70.Redis缓存优化实践(基于分类树场景)
前言
分类树查询功能,在各个业务系统中可以说随处可见,特别是在电商系统中。

而在实际工作中,这样一个分类树查询,我们都不断的改进了好几次。这是为什么呢?
由于当时这个是从0-1的新项目,为了开快速开发功能,我们第一版接口,直接从数据库中查询分类数据,组装成分类树,然后返回给前端。 通过这种方式,简化了数据流程,快速把整个页面功能调通了。
第一次优化
我们将该接口部署到开发dev环境,刚开始没啥问题。随着开发人员添加的分类越来越多,很快就暴露出性能瓶颈。我们不得不做优化了。
我们第一个想到的是:加Redis缓存。
流程图如下:
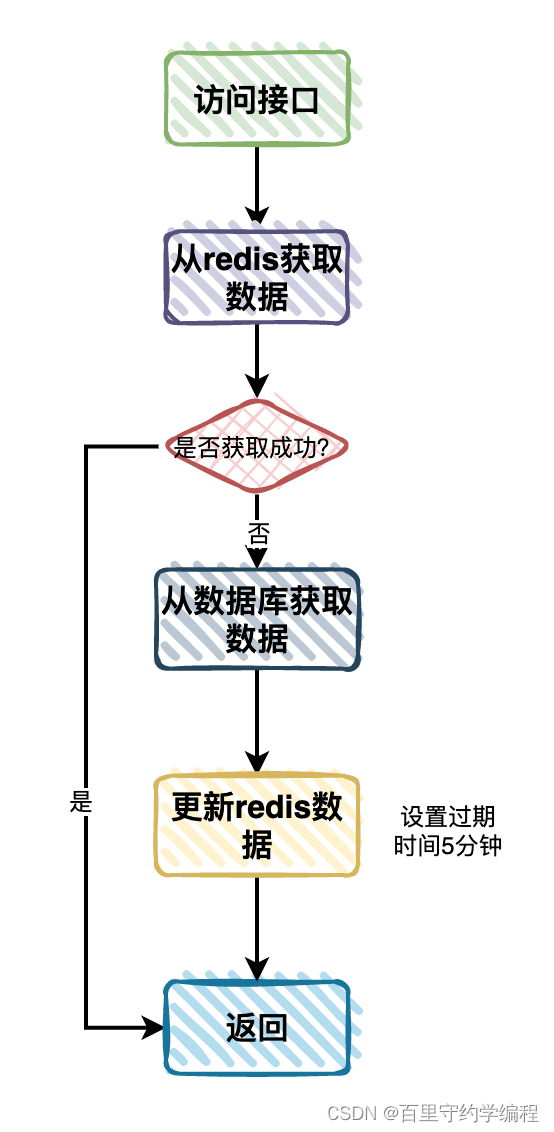
于是暂时这样优化了一下:
- 用户访问接口获取分类树时,先从
Redis中查询数据。 - 如果
Redis中有数据,则直接返回数据。 - 如果
Redis中没有数据,则再从数据库中查询数据,拼接成分类树返回。 - 将从数据库中查到的分类树的数据,保存到
Redis中,设置过期时间5分钟。 - 将分类树返回给用户。
我们在Redis中定义一个了key,value是一个分类树的json格式转换成了字符串,使用简单的key/value形式保存数据。
经过这样优化之后,测试环境的联调和自测顺利完成了。
第二次优化
我们将这个功能部署到预览(pre)环境了。刚开始测试同学没有发现什么问题,但随着后面不断地深入测试,隔一段时间就出现一次首页访问很慢的情况。原因就是开始加载到Redis中的数据过期了,需要从DB获取。
于是,我们马上进行了第2次优化。
