拓扑排序图解-Kahn算法和深度优先搜索
拓扑排序 是将一个有向无环图中的每个节点按照依赖关系进行排序。比如图 G G G存在边 < u , v > <u,v> <u,v> 代表 v v v的依赖 u u u, 那么在拓扑排序中,节点 u u u一定在 v v v的前面。
从另一个角度看,拓扑排序是一种图遍历,具有两个性质:
- 图 G G G中的每个节点 v v v在排序序列中仅出现一次。
- 节点 v v v当且仅当其依赖的所有节点 u u u被访问完成,才被访问。
拓扑排序能够在 O ( V + E ) O(V+E) O(V+E)的线性时间内完成,分为两种算法-Kahn算法和深度优先搜索
拓扑排序实例

这个图有很多有效的拓扑排序,包括:
视觉从左到右,从上到下:
5, 7, 3, 11, 8, 2, 9, 10
最小编号的可用顶点优先:
3, 5, 7, 8, 11, 2, 9, 10
按入边邻居的字典顺序:
3, 5, 7, 8, 11, 2, 10, 9
最少边数优先:
5, 7, 3, 8, 11, 2, 10, 9
最大编号的可用顶点优先:
7, 5, 11, 3, 10, 8, 9, 2
尝试从上到下,从左到右:
5, 7, 11, 2, 3, 8, 9, 10
任意顺序:
3, 7, 8, 5, 11, 10, 2, 9
Kahn算法
L ← Empty list that will contain the sorted elements
S ← Set of all nodes with no incoming edge
while S is not empty do
remove a node n from S
add n to L
for each node m with an edge e from n to m do
remove edge e from the graph
if m has no other incoming edges then
insert m into S
if graph has edges then
return error (graph has at least one cycle)
else
return L (a topologically sorted order)
这个算法的思想是:
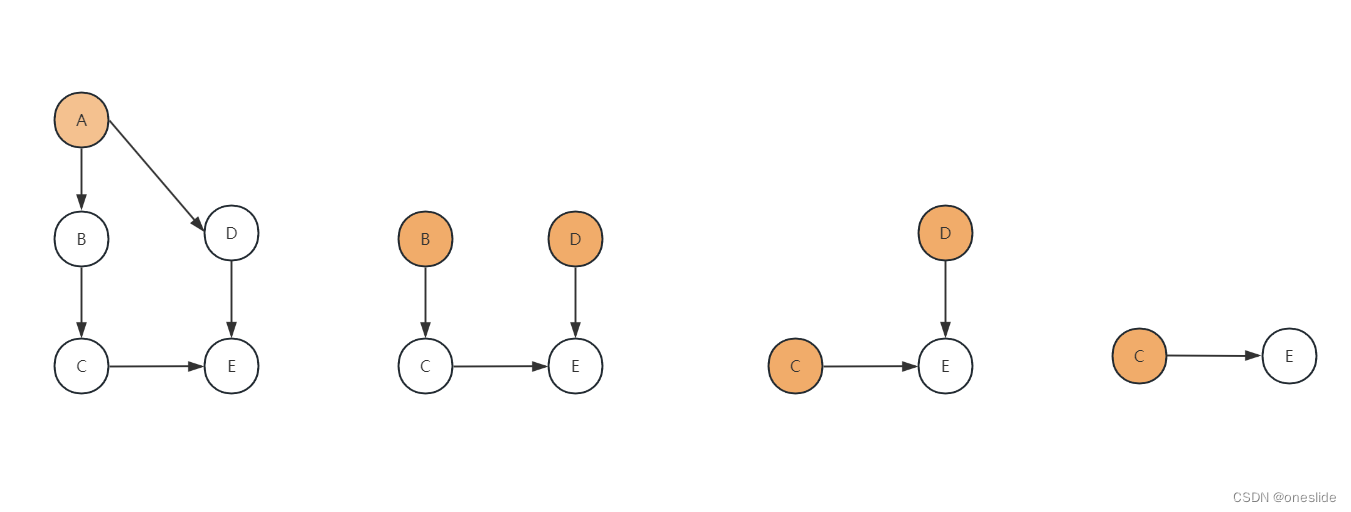
- 首先,在非空的有向无环图中,找到一组没有入边的起始节点,并将它们插入一个集合 S。上节图中的
3,5,7都是起始节点。 - 从S取出一个节点 n n n,追加到列表L
- 对于每个依赖节点 n n n的节点 m m m, 删除边 < n , m > <n,m> <n,m>
- 如果节点 m m m变成起始节点,即入度为0, 那么加入集合S.
