【Hadoop精讲】HDFS详解
目录
理论知识点

角色功能

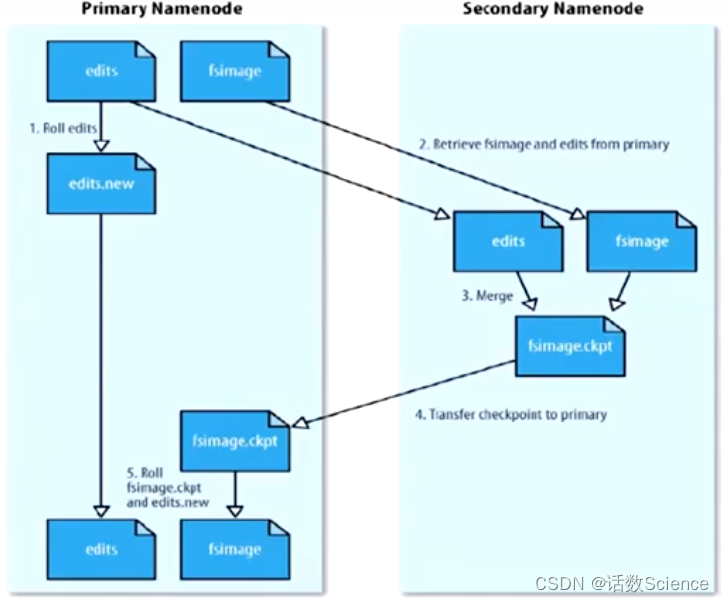
元数据持久化


 另一台机器就是SecondaryNameNode(SNN)
另一台机器就是SecondaryNameNode(SNN)
安全模式


 不保存位置信息的原因,是因为当机器重启恢复后,DN会和NN建立心跳,汇报块信息。这个过程叫安全模式。?
不保存位置信息的原因,是因为当机器重启恢复后,DN会和NN建立心跳,汇报块信息。这个过程叫安全模式。?
SecondaryNameNode(SNN)
非HA模式下才有,SNN跟版本没有关系,企业一般不用SNN,而用高可用HA方式。

副本放置策略
塔式服务器:竖的,价格便宜
机架服务器:扁的,价格中等,最上面放一个交换机,ups(电源,电池防断电)
刀片服务器:插入的,价格较贵

2.x修正为第二个副本立即出机架,因为有可能把副本数修改为2

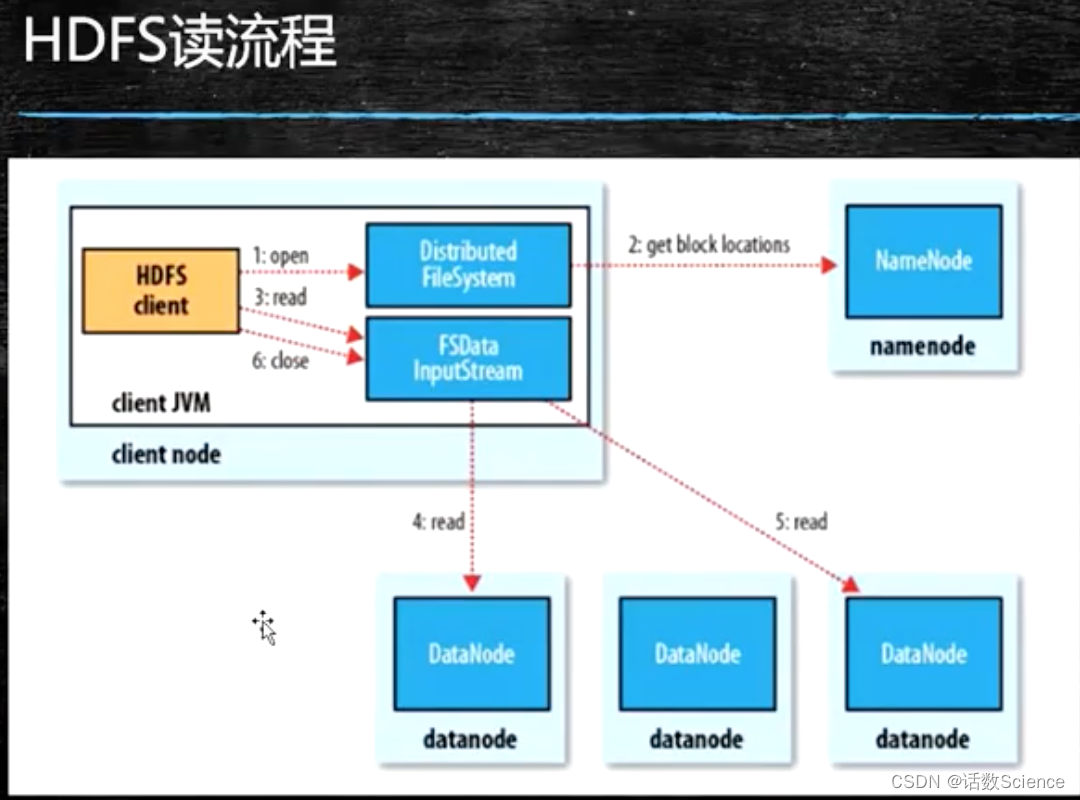
HDFS写流程
某个时间点,传其中一个block的时候状态图
client向NN请求创建文件,这个时候NN返回副本放置策略,按距离排序


