#AIGC#text2video文生视频,开源DragNUWA:通过集成文本、图像和轨迹对视频生成进行细粒度控制
发布时间:2024年01月16日
DragNUWA:通过集成文本、图像和轨迹对视频生成进行细粒度控制
论文地址:https://arxiv.org/abs/2308.08089
DragNUWA 使用户能够直接操纵图像中的背景或对象,模型将这些动作无缝地转换为相机运动或对象运动,生成相应的视频。
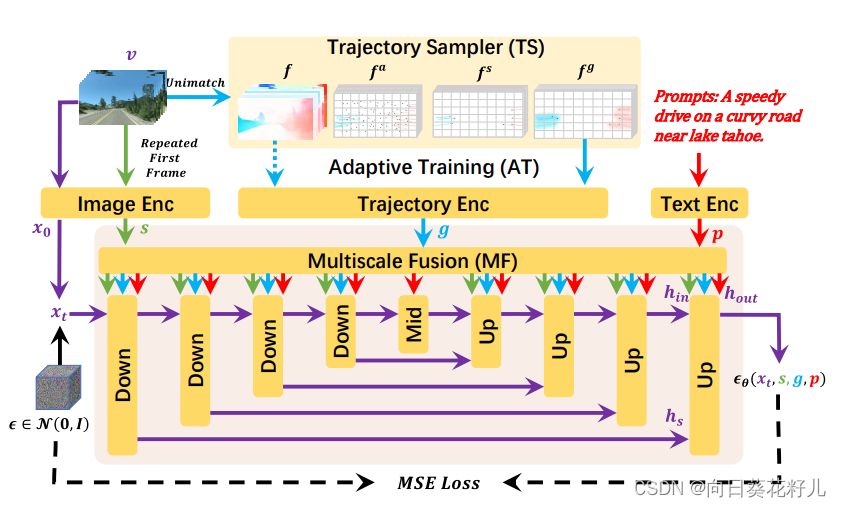
DragNUWA,一个开放域的视频生成模型。为了解决现有作品中控制粒度不足的问题,我们同时引入文本、图像和轨迹信息,从语义、空间和时间的角度对视频内容进行细粒度的控制。为解决目前研究中的有限开放域射控问题,我们模型的轨迹有三个方面:一个轨迹采样器(TS),使开放域控制的任意轨迹,多尺度融合(MF)控制在不同粒度的轨迹,和自适应训练
(AT)策略,以产生一致的视频轨迹。
这里是引用

效果
拖动形成轨迹,轨迹形成视频、 变化相机角度
以拖动(drag)的方式给出运动轨迹,DragNUWA 是一个集成了文本、图像和轨迹控制的系统,可以从语义、空间和时间的角度实现可控的视频生成。




方法
该研究认为文本、图像、轨迹这三种类型的控制是缺一不可的,因为它们各自有助于从语义、空间和时间角度控制视频内容。如下图 1 所示,仅文本和图像的组合不足以传达视频中存在的复杂运动细节,这可以用轨迹信息来补充;仅图像和轨迹组合无法充分表征视频中的未来物体,文本控制可以弥补这一点;在表达抽象概念时,仅依赖轨迹和文本可能会导致歧义,图像控制可以提供必要的区别。
有以拖动(drag)的方式给出运动轨迹、「变换」静态景物图像的相机位置和角度等各种使用方式


轨迹建模
- 使用轨迹采样器(Trajectory Sampler,TS)在训练期间直接从开放域视频流中采样轨迹,用于实现任意轨迹的开放域控制;
- 使用多尺度融合(Multiscale Fusion,MF)将轨迹下采样到各种尺度,并将其与 UNet 架构每个块内的文本和图像深度集成,用于控制不同粒度的轨迹;
- 采用自适应训练(Adaptive Training,AT)策略,以密集流为初始条件来稳定视频生成,然后在稀疏轨迹上进行训练以适应模型,最终生成稳定且连贯的视频。
仓库地址:https://github.com/ProjectNUWA/DragNUWA
文章来源:https://blog.csdn.net/weixin_45312236/article/details/135617394
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【源码分析】一个flink job的sql到底是如何执行的(一):flink sql底层是如何调用connector实现物理执行计划的
- Latex使用BibTeX添加参考文献,保持专有名词原格式,如全部大写方法
- 七:Day01_Java9—16新特性
- 在线文本差异对比工具
- 创建链表时的一个小bug
- 如何用Airtest脚本连接无线Android设备?
- 【图像拼接】论文精读:Robust image stitching with multiple registrations(RISwMR)
- 软件测试|PyQt5实战教程(一)安装与环境配置
- 美易平台:美股盘前,热门中概股多数上涨
- 解析:Eureka的工作原理