- 最后如果图中还有未删除的边,那说明图存在环路,无法拓扑排序;否则输出拓扑排序序列
算法依据的原理是什么?
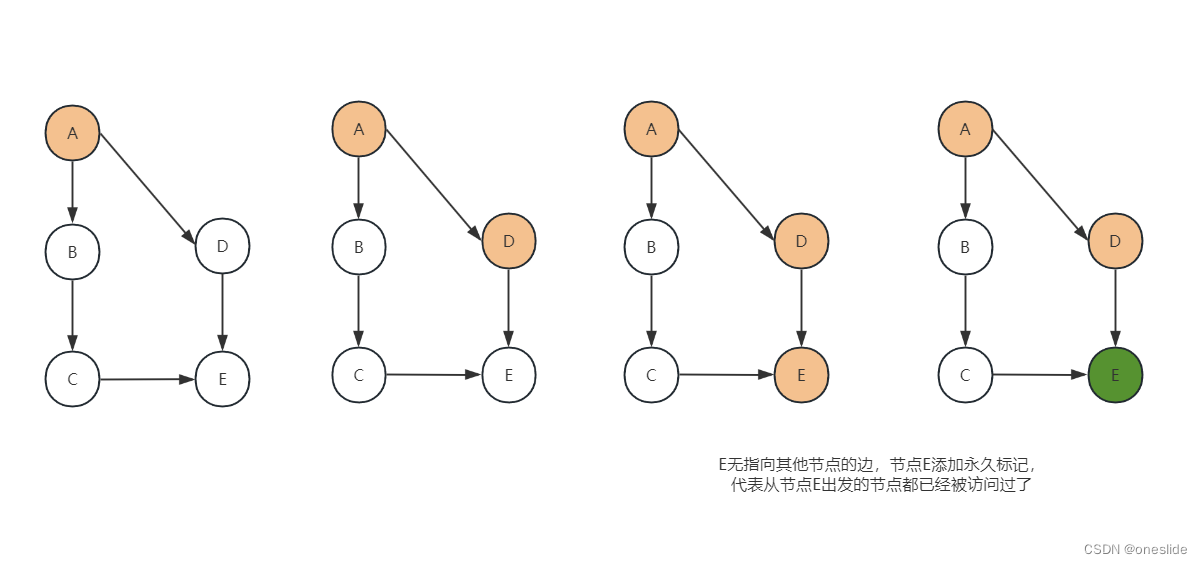
无环图的正常遍历情况是这样的:
黄色代表集合S中的节点
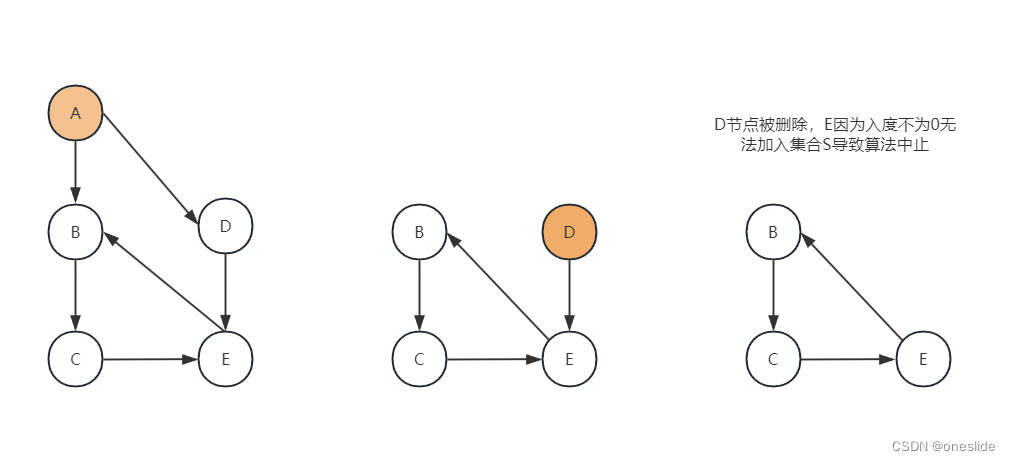
有环图的情况:
如果图G中有环,遍历至环路中任一节点,因为无法在环路中,找到任何一个开始节点进入环路,导致S为空,算法中止。
深度优先搜索
L ← Empty list that will contain the sorted nodes
while exists nodes without a permanent mark do
select an unmarked node n
visit(n)
function visit(node n)
if n has a permanent mark then
