【改进】YOLOv7-tiny使用YOLOX的DecoupledHead,能涨点1~3个(附测试时的报错及解决方案:RuntimeError: Expected all tensors to be )
发布时间:2024年01月14日
文章目录
1 改进方式(YOLOv7应该也适用)
1.0 参考链接
1.0 改进后参数量为13.51M,计算量为54.7GFLOPs
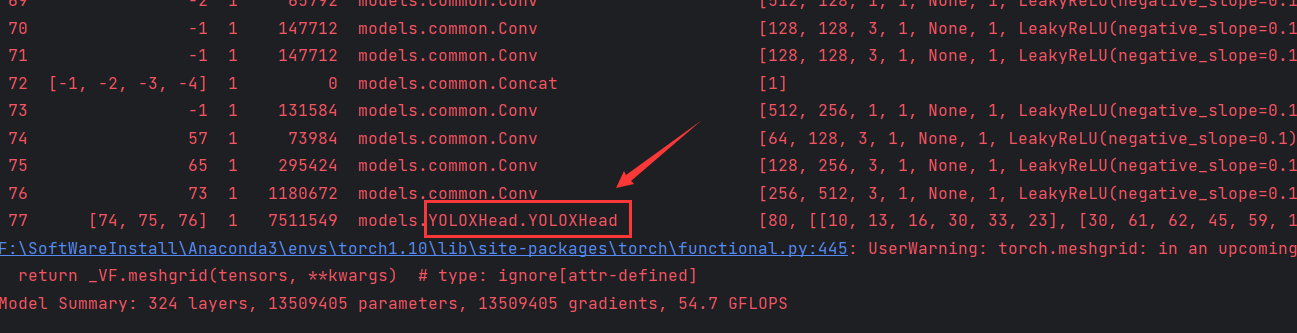
1.1 在models下面添加一个YOLOXHead.py
# 参考:https://blog.csdn.net/weixin_43694096/article/details/127427578
# 注意:记得打开yolo.py里面的729行代码:self._initialize_biases()
import torch
import torch.nn as nn
from models.common import Conv
import pkg_resources as pkg
def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
current, minimum = (pkg.parse_version(x) for x in (current, minimum))
result = (current == minimum) if pinned else (current >= minimum) # bool
s = f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed' # string
if hard:
assert result, s
return result
class DecoupledHead(nn.Module):
#代码是参考啥都会一点的老程大佬的 https://blog.csdn.net/weixin_44119362
def __init__(self, ch=256, nc=80, width=1.0, anchors=()):
super().__init__()
self.nc = nc # number of classes
self.nl = len(anchors) # number of detection layers 3
self.na = len(anchors[0]) // 2 # number of anchors 3
self.merge = Conv(ch, 256 * width, 1, 1)
self.cls_convs1 = Conv(256 * width, 256 * width, 3, 1, 1)
self.cls_convs2 = Conv(256 * width, 256 * width, 3, 1, 1)
self.reg_convs1 = Conv(256 * width, 256 * width, 3, 1, 1)
self.reg_convs2 = Conv(256 * width, 256 * width, 3, 1, 1)
self.cls_preds = nn.Conv2d(256 * width, self.nc * self.na, 1)
self.reg_preds = nn.Conv2d(256 * width, 4 * self.na, 1)
self.obj_preds = nn.Conv2d(256 * width, 1 * self.na, 1)
def forward(self, x):
x = self.merge(x)
# 分类=3x3conv + 3x3conv + 1x1convpred
x1 = self.cls_convs1(x)
x1 = self.cls_convs2(x1)
x1 = self.cls_preds(x1)
# 回归=3x3conv(共享) + 3x3conv(共享) + 1x1pred
x2 = self.reg_convs1(x)
x2 = self.reg_convs2(x2)
x21 = self.reg_preds(x2)
# 置信度=3x3conv(共享)+ 3x3conv(共享) + 1x1pred
x22 = self.obj_preds(x2)
out = torch.cat([x21, x22, x1], 1)
return out
class YOLOXHead(nn.Module):
stride = None # strides computed during build
export = False # onnx export
end2end = False
include_nms = False
concat = False
def __init__(self, nc=80, anchors=(), Decoupled=False, ch=()): # detection layer
super(YOLOXHead, self).__init__()
self.decoupled = Decoupled
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
