":[3,5,8,10,15],"max_features":["auto","log2"]}
#网络搜索调优器
rf_model = GridSearchCV(rf,param_grid=param_dict,cv=3)
#模型拟合
CLF = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', rf_model)])
CLF.fit(X_train, y_train)
不同模型参数下,最好的评分及其参数
CLF.best_score_
CLF.best_params_
由于处理速度有限,本次只使用一下参数调优
rf_model = RandomForestClassifier(n_estimators=160,
max_features=0.4,
min_samples_split=2,
n_jobs=-1,
random_state=0)
CLF = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', rf_model)])
CLF.fit(X_train, y_train)
CLF.score(X_test, y_test)
结果:
0.88562201157621
关注公众号:『AI学习星球』
回复:酒店预订需求 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或?v:codebiubiu滴滴我
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!