return
if n has a temporary mark then
stop (graph has at least one cycle)
mark n with a temporary mark
for each node m with an edge from n to m do
visit(m)
remove temporary mark from n
mark n with a permanent mark
add n to head of L
Kahn算法会破坏原来图的数据,而深度优先不会。深度优先算法采取的是标记方式探测环路。
注意到节点 n n n, 是添加到列表头部,因为是深度优先搜索,节点 n n n带永久标记代表从 n n n出发的能访问到的节点都被访问了,
即所有依赖节点 n n n的节点都已在列表里了。
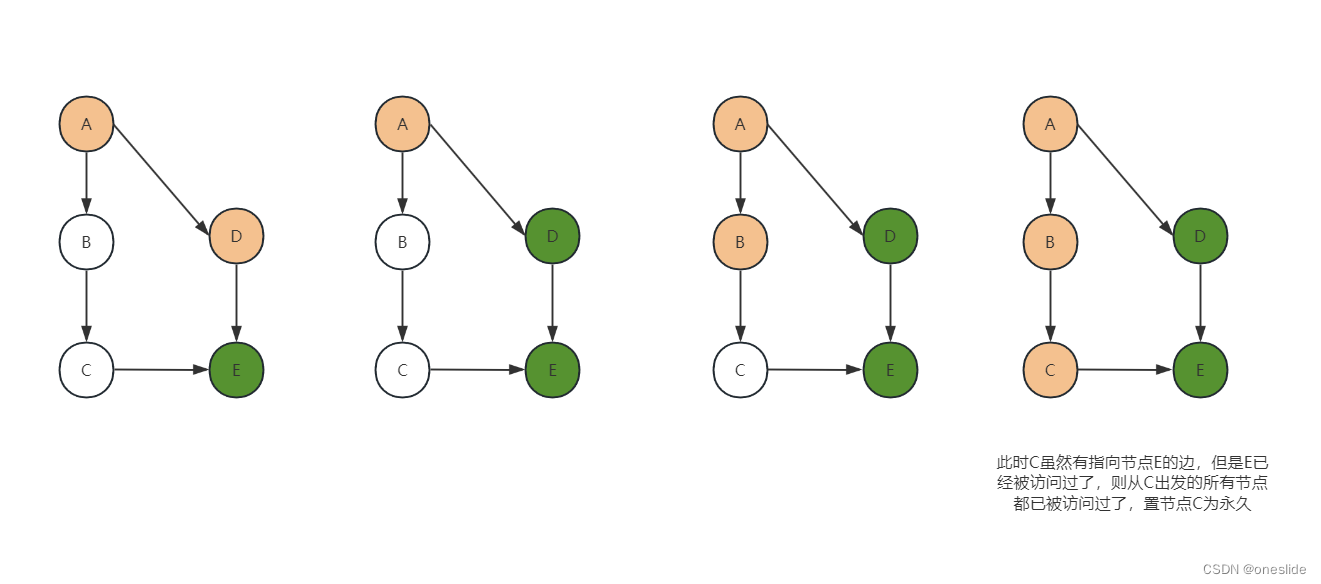
