基于Python的电商平台淘宝商品评论数据采集与分析
 引言
引言
在电商竞争日益激烈的情况下,商家既要提高产品质量,又要洞悉客户的想法和需求,关注客户购买商品后的评论,而第三方API接口商家获取商品评价主要依赖于人工收集,不但效率低,而且准确度得不到保障。通过使用Python网络爬虫技术采集近期店铺商品评论信息,进行数据清洗、分词、去除停用词、词频统计等数据预处理,最终绘制词云图实现数据可视化,并对数据结果进行分析,为商家提高选品质量、制定个性化的营销策略提供依据。
数据处理
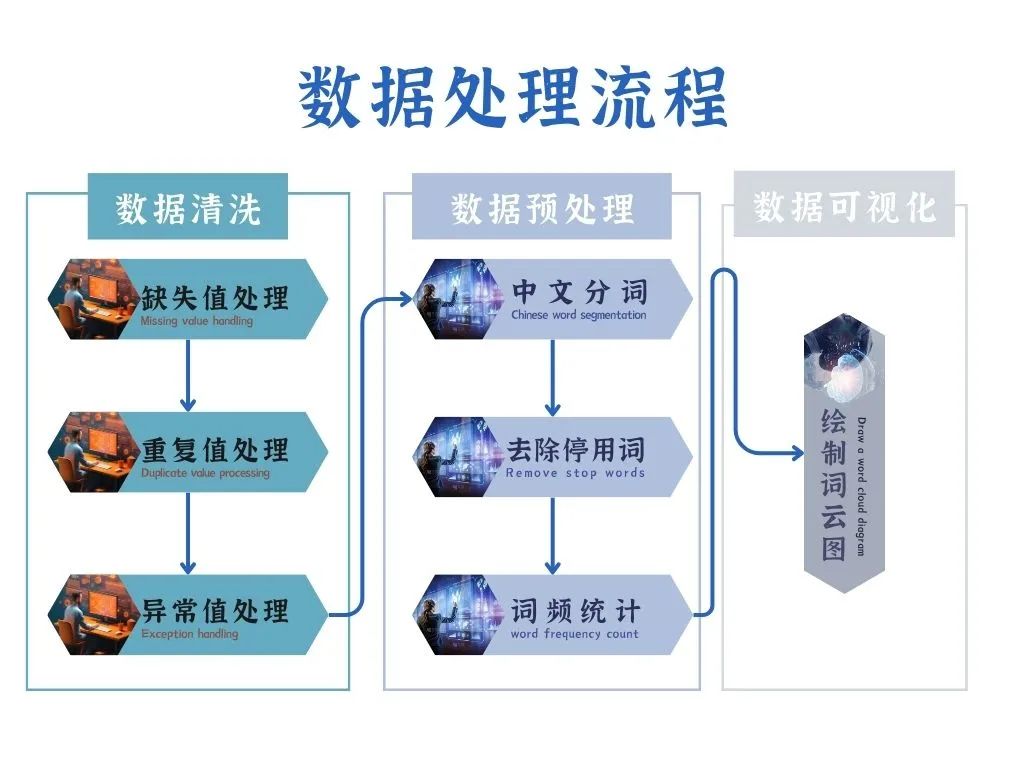
网络爬虫程序采集到的文本数据可能会出现“脏数据”,因此需要对其进行数据清洗,包括去除缺失值、重复值及异常值,还需要对清洗过的数据进行中文分词、去除停用词和词频统计等操作,最后绘制词云图以实现数据可视化。
Data Cleaning
数据清洗
数据清洗包括对缺失值、重复值和异常值的处理。
缺失值处理
采集到的评论数据中可能存在一些空值,因此需要对其进行缺失值处理。在pandas库中,可以使用isna()方法查找缺失值,返回缺失数据用True表示。由于缺失值占总数据量的比重比较低,将有空值的评论记录删除后并不会妨碍后续的数据分析,故使用dropna()方法直接删除有缺失值的数据。
重复值处理
当不同客户对于某个商品发布完全相同的评论时,需要对这些数据做去重处理。利用pandas库的duplicated()方法可以查找重复数据,返回重复值用True来表示。使用drop_duplicates()方法能直接删除重复的评论数据。
异常值处理
数据中有一个或多个数值超出了实际的限定范围,这样的数值称为异常值。在爬取的评论数据中存在“此用户没有填写评价”的系统自动好评,该值对后期数据分析没有实际作用,因此需要对其进行过滤,以清除异常值。
data preprocessing
数据预处理
对清洗后的评论数据还需要做中文分词、去除停用词、词频统计等处理,为后期绘制词云图打下基础。
中文分词
中文分词是将一个汉字序列分割成一个个单独的词,其过程是将连续的字序列按照一定的规范重新组合成词序列。中文分词的方法可以分为基于字符串匹配的分词、基于理解的分词和基于统计的分词。在此使用基于字符串匹配的分词方法,也就是按照一定的策略将待分析的汉字串与一个机器词典中的词条进行匹配,如果在词典中找到某个字符串,则匹配成功,即辨识出一个词。
去除停用词