HDFS读流程

HA高可用
主从:单点故障、压力过大、内存受限

2.x匆匆上线HA,只实现了一主一备,3.0之后一周多备,可以支持5个,官方推荐3个


一份为二,上面蓝色是故障切换自动化,下面是手动的HA模式
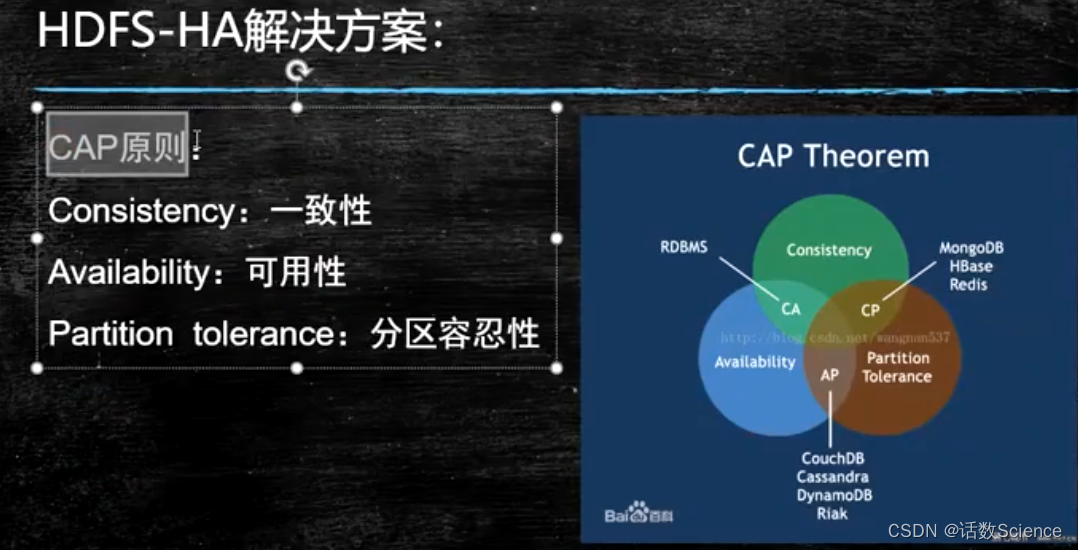
CPA原则
分区容忍性:即脑裂,
Paxos算法
帕克索斯算法:Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
主从+过半
强一致、弱一致都能做,区块链中也是基于该算法
ZooKeeper中使用的是Paxos的简化版本ZAB,ZK做分布式协调
早期用的多,后来大家都把他剔除了,最多用zk选个主,做配置的同步,或者唯一性。因为zk解决是解决的是事件的触发,解决决策之间某一种事件的调用,不适合存东西。?
JournalNodes(Journal杂志、期刊) 跟ZK不是一个东西,JournalNodes做分布式存储
JournalNodes是为了解决节点之间数据同步的。
HA解决方案