# self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.m = nn.ModuleList(DecoupledHead(x, nc, 1, anchors) for x in ch)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else:
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = xy * (2. * self.stride[i]) + (self.stride[i] * (self.grid[i] - 0.5)) # new xy
wh = wh ** 2 * (4 * self.anchor_grid[i].data) # new wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z,)
elif self.concat:
out = torch.cat(z, 1)
else:
out = (torch.cat(z, 1), x)
return out
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def convert(self, z):
z = torch.cat(z, 1)
box = z[:, :, :4]
conf = z[:, :, 4:5]
score = z[:, :, 5:]
score *= conf
convert_matrix = torch.tensor([[1, 0, 1, 0], [0, 1, 0, 1], [-0.5, 0, 0.5, 0], [0, -0.5, 0, 0.5]], dtype=torch.float32, device=z.device)
box @= convert_matrix
return (box, score)
1.2 在models/yolo.py做如下更改
- 添加头文件
from models.YOLOXHead import YOLOXHead
- 找到第一个
if isinstance(m, Detect)然后改为下面的样子
if isinstance(m, Detect) or isinstance(m, YOLOXHead):
- 在
2里面的代码块里,将self._initialize_biases() # only run once注释掉。2、3两处改动后如下图所示:
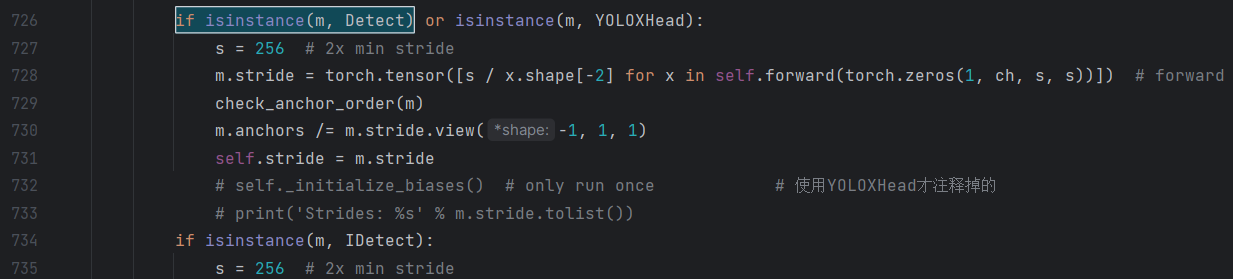
4. 定位到elif m in [Detect, IDetect, IAuxDetect, IBin, IKeypoint然后加上YOLOXHead

#------------------------以上就是我的改动----------------------------#
#------------------------下面这一个我现在觉得也应该改,改了的话可能测试的时候就不会报错了,因为以往按照博客改头都还有这个地方要改,如果这样改有错的话就不要这一步吧,看文章的朋友们自行选择----------------------------#
- 定位到
if self.traced:,在下面一行代码的后面加上or isinstance(m, YOLOXHead)
1.3 在cfg/training里添加yolov7-tiny-YOLOXHead.yaml文件
- 只在最后一行有改动,把
IDetect改为了YOLOXHead,还接了一个True参数
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, Conv, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2
[-1, 1, Conv, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------ELAN Backbone-1
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7 ------------ELAN Backbone-1 end
[-1, 1, MP, []], # 8-P3/8
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------ELAN Backbone-2
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14 ----------ELAN Backbone-2 end
[-1, 1, MP, []], # 15-P4/16
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # --------------ELAN Backbone-3
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21 ----------ELAN Backbone-3 end
[-1, 1, MP, []], # 22-P5/32
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # --------------ELAN Backbone-4
