【论文+在线运行】AnyText:能准确写汉字的AI绘图工具
源码:https://github.com/tyxsspa/AnyText
阿里在线运行: https://modelscope.cn/studios/damo/studio_anytext/summary
论文:2311.AnyText: Multilingual Visual Text Generation And Editing
一、AnyTexT是什么?
是一个基于扩散模型的(diffusion-based)
多语言(multilingual)视觉文字(visual text)生成和编辑的模型,
专注于在图像中渲染准确和连贯(accurate and coherent)的文本。
能做什么?
功能:生成图片同时,在指定位置生成中文、英文、日文等,还可对已有图片进行编辑
不足:未来的工作将集中在探索极小字体(extremely small fonts)的生成和研究具有可控属性(controllable attributes.)的文本生成
图1 生成图片示例:
对于文本生成,AnyText可以将指定的文本从提示渲染到指定的位置,并生成视觉吸引力的图像
对于文本编辑,AnyText可以在输入图像中的指定位置(specified position)修改文本内容,同时保持与周围文本样式的一致性(maintaining consistency with)。
下图括号中为提示中的非英语单词提供翻译,蓝色框表示文本编辑位置(可输入修改位置)

图3 生成指定位置、不规则弯曲的文字
- 美人鱼的
标志(a logo of a mermaid),上面写着( with the words)“星巴克(STARBUCKS)”和“咖啡(COFFEE)” - 写着“2023”和“冠军”的
横幅(a banner that reads) - 一个精致礼盒的
照片(photo of ),上面写着“新婚快乐”,(数码单反照片) - 街上写着“禁止超速(禁止超速行驶)
指示牌(`sign on that xx says)

图4 多语言图片生成
大楼上的牌子上写着 “我理解英语” (Sign on the building that reads)

图5,比较效果: SD-XL1.0 、Bing Image Creator3、DALL-E2, 以及 DeepFloyd IF
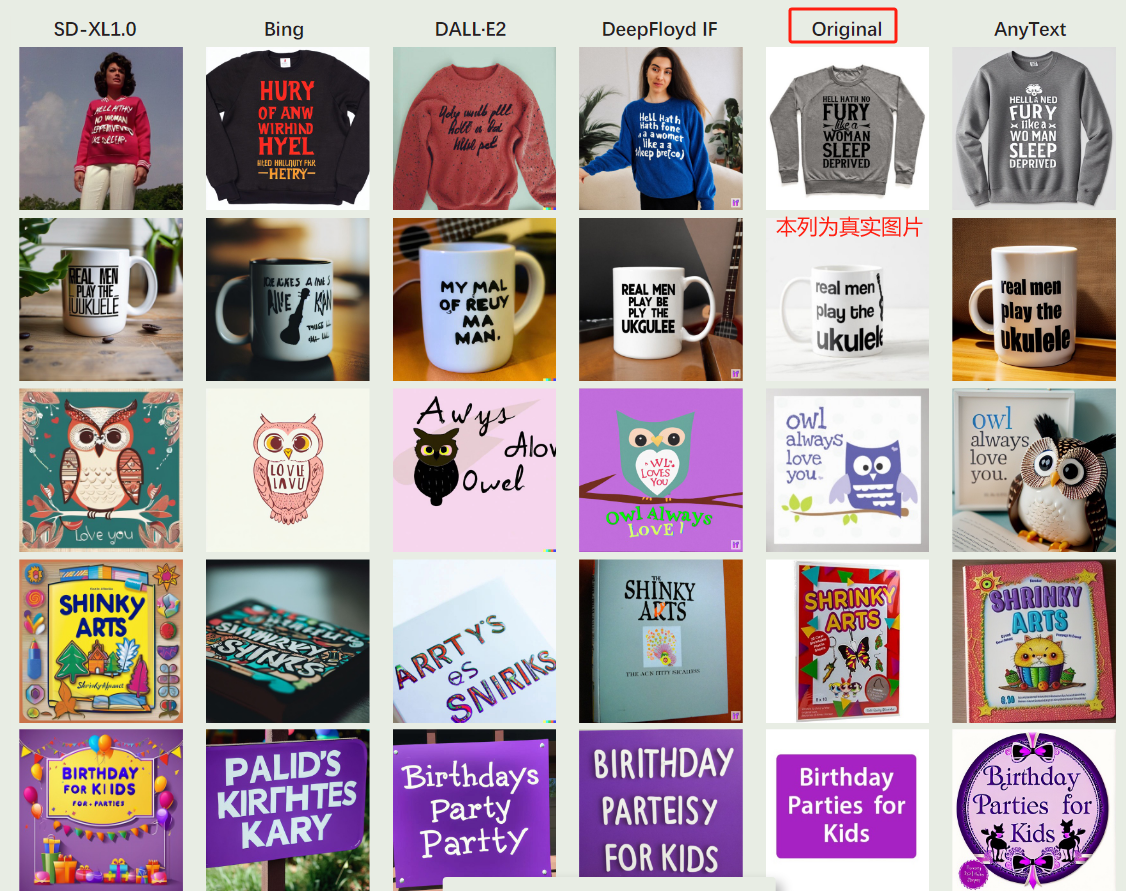
图6 中文生成效果比较
中文文本生成中GlyphDraw、ControlNet和AnyText的比较示例,全部摘自GlyphDraw的原始论文
GlyphDraw: Learning to Draw Chinese Characters in Image Synthesis Models Coherently

