【大模型实践】ChatGLM3-6B 微调实践,更新模型知识
如果你是 NLP 领域初学者,欢迎关注我的博客,我不仅会分享理论知识,更会通过实例和实用技巧帮助你迅速入门。我的目标是让每个初学者都能轻松理解复杂的 NLP 概念,并在实践中掌握这一领域的核心技能。
通过我的博客,你将了解到:
? NLP 的基础概念,为你打下坚实的学科基础。
? 实际项目中的应用案例,让你更好地理解 NLP 技术在现实生活中的应用。
? 学习和成长的资源,助你在 NLP 领域迅速提升自己。
不论你是刚刚踏入 NLP 的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在 NLP 的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。
一、ChatGLM3 介绍
1、概述
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
a、更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,?ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
b、更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
c、更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
https://github.com/THUDM/ChatGLM3
2、实现原理
以下是 GPT 模型通用的实现原理:
a、Transformer Architecture: GPT 模型采用 Transformer 架构,包括多个编码器和解码器层。每个层都包含多头自注意力机制和前馈神经网络。
b、预训练: 模型首先在大规模的文本语料库上进行预训练。这个阶段模型学到了语言的统计结构、语法、语义等信息,使其能够理解和生成自然语言。
c、参数规模: chatglm3-6B 表示该模型包含约 6 亿(Billion)个参数,这使得它相当庞大,有能力处理多种复杂的语言任务。
d、微调: 在预训练之后,模型可以在特定任务或领域上进行微调,以适应具体的应用场景。微调可能需要一个任务特定的数据集。
e、Tokenization 和 Attention Mechanism: 输入文本通过分词(Tokenization)被转换成模型能够理解的表示,并且通过自注意力机制进行处理,以关注输入序列中不同位置的信息。
f、生成式模型: GPT 是生成式模型,它能够生成类似于训练数据的文本。在对话中,它可以生成连贯自然的回应。
二、开发环境准备
1、硬件要求
最低显存要求: 24GB
推荐显卡: RTX 40902、软件要求
Linux Ubuntu 22.04.5 kernel version 6.7
Python 版本: = 3.10
CUDA 版本: >= 11.7三、部署和微调
1、拉取仓库
git clone https://github.com/THUDM/ChatGLM32、进入目录
cd ChatGLM33、创建虚拟环境
conda create -n chatglm python=3.104、激活使用虚拟环境
conda activate chatglm5、安装全部依赖
pip install -r requirements.txt6、下载模型
a、访问?https://huggingface.co/THUDM/chatglm3-6b?下载(需要特殊网络环境)
b、从 hugging face 下的话需要特殊网络环境,没有条件的可以从魔塔社区下载:
!pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0", cache_dir='path/to/save/dir')其中?cache_dir?参数指定了模型保存的路径。
7、进入?finetune_chatmodel_demo?并安装微调依赖:
cd finetune_chatmodel_demo
pip install requirements.txt使用对话格式进行微调,官方给出的数据格式如下:
[
{
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]8、下载 ToolAlpaca 数据集
作为示例,使用 ToolAlpaca 数据集来进行微调。首先,克隆 ToolAlpaca 数据集
git clone https://github.com/tangqiaoyu/ToolAlpaca9、处理数据集格式
./scripts/format_tool_alpaca.py --path "ToolAlpaca/data/train_data.json"将数据集处理成上述格式。在这里,我们有意将工具处理成了了 list[str] 这样的自然语言形式,以观察模型在微调前后对工具定义的理解能力。
处理完成数据位置:
ChatGLM3/finetune_chatmodel_demo/formatted_data/tool_alpaca.jsonl10、微调模型
官方提供了两种方式,一般使用 P-Tuning v2 微调即可。如果有报错,请查看文文章末的异常集合有无解决方案。
./scripts/finetune_ds_multiturn.sh # 全量微调
./scripts/finetune_pt_multiturn.sh # P-Tuning v2 微调微调过程较长,显卡大概占用 23G 显存:
Every 1.0s: nvidia-smi Wed Jan 24 22:59:35 2024
Wed Jan 24 22:59:35 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... Off | 00000000:98:00.0 Off | 0 |
| N/A 72C P0 256W / 250W | 29786MiB / 32768MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-PCIE... Off | 00000000:CA:00.0 Off | 0 |
| N/A 28C P0 34W / 250W | 19736MiB / 32768MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 13213 C ...a/envs/chatglm/bin/python 23485MiB |顺利的话,窗口会输出如下内容:
+ PRE_SEQ_LEN=128
+ LR=2e-2
+ NUM_GPUS=1
+ MAX_SEQ_LEN=2048
+ DEV_BATCH_SIZE=1
+ GRAD_ACCUMULARION_STEPS=16
+ MAX_STEP=1000
+ SAVE_INTERVAL=500
+ AUTORESUME_FROM_CHECKPOINT=True
++ date +%Y%m%d-%H%M%S
+ DATESTR=20240124-134556
+ RUN_NAME=tool_alpaca_pt
+ BASE_MODEL_PATH=/data/chengligen/ChatGLM3-main/models/chatglm3-6b
+ DATASET_PATH=formatted_data/tool_alpaca.jsonl
+ OUTPUT_DIR=output/tool_alpaca_pt-20240124-134556-128-2e-2
+ mkdir -p output/tool_alpaca_pt-20240124-134556-128-2e-2
+ tee output/tool_alpaca_pt-20240124-134556-128-2e-2/train.log
+ torchrun --standalone --nnodes=1 --nproc_per_node=1 finetune.py --train_format multi-turn --train_file formatted_data/tool_alpaca.jsonl --max_seq_length 2048 --preprocessing_num_workers 1 --model_name_or_path /data/chengligen/ChatGLM3-main/models/chatglm3-6b --output_dir output/tool_alpaca_pt-20240124-134556-128-2e-2 --per_device_train_batch_size 1 --gradient_accumulation_steps 16 --max_steps 1000 --logging_steps 1 --save_steps 500 --learning_rate 2e-2 --pre_seq_len 128 --resume_from_checkpoint True