为节省存储空间和提高搜索效率,搜索引擎在处理搜索请求时会自动忽略某些不重要的字或词,这些字或词就是停用词。停用词主要分为两类,一类是应用广泛但实际难以帮助搜索引擎缩小搜索范围,甚至会降低搜索效率的词,例如,“Web”;另一类是自身没有明确意义的词,包括助词、副词、介词、连接词等,这类词出现的频率较高,但对后续的数据分析没有实际价值,因此需要去除。
词频统计
对评论数据去除停用词后,需要对数据中词出现的频率进行统计。词的总数为不重复的词语数量的总和,为后续的绘制词云图做准备,这里用的是collection模块的Counter方法,筛选出词频排名前100的词。
Data visualization
数据可视化
词云图是对文本数据中出现频率较高的关键词进行视觉上的突出,形成“关键词的渲染”,就像云一般的彩色图片,从而过滤掉大量无效的文本信息,让用户从词云图中能快速感知突出的文字,迅速抓住重点,了解主旨。
数据分析
从绘制的手机正面评价词云图中可以看出,“漂亮”“性价比”“流畅”“满意”“很快”“清晰”等词出现的频率较高,由此可知写好评的客户对该款手机的外观和性能给予很高的评价。有些商家只关心中差评而忽视了好评,这种想法是不全面的,对于好评的分析能够让商家更深入地了解商品的使用场景及客户对产品的关注点,这里从词云图中可以获悉客户在好评中主要关注的是手机的外观、功能、性能、质量和价格。

从酒店负面评价词云图中可以看出“吵”“很差”“脏”“失望”“陈旧”“贵”“味道”等词出现的频率比较高,给出中差评的客户对于酒店的设施、环境和价格表示不满和失望。对于负面评价词云图的分析能够让卖家快速定位产品的不足之处,为进一步提升产品和服务质量指明方向。


结语
为提升电商平台第三方商家收集商品评论信息的效率,获取具有参考价值的选品指标和客户需求,实现更好的收益,在此使用Python网络爬虫技术对店铺商品评论数据进行采集和保存,对爬取的评论记录进行数据清洗、中文分词、去除停用词、词频统计等预处理操作,并以此为基础绘制词云图,实现数据可视化。根据正负面词云图对客户评论做进一步分析,以获取客户的实际需求和商品需要优化的方向,帮助商家掌握核心卖。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- flutter开发windows桌面软件,使用Inno Setup打包成安装程序,支持中文
- 2. seaborn-可视化分类数据
- pytorch中池化函数详解
- 【Java基础】HashMap 原理
- 企业上云,选择阿里云靠谱吗?
- 【深度学习之边缘检测】
- Hologres V2.1版本发布,新增计算组实例构建高可用实时数仓
- 代码随想录算法训练营第六十天|84.柱状图中最大的矩形
- 数学的雨伞下:理解世界的乐趣
- 2010-2020年中国1km陆地生态系统碳汇