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28 ----------ELAN Backbone-4 end
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------SPP
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 37 -----------------SPP end
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[21, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ----------------------ELAN FPN
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 47 -----------------ELAN FPN end
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[14, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]], # ---------------------------FPN end---------------
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-1
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 57 -----------------ELAN PAN-1 end
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 47], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-2
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 65 -----------------ELAN PAN-2 end
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 37], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # ---------------------ELAN PAN-3
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 73 -----------------ELAN PAN-3 end
[57, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[65, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[73, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[74,75,76], 1, YOLOXHead, [nc, anchors, True]], # Detect(P3, P4, P5)
]
2 测试时可能遇到的报错、解决方案
2.1 报错
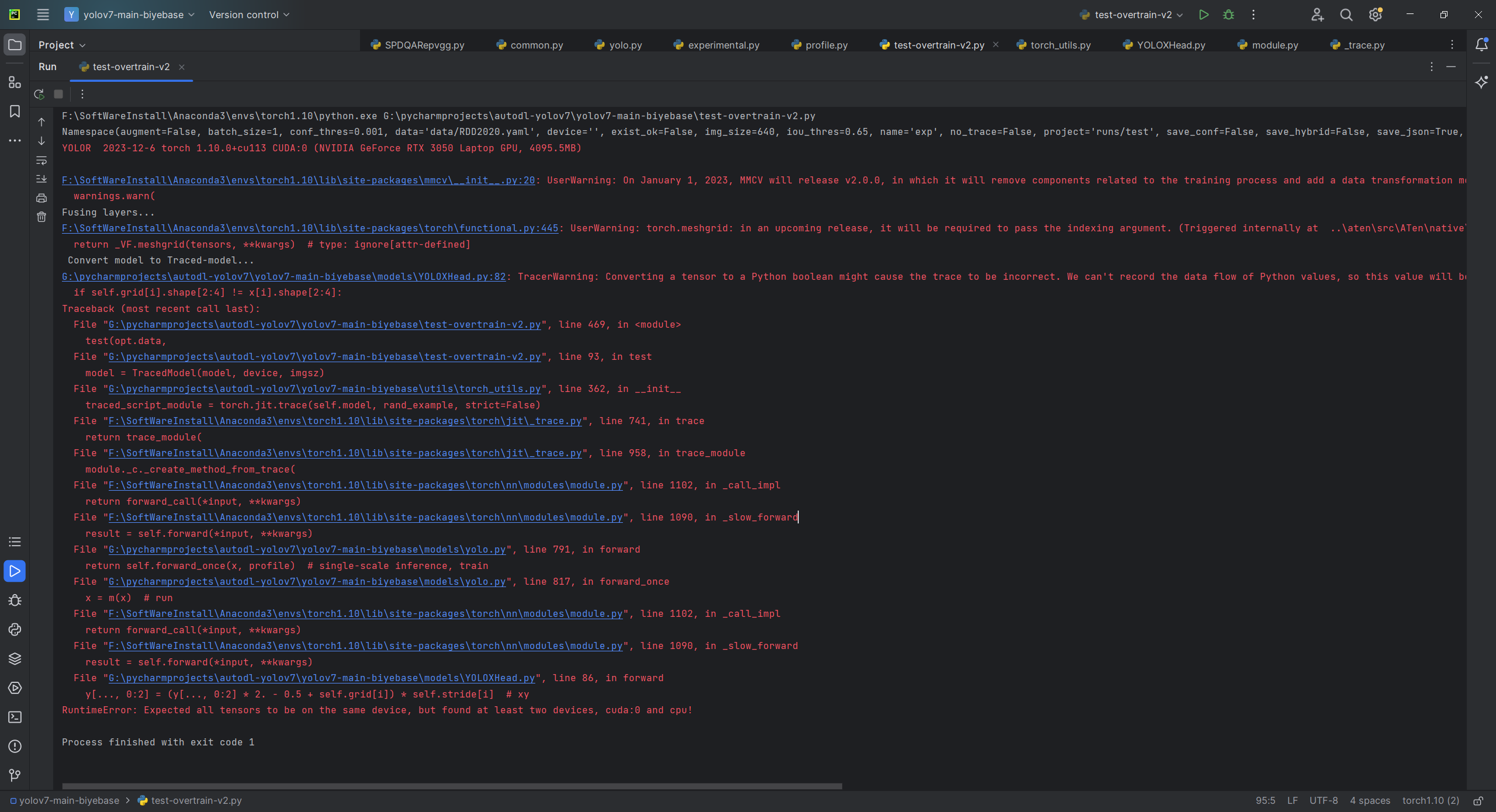
调用test.py进行测试时,可能会报错:RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
2.2 解决方案
- Debug发现在
test.py的如下位置出错。这行代码不知道是为了干啥,好像是为了生成追踪模型,但是对我没用,反而还造成测试时出错,因此直接将它注释掉了,注释掉之后就能正常测试出结果了 - 尝试了其他权重的预测结果,精度map50等完全没有差异,所以放心注释掉吧
- 但是好像会影响FPS,traced之后的模型FPS会快一点
- 但是建议测试完YOLOXHead结果之后,还是把下面两行代码重新打开,尽量保持源码的原貌,以免后续测试其他改进模型时出岔子
if trace:
model = TracedModel(model, device, imgsz)
文章来源:https://blog.csdn.net/LWD19981223/article/details/135522133
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 做现货黄金投资如何自我监测
- 易点易动固定资产管理系统:全员盘点与员工自助,高效管理与盘点固定资产
- 剪映全能操作手册,全网最全剪映速成教程来了,小白必备!
- Python模块相对导入
- 轻量级全功能开源免费Mailu邮件服务器部署
- 随机问卷调查数据的处理(uniapp)
- 爬虫 resquests模块与get请求和post请求
- [足式机器人]Part2 Dr. CAN学习笔记-自动控制原理Ch1-8Lag Compensator滞后补偿器
- 基于SpringBoot的药品管理系统
- 计算机网络、浏览器相关高频面试题