我们决定使用Job定期异步更新分类树到Redis中,在系统上线之前,会先生成一份数据,比如在Go语言中,新开一个旁路服务,通过脚本的形式,当服务器实例启动的时候,在Main方法中通过cache.Init()开启一个协程,定期加载数据进Redis缓存,但是需要加分布式锁,不然同一个服务的所有服务器实例都去做这件事有点浪费性能,我们只需要有一个服务实例做这件事就行了,当然,如果是使用的一些定时调度平台的话,一般是调度平台自身就提供了只会让一台服务实例去执行任务的能力的。
当然为了保险起见,防止定时调度平台在哪天突然挂了,之前分类树同步写入Redis的逻辑还是保留。
于是,流程图改成了这样:
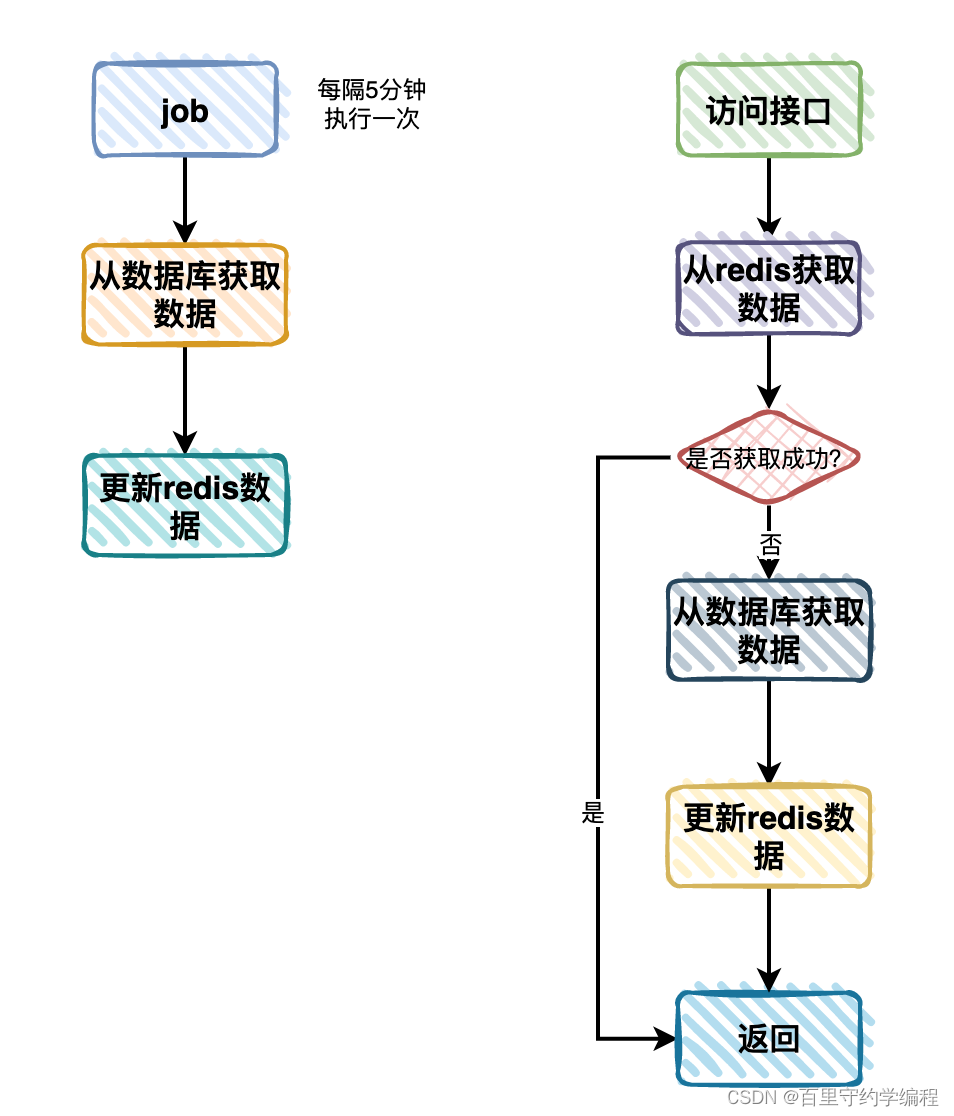
增加了一个旁路定时job每隔5分钟执行一次,从数据库中查询分类数据,封装成分类树,更新到Redis缓存中。其他的流程保持不变。
此外,Redis的过期时间之前设置的5分钟,现在可以设置10分钟,正常情况下,调度平台5分钟内都会更新Redis,但是如果调度平台挂了,导致没有更新,10分钟后,redis的会过期,此时还是可以从DB中拿到最新的数据的,不至于Redis无法得到更新而一直存着旧数据。
通过这次优化之后,预览环境就没有再出现过分类树查询的性能问题了。
第三次优化
测试了一段时间之后,整个网站的功能快要上线了。为了保险起见,我们需要对网站首页做一次压力测试。果然测出问题了,网站首页最大的qps是100多,最后发现是每次都从Redis获取分类树导致的网站首页的性能瓶颈。
我们需要做第3次优化。
该怎么优化呢?