二、实际使用测试
https://modelscope.cn/studios/damo/studio_anytext/summary
图像生成
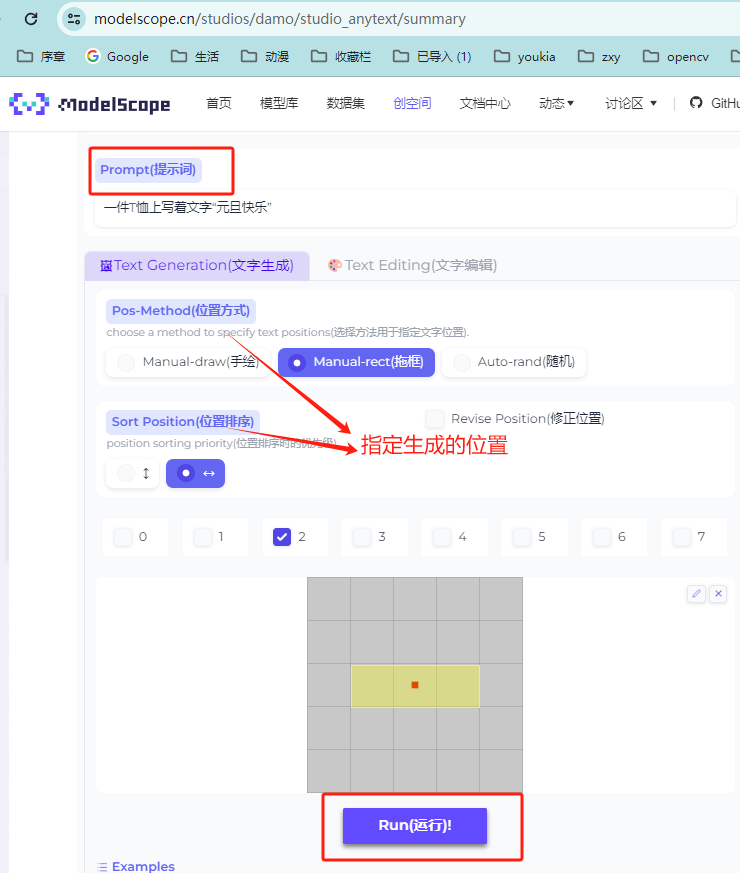
一只熊猫在黑板前,上面写着 “今天不上课”

一件T恤上写着文字“元旦快乐"

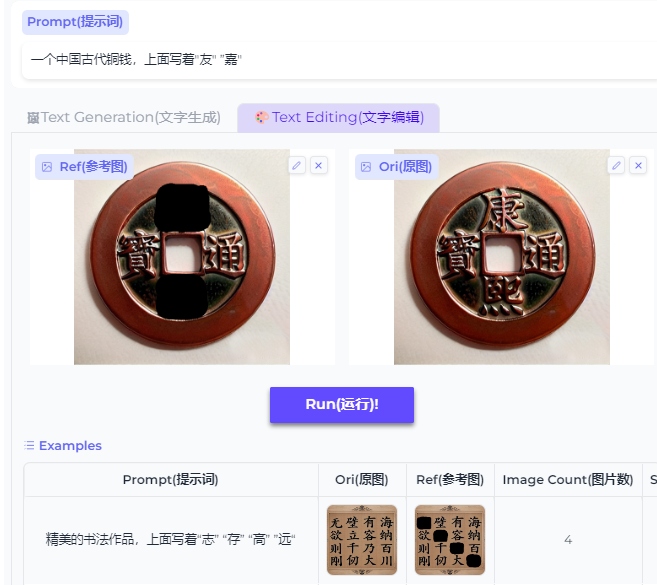
图像编辑:一个中国古代铜钱
https://modelscope.cn/studios/damo/studio_anytext/summary
原始输入
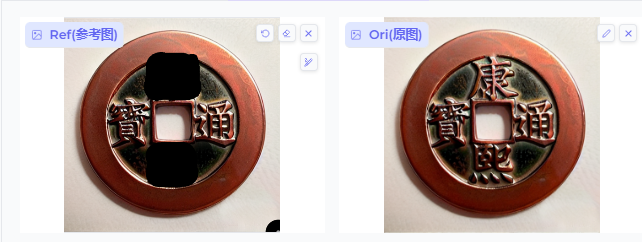
生成结果
一个中国古代铜钱,上面写着"友" “嘉”