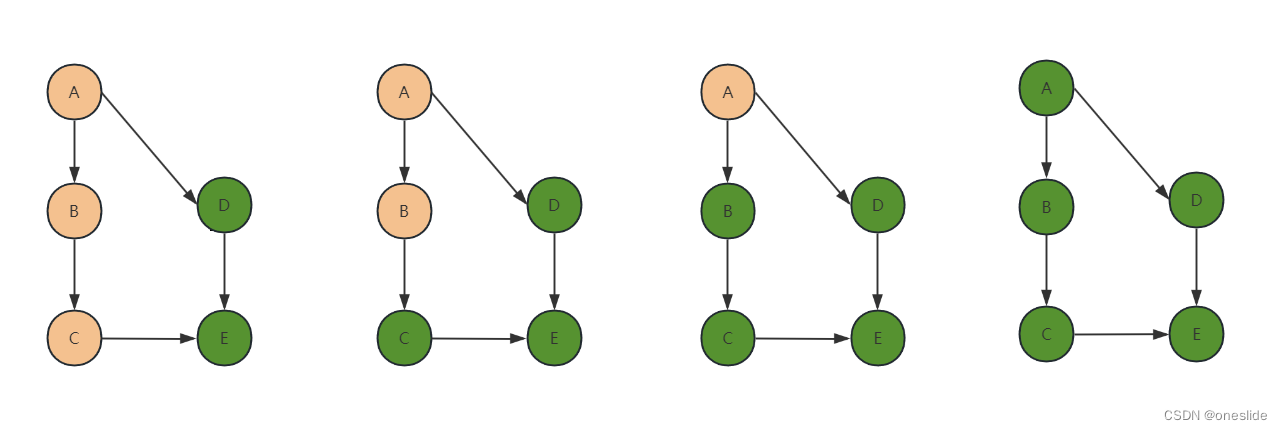
无环路情况
- 绿色为永久标记,代表从此节点出发的能访问到的节点都被访问了
- 橙色为临时标记
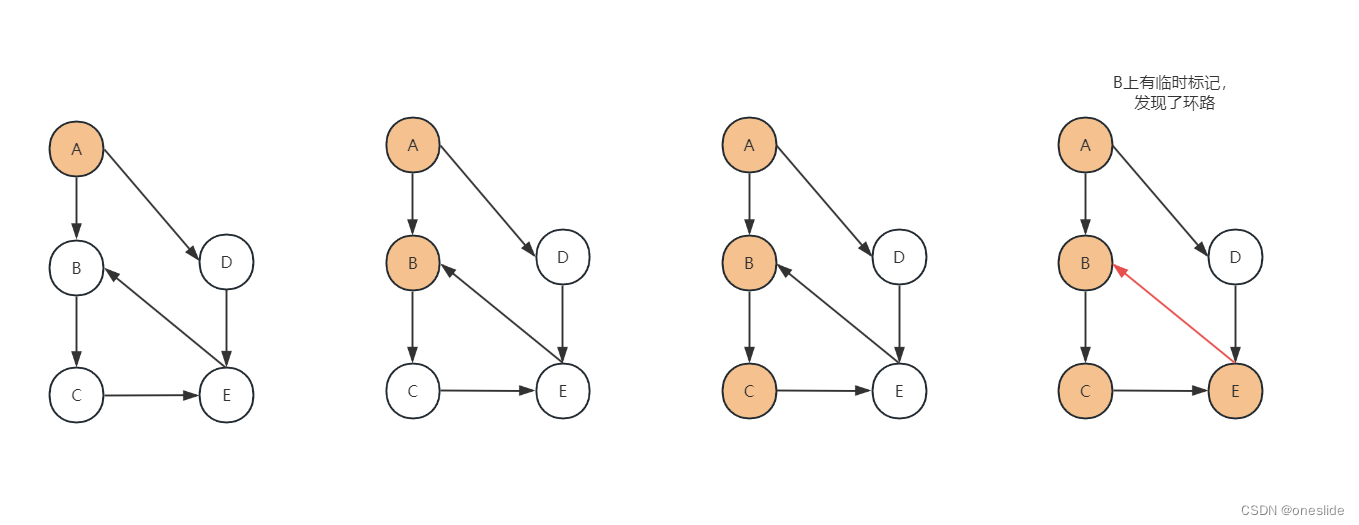
环路情况:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端技术的新趋势:React、Vue与Angular的比较
- 高性能蓝牙芯片HS6621C主从一体支持语音采样苹果MFI认证应用寻物标签语音遥控
- C++学习笔记--结构体
- 红队专题-反序列化攻击-Tools-Ysoserial
- 合泰HT32F65C40F 串口驱动 例:UART0 数据收发
- 阿里云2024年活动优惠券领取和使用以及云服务器价格表
- 我的创作纪念日
- DL Homework 13
- Java可视化物联网智慧工地综合云平台源码 私有化部署
- TS中的函数