答:加内存缓存。如果加了内存缓存,就需要考虑数据一致性问题。 内存缓存是保存在服务器节点上的,不同的服务器节点更新的频率可能有点差异,这样可能会导致数据的不一致性。但分类本身是更新频率比较低的数据,对于用户来说不太敏感,即使在短时间内,用户看到的分类树有些差异,也不会对用户造成太大的影响。因此,分类树这种业务场景,是可以使用内存缓存的。
在Go中我们可以使用LocalCache或者Map做本地缓存。
改造后的流程图如下:
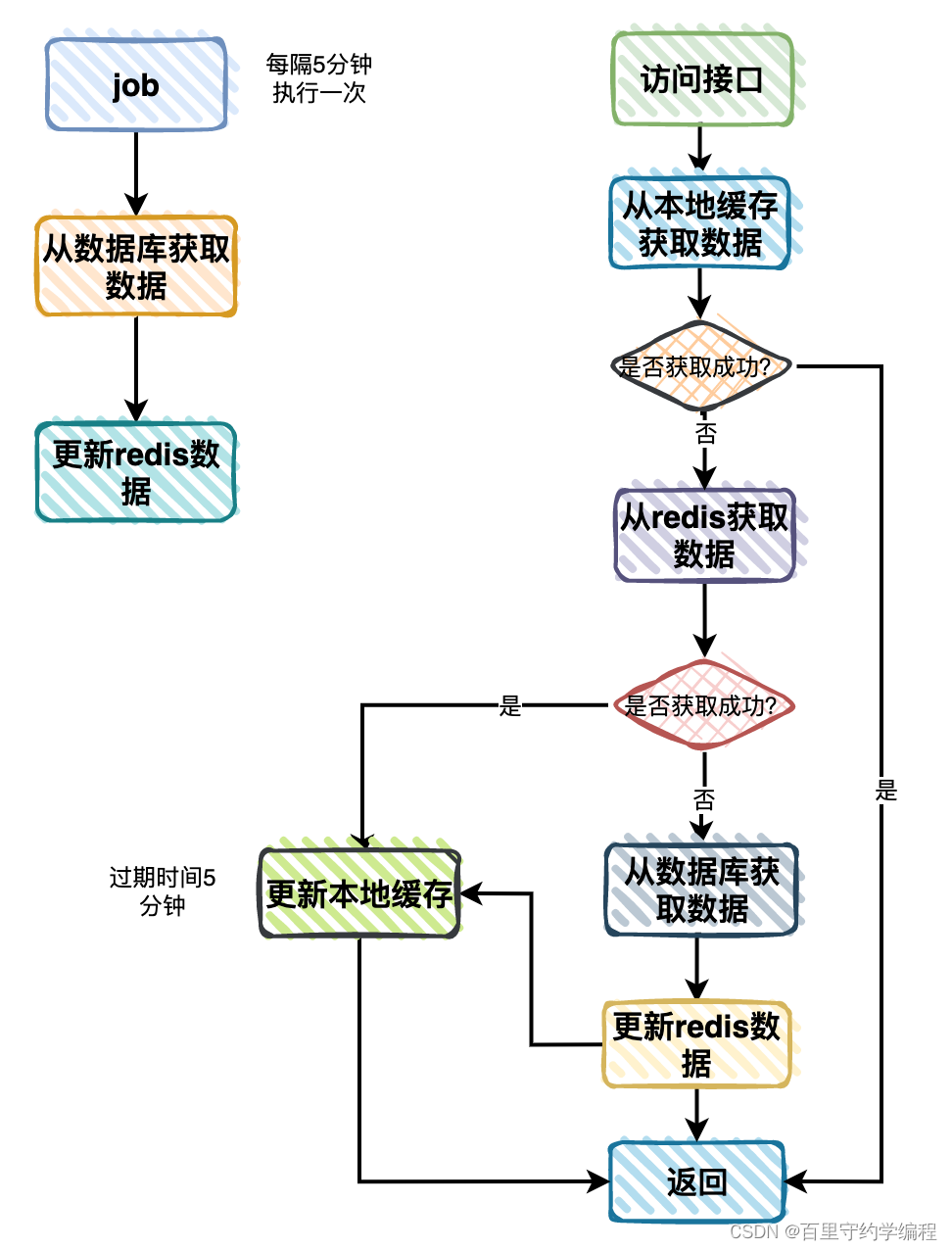
- 用户访问接口时改成先从本地缓存分类数查询数据。
- 如果本地缓存有,则直接返回。
- 如果本地缓存没有,则从
Redis中查询数据。 - 如果
Redis中有数据,则将数据更新到本地缓存中,然后返回数据。 - 如果
Redis中也没有数据(说明Redis挂了或者调度平台挂了),则从数据库中查询数据,更新到Redis中(万一Redis恢复了呢),然后更新到本地缓存中,返回数据。
需要注意的是,需要给本地缓存设置一个过期时间,这里设置的5分钟,不然的话,没办法获取新的数据,比如如果用的map做本地缓存,可以开启一个协程,每隔五分钟重置一下map。
这样优化之后,再次做网站首页的压力测试,qps提升到了500多,满足上线要求。
第四次优化
之后,这个功能顺利上线了。使用了很长一段时间没有出现问题。两年后的某一天,有用户反馈说,网站首页有点慢。我们排查了一下原因发现,分类树的数据太多了,一次性返回了上万个分类。原来在系统上线的这两年多的时间内,运营同学在系统后台增加了很多分类。
我们需要做第4次优化。
这时要如何优化呢?限制分类树的数量?
答:也不太现实,目前这个业务场景就是有这么多分类,不能让用户选择不到他想要的分类吧?
这时我们想到最快的办法是开启nginx的GZip功能。让数据在传输之前,先压缩一下,然后进行传输,在用户浏览器中,自动解压,将真实的分类树数据展示给用户。之前调用接口返回的分类树有1MB的大小,优化之后,接口返回的分类树的大小是100Kb,一下子缩小了10倍。
这样简单的优化之后,性能提升了一些。
Go中Gzip压缩后然后存入Redis可以看本人另一篇博客:69.使用Go标准库compress/gzip压缩数据存入Redis避免BigKey
第五次优化
经过上面优化之后,用户很长一段时间都没有反馈性能问题。但有一天公司同事在排查Redis中大key的时候,揪出了分类树。之前的分类树使用key/value的结构保存数据的。
我们不得不做第5次优化。
为了优化在Redis中存储数据的大小,我们可以对数据进行瘦身后再压缩存入Redis。