master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
01/24/2024 13:46:02 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
01/24/2024 13:46:02 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_persistent_workers=False,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=False,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=False,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=no,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=16,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_num_input_tokens_seen=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=0.02,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=output/tool_alpaca_pt-20240124-134556-128-2e-2/runs/Jan24_13-46-02_nlp,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=1.0,
logging_strategy=steps,
lr_scheduler_kwargs={},
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=1000,
metric_for_best_model=None,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=output/tool_alpaca_pt-20240124-134556-128-2e-2,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=8,
per_device_train_batch_size=1,
predict_with_generate=False,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=True,
run_name=output/tool_alpaca_pt-20240124-134556-128-2e-2,
save_on_each_node=False,
save_only_model=False,
save_safetensors=False,
save_steps=500,
save_strategy=steps,
save_total_limit=None,
seed=42,
skip_memory_metrics=True,
sortish_sampler=False,
split_batches=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
[INFO|configuration_utils.py:727] 2024-01-24 13:46:02,515 >> loading configuration file /data/chengligen/ChatGLM3-main/models/chatglm3-6b/config.json
[INFO|configuration_utils.py:727] 2024-01-24 13:46:02,520 >> loading configuration file /data/chengligen/ChatGLM3-main/models/chatglm3-6b/config.json
[INFO|configuration_utils.py:792] 2024-01-24 13:46:02,522 >> Model config ChatGLMConfig {
"_name_or_path": "/data/chengligen/ChatGLM3-main/models/chatglm3-6b",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": 2,
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1e-05,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_layers": 28,
"original_rope": true,
"pad_token_id": 0,
"padded_vocab_size": 65024,
"post_layer_norm": true,
"pre_seq_len": null,
"prefix_projection": false,
"quantization_bit": 0,
"rmsnorm": true,
"seq_length": 8192,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.37.0",
"use_cache": true,
"vocab_size": 65024
}
[INFO|tokenization_utils_base.py:2025] 2024-01-24 13:46:02,527 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2025] 2024-01-24 13:46:02,527 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2025] 2024-01-24 13:46:02,527 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2025] 2024-01-24 13:46:02,527 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2025] 2024-01-24 13:46:02,527 >> loading file tokenizer.json
[INFO|modeling_utils.py:3475] 2024-01-24 13:46:02,787 >> loading weights file /data/chengligen/ChatGLM3-main/models/chatglm3-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:826] 2024-01-24 13:46:02,788 >> Generate config GenerationConfig {
"eos_token_id": 2,
"pad_token_id": 0,
"use_cache": false
}
Loading checkpoint shards: 100%|██████████| 7/7 [00:10<00:00, 1.50s/it]
[INFO|modeling_utils.py:4352] 2024-01-24 13:46:13,332 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.
[INFO|modeling_utils.py:3897] 2024-01-24 13:46:13,335 >> Generation config file not found, using a generation config created from the model config.
Sanity Check >>>>>>>>>>>>>
'[gMASK]': 64790 -> -100
'sop': 64792 -> -100
'<|system|>': 64794 -> -100
'': 30910 -> -100
'\n': 13 -> -100
'Answer': 20115 -> -100
'the': 267 -> -100
......................