FalioverController是用来做健康检查的。
跟NN在同一个节点,它们是不同的进程,FalioverController会监控NN是否活着。
ZK维护一个目录树结构,主备FalioverController会在ZK同时申请在X节点下抢锁,谁抢到谁就是active,否则是standby。
当FalioverController进程监控到了Active的NN挂了,然后FalioverController会把ZK当中抢到的锁删掉。锁删除是一种事件机制,会有callback。
ZK Watch监控:FC抢锁时还在ZK的锁上注册了自己的地址还包括回调函数,当FC删除锁时,产生删除事件,这个删除事件就会触发callback,就会回调FC里的方法,在fc的进程里执行,这是FC发现锁没有了会重新抢锁。
如果是轮询查询锁在不在,会存在轮询间隔,所以会用事件callback机制。
NN还活着,FC挂了,与ZK节点挂了,FC临时节点随着TCP连接的消失,会触发删除事件。
FC会去检查之前Active的NN是不是真死了,没死就把它降级为standby,再把自己升级为active。当网络不通或者什么异常导致无法判断对方是不是真的挂了,此时不会把自己升级为active,这种情况出现的几率很低。(两台主机通过串口相连,这个连接可以当成可靠的)
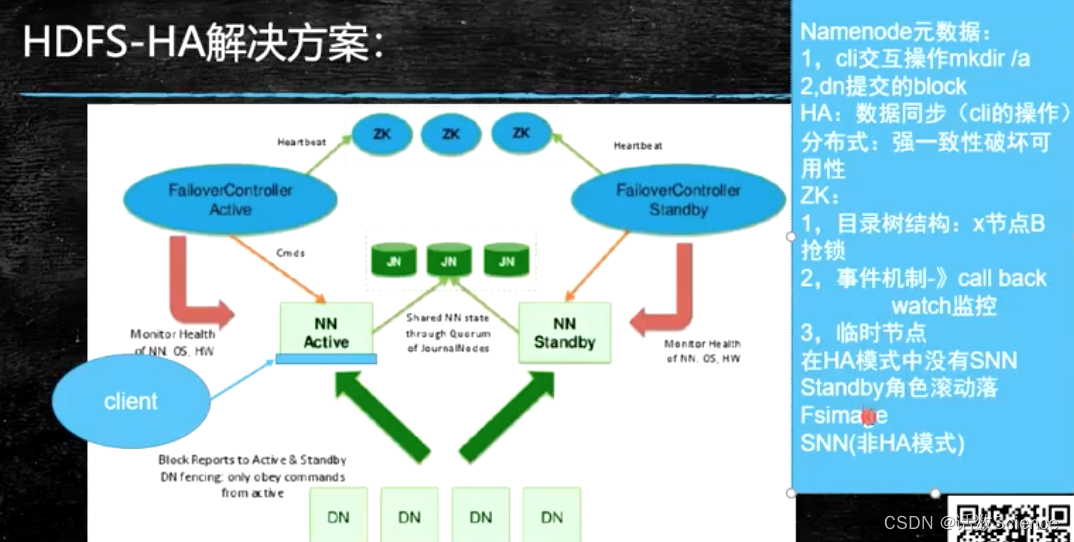

HA模式下,SNN的角色被Standby替代了,不承担服务,滚动生成FsImage,并把生成的FsImage推回去,以便宕机后的快速恢复。
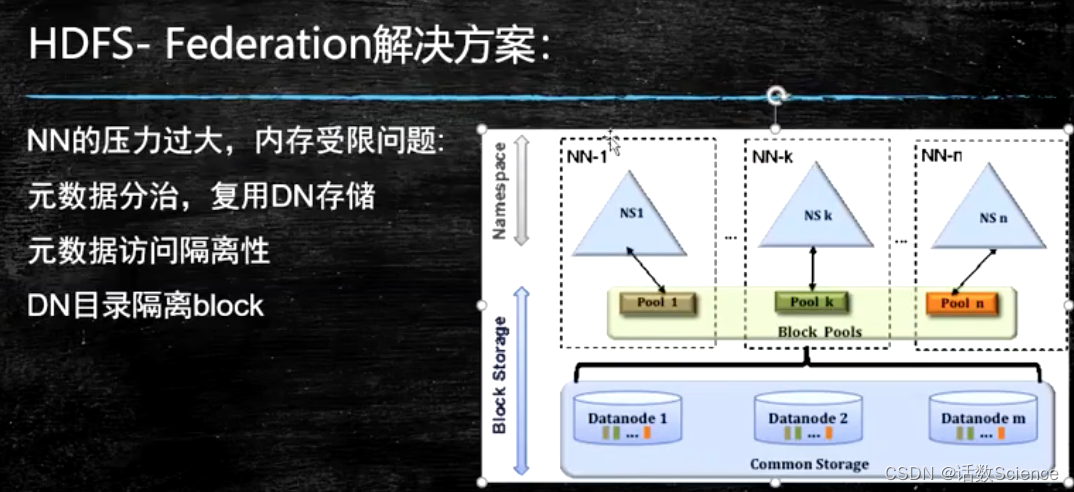
HDFS-Fedration解决方案(联邦机制)
联邦机制:各个联邦,属于同一个国家,统一一套资源
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!