1. 只保存需要用到的字段。
例如:
type Category struct {
Id int64 `json:"id"`
Name string `json:"name"`
ParentId int64 `json:"parent_id"` // 父节点
InDate time.Time `json:"in_date"` // 分类添加的日期
InUserId int64 `json:"in_user_id"` // 添加该分类的运营id
InUserName string `json:"in_user_name"` // 添加该分类的运营名字
Children []Category `json:"children"` // 子节点
}
像这个分类对象中inDate、inUserId和inUserName字段是可以不用保存的。
2. 修改字段名称。
例如:
type Category struct {
Id int64 `json:"i"`
Name string `json:"n"`
ParentId int64 `json:"p"` // 父节点
Children []Category `json:"c"` // 子节点
}
由于在一万多条数据中,每条数据的字段名称是固定的,他们的重复率太高了。由此,可以在json序列化时,改成一个简短的名称,以便于返回更少的数据大小。
这还不够,我们还可以对存储的数据做压缩。
先将json字符串数据用GZip工具类压缩成byte数组,然后转为字符串后进行base64编码,最后保存到Redis中。在获取数据时,将解码、解压缩json字符串,然后再f反序列化成分类树。
这样优化之后,保存到Redis中的分类树的数据大小,一下子减少了10倍,Redis的大key问题被解决了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python办公自动化 – 对数据进行正则表达式匹配
- 在校大学生可以考哪些 ?(38个考证时间表)
- django基于Hadoop平台的电影推荐系统(程序+开题报告)
- 【工具使用-ADB】小米手机如何使用adb传输文件
- 基于注解的IOC配置
- 香橙派5 RK3588使用RTL8188FTV USB无线网卡
- OpenGL 基础纹理
- Failed to create CUDAExecutionProvider 使用onnxruntime-gpu未成功调用gpu
- js实现九九乘法表
- Java版企业电子招标采购系统源码——鸿鹄电子招投标系统的技术特点