'0': 30940 -> 30940
'0': 30940 -> 30940
'.': 30930 -> 30930
'': 2 -> 2
<<<<<<<<<<<<< Sanity Check
[INFO|trainer.py:522] 2024-01-24 13:46:23,002 >> max_steps is given, it will override any value given in num_train_epochs
[INFO|trainer.py:1721] 2024-01-24 13:46:23,749 >> ***** Running training *****
[INFO|trainer.py:1722] 2024-01-24 13:46:23,749 >> Num examples = 4,048
[INFO|trainer.py:1723] 2024-01-24 13:46:23,749 >> Num Epochs = 4
[INFO|trainer.py:1724] 2024-01-24 13:46:23,749 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1727] 2024-01-24 13:46:23,749 >> Total train batch size (w. parallel, distributed & accumulation) = 16
[INFO|trainer.py:1728] 2024-01-24 13:46:23,749 >> Gradient Accumulation steps = 16
[INFO|trainer.py:1729] 2024-01-24 13:46:23,749 >> Total optimization steps = 1,000
[INFO|trainer.py:1730] 2024-01-24 13:46:23,751 >> Number of trainable parameters = 1,835,008
{'loss': 0.9685, 'learning_rate': 0.01998, 'epoch': 0.0}
{'loss': 0.9597, 'learning_rate': 0.019960000000000002, 'epoch': 0.01}
{'loss': 0.9796, 'learning_rate': 0.01994, 'epoch': 0.01}
.......................................................
{'loss': 0.292, 'learning_rate': 0.0165, 'epoch': 0.69}
18%|█▊ | 175/1000 [1:08:58<5:24:24, 23.59s/it]四、部署微调后的模型
MODEL_PATH 为自己的 chatglm3-6b 的路径,PT_PATH 指向微调后输出的路径,PT_PATH 的路径一般如下位置和格式:
"ChatGLM3/finetune_chatmodel_demo/output/tool_alpaca_pt-20231227-061735-128-2e-2"1、对于全量微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="path to finetuned model checkpoint" TOKENIZER_PATH="THUDM/chatglm3-6b" streamlit run main.py2、对于 P-Tuning v2 微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="THUDM/chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py五、异常集合
1、异常一
场景:
运行微调代码时候
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调问题:
出现无限循环网络问题
[W socket.cpp:601] [c10d] The IPv6 network addresses of (nlp, 56126) cannot be retrieved (gai error: -2 - Name or service not known).
[W socket.cpp:601] [c10d] The IPv6 network addresses of (nlp, 56126) cannot be retrieved (gai error: -2 - Name or service not known).
[W socket.cpp:601] [c10d] The IPv6 network addresses of (nlp, 56126) cannot be retrieved (gai error: -2 - Name or service not known).
[W socket.cpp:601] [c10d] The IPv6 network addresses of (nlp, 56126) cannot be retrieved (gai error: -2 - Name or service not known).解决:
大概意思是没能连接上本地的网络,查了很多资料都没有结果,下面这个解决方法对我有用。
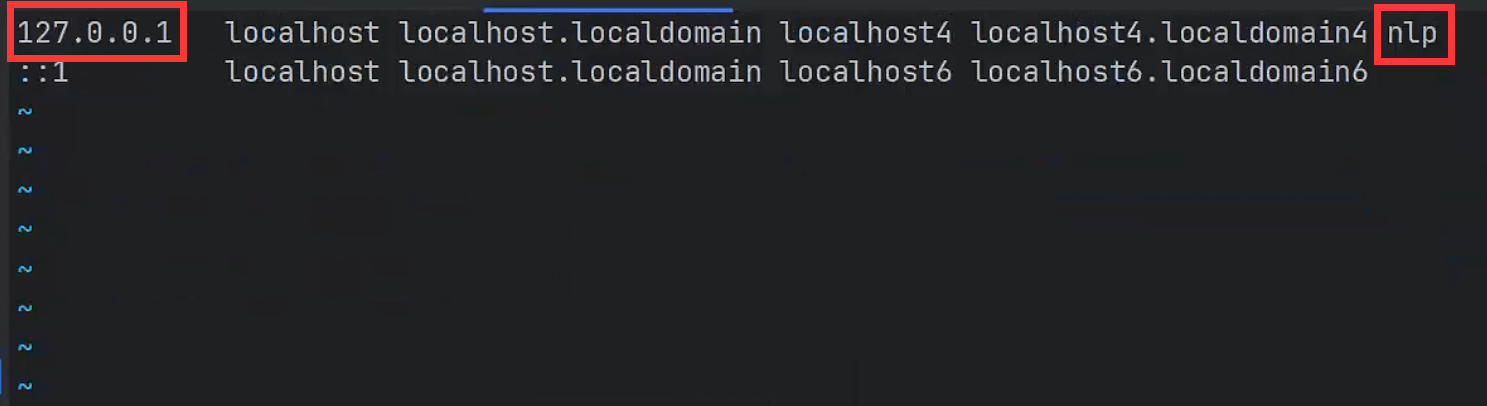
手动添加本地网络
vim /etc/hosts添上本地网络
127.0.0.1 nlpnlp 为机器名字,如果没有 127.0.0.1 这一行,自行添加即可
2、异常二
场景:
运行微调代码时候
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调问题:
端口占用
(chatglm) root@nlp:/data/chengligen/ChatGLM3-main/finetune_chatmodel_demo# ./scripts/finetune_pt_multiturn.sh
+ PRE_SEQ_LEN=128
+ LR=2e-2
+ NUM_GPUS=1
+ MAX_SEQ_LEN=2048
+ DEV_BATCH_SIZE=1
