基于XLA_GPU的llama7b推理
发布时间:2023年12月25日
环境
- @pytorch-tpu/llama
- pytorch 2.1.2(+cuda117)
- torch-xla 2.1.1
# llama2
git clone --branch llama2-google-next-inference https://github.com/pytorch-tpu/llama.git
# pytorch
git clone https://github.com/pytorch/pytorch.git
git checkout v2.1.2
# 部分仓库可能下载超时(可设置http代理后重试)
git submodule update --init --recursive
# torch-xla 注意,需clone到pytorch根目录
git clone https://github.com/pytorch/xla.git
git checkout v2.1.1
docker和conda两种方式均测试OK。
docker
# Image: pytorch/pytorch:2.1.0-cuda12.1-cudnn8-devel-lasted
# Python: Python 3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0] on linux
# gcc: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
# 编译CUDA版本pytorch
USE_CUDA=1 python setup.py develop
# 编译torch-xla:需要将torch-xla置于pytorch目录下;
# 默认编译时CUDA可能出错,则需要设置CUDA能力(setup.py)
TF_CUDA_COMPUTE_CAPABILITIES=compute_80 XLA_CUDA=1 python setup.py develop
conda
conda activate pt-tpu-llama python=3.10
conda activate pt-tpu-llama
# 解决两个报错
conda install cmake
conda install pyyaml
# 启用CUDA和gcc9.3
source ~/setup_cuda_paths-11.7.1
source /opt/rh/devtoolset-9/enable
# 设置编译器(可能遇到找不到c++和cc)
# Could not find compiler set in environment variable CC:
# 解决编译kineto(profiling tool,影响cupti使用)报错,不编译之(重新编译需要make clean)
CC=gcc CXX=g++ USE_CUDA=1 USE_KINETO=0 python setup.py develop
# python packages
conda install requests, numpy
# 编译torch-xla
XLA_CUDA=1 python setup.py develop
推理
# 在llama根目录下,编辑requirements.txt,注释掉torch(采用编译安装的方式)
pip install -r requirements.txt # fairscale, fire, sentencepiece
# 根目录下创建params.json(7B)
{
"dim": 4096,
"multiple_of": 256,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-05,
"vocab_size": -1
}
# 8卡A800(80GB)
# docker下,可能找不到某些库:export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/conda/lib
PJRT_DEVICE=GPU GPU_NUM_DEVICES=8 python3 example_text_completion.py 1 --ckpt_dir . \
--tokenizer_path ./t5_tokenizer/spiece.model --max_seq_len 2048 --max_gen_len 1000 \
--max_batch_size 1 --dynamo True --mp True
结果:
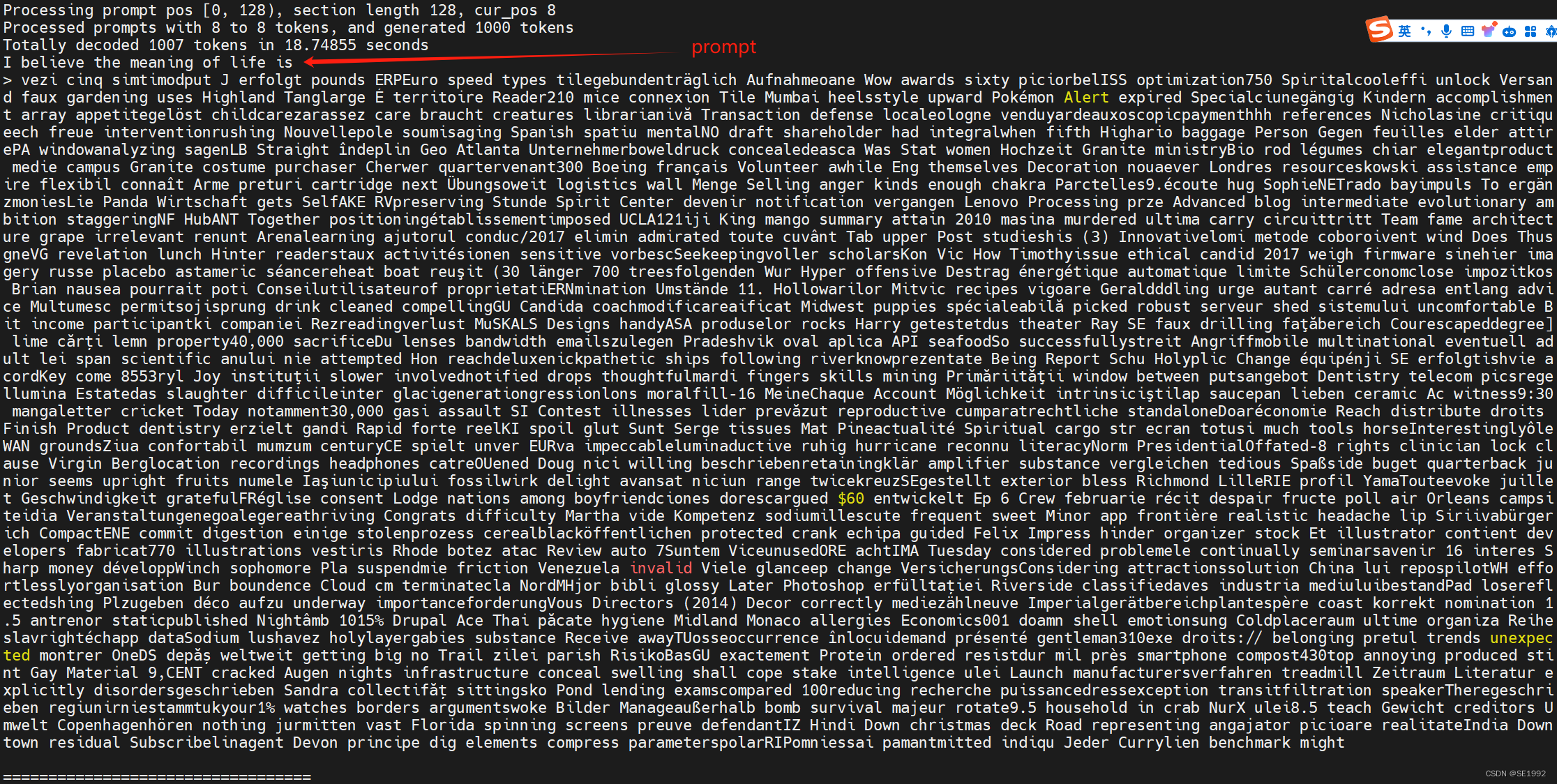
参考链接
commands-to-run-llama2-using-xlagpu-eg-l4-or-h100
torch-xla gpu
文章来源:https://blog.csdn.net/liuzonrze/article/details/135206878
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章