原理是什么?
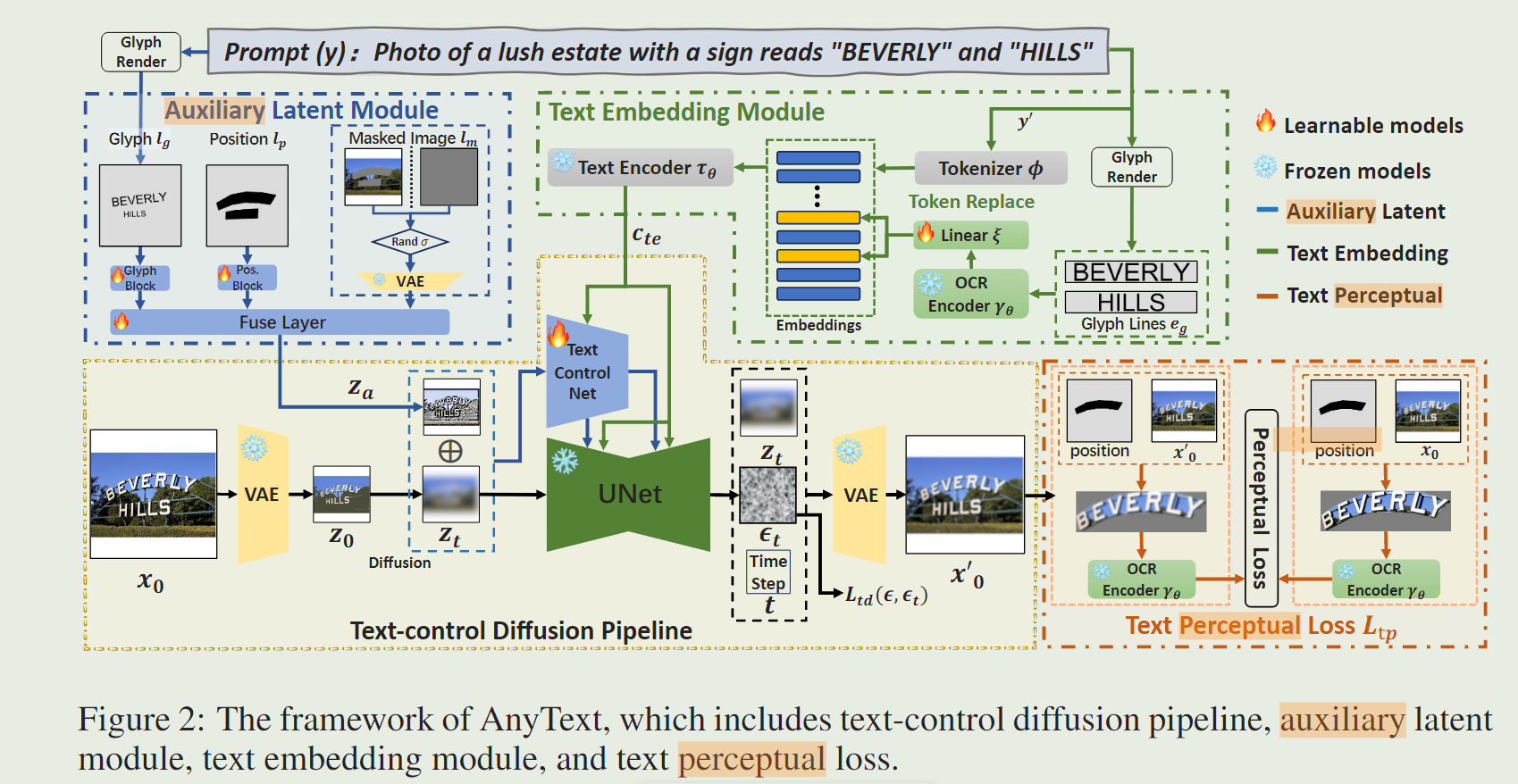
AnyText包括一个具有两个主要元素的扩散管道:一个辅助潜在模块和一个文本嵌入模块
前者使用文本字形、位置和遮罩图像等输入来生成用于文本生成或编辑的潜在特征。
后者采用OCR模型将笔划数据(stroke data)编码为嵌入,该嵌入与来自分词器(tokenizer)的图像的说明文字(caption)嵌入相融合,生成与背景无缝集成(seamlessly integrate)的文本。
采用文本控制扩散损失(text-control diffusion loss)和文本感知损失(text perceptual)进行训练,进一步提高文字生成精度
创新点
提供了第一个大规模多语言文本图像数据集 AnyWord-3M,包含 300 万个图像-文本对,具有多种语言的 OCR 注释(annotations)
基于 AnyWord-3M 数据集,我们提出了 AnyText-benchmark 视觉文本生成的准确性和质量评估(evaluation)平台
可以作为插件插入社区已有的模型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【通关喜报】腾讯云TDSQL TCP/TCE、云运维tcp 12月认证考试,全员过关,年终冲刺!
- 陶哲轩工作流之人工智能数学验证+定理发明工具LEAN4 [线性代数篇2前置知识]笛卡尔积等价于映射n → n全体
- java.lang.IllegalArgumentException: Request header is too largeiseases
- 常见的排序算法解析实现
- JavaOOP篇----第十篇
- 为什么线程的sleep时间不准确?
- AI绘画-通义万相
- 张雪峰推荐2023未来专业哪个就业前景好
- 推荐新版AI智能聊天系统网站源码ChatGPT NineAi
- 目标仿真工具软件