+ GRAD_ACCUMULARION_STEPS=16
+ MAX_STEP=1000
+ SAVE_INTERVAL=500
+ AUTORESUME_FROM_CHECKPOINT=True
++ date +%Y%m%d-%H%M%S
+ DATESTR=20240124-134257
+ RUN_NAME=tool_alpaca_pt
+ BASE_MODEL_PATH=/data/chengligen/ChatGLM3-main/models/chatglm3-6b
+ DATASET_PATH=formatted_data/tool_alpaca.jsonl
+ OUTPUT_DIR=output/tool_alpaca_pt-20240124-134257-128-2e-2
+ mkdir -p output/tool_alpaca_pt-20240124-134257-128-2e-2
+ torchrun --standalone --nnodes=1 --nproc_per_node=1 finetune.py --train_format multi-turn --train_file formatted_data/tool_alpaca.jsonl --max_seq_length 2048 --preprocessing_num_workers 1 --model_name_or_path /data/chengligen/ChatGLM3-main/models/chatglm3-6b --output_dir output/tool_alpaca_pt-20240124-134257-128-2e-2 --per_device_train_batch_size 1 --gradient_accumulation_steps 16 --max_steps 1000 --logging_steps 1 --save_steps 500 --learning_rate 2e-2 --pre_seq_len 128 --resume_from_checkpoint True
+ tee output/tool_alpaca_pt-20240124-134257-128-2e-2/train.log
master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
[W socket.cpp:426] [c10d] The server socket has failed to bind to [::]:29400 (errno: 98 - Address already in use).
[W socket.cpp:426] [c10d] The server socket has failed to bind to 0.0.0.0:29400 (errno: 98 - Address already in use).
[E socket.cpp:462] [c10d] The server socket has failed to listen on any local network address.解决:
找出端口占用程序的 pid,杀掉即可,我的显示端口号 29400 被占用
找到占用程序的 pid
lsof -i :29400(chatglm) root@nlp:/data/chengligen/ChatGLM3-main/finetune_chatmodel_demo# lsof -i :29400
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
torchrun 2653 root 3u IPv6 98686958 0t0 TCP *:29400 (LISTEN)
torchrun 2653 root 6u IPv6 98686964 0t0 TCP localhost:44330->localhost:29400 (ESTABLISHED)
torchrun 2653 root 7u IPv6 98686967 0t0 TCP localhost:44332->localhost:29400 (ESTABLISHED)
torchrun 2653 root 8u IPv6 98697430 0t0 TCP localhost:29400->localhost:44330 (ESTABLISHED)
torchrun 2653 root 11u IPv6 98697431 0t0 TCP localhost:29400->localhost:44332 (ESTABLISHED)
torchrun 2855 root 3u IPv6 100832571 0t0 TCP localhost:57180->localhost:29400 (ESTABLISHED)
torchrun 2855 root 4u IPv6 100832574 0t0 TCP localhost:57182->localhost:29400 (ESTABLISHED)杀掉 pid 为 2653 的程序
kill -9 2653在这个充满科技魔力的时代,自然语言处理(NLP)正如一颗璀璨的明星般照亮我们的数字世界。当我们涉足 NLP 的浩瀚宇宙,仿佛开启了一场语言的奇幻冒险。正如亚历克斯 · 康普顿所言:“语言是我们思想的工具,而 NLP 则是赋予语言新生命的魔法。”这篇博客将引领你走进 NLP 前沿,发现语言与技术的交汇点,探寻其中的无尽可能。不论你是刚刚踏入 NLP 的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在 NLP 的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 打铁需要自身硬,我敢和欧系谬论硬刚源自实力与信心
- C语言整型常量的存储形式是怎样的?
- C++(10)——模板
- 防止接口返回数据慢,点击其他按钮请求数据之后被返回慢的数据覆盖掉新数据
- Linux 入门命令大全汇总 + Linux 集锦大全 【20240115】
- Databend 开源社区上榜 2023 年度 OSCHINA 优秀开源技术团队
- 新手必了解c语言之内存函数
- 如何使用Docker一键部署WBO白板并实现固定公网地址远程访问
- 线上剧本杀小程序搭建,未来线上剧本杀有哪些发展优势?
- php写一个雪花算法