实战1-python爬取安全客新闻
发布时间:2023年12月17日
一般步骤:确定网站--搭建关系--发送请求--接受响应--筛选数据--保存本地
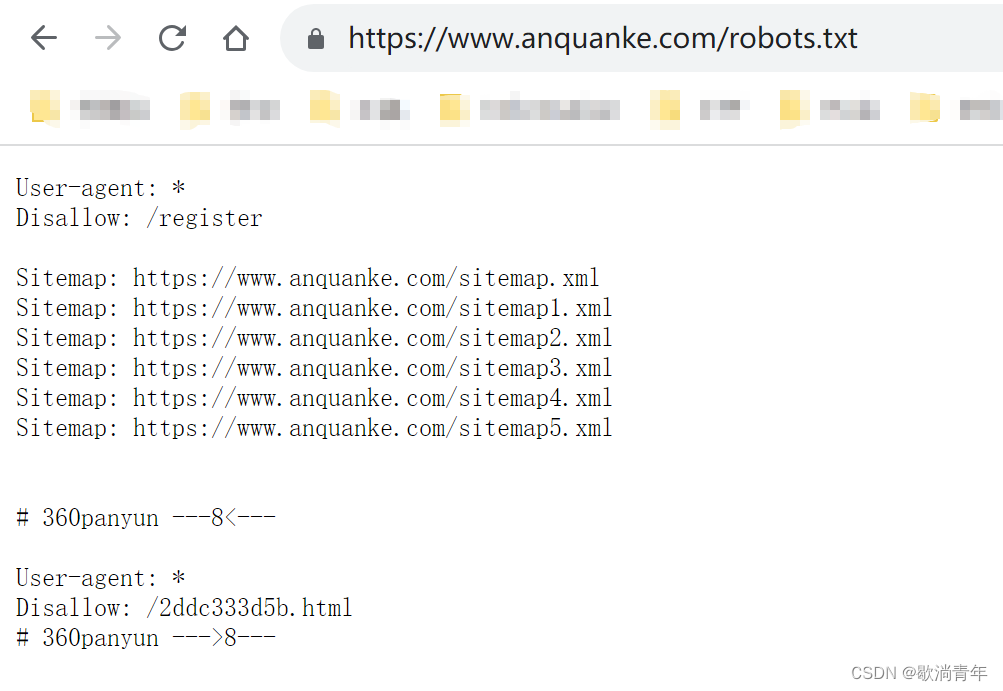
1.拿到网站首先要查看我们要爬取的目录是否被允许
一般网站都会议/robots.txt目录,告诉你哪些地址可爬,哪些不可爬,以安全客为例子
2. 首先测试在不登录的情况下是否请求成功
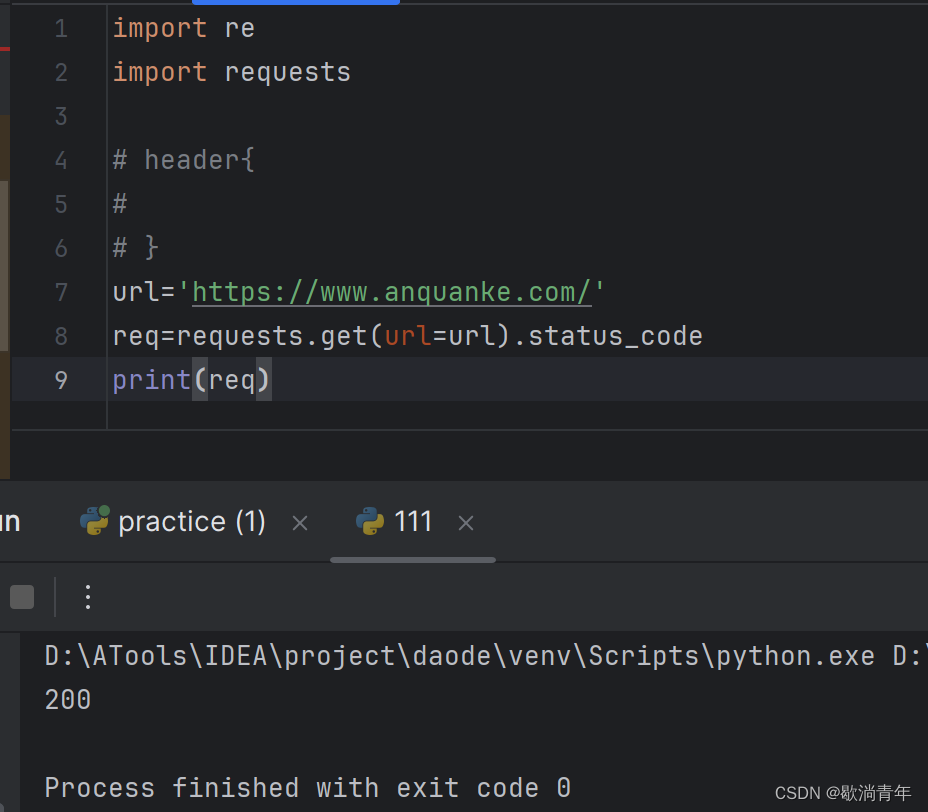
?可见,该请求成功;有很多网站在没有登录的情况下是请求失败的,这时需要添加请求头信息,
注意:有的cookie 会根据时间戳生成,有的会失效
haders={},
2.1、首先 F12 到 Network 下,F5刷新?,复制 Requests Headers然后把它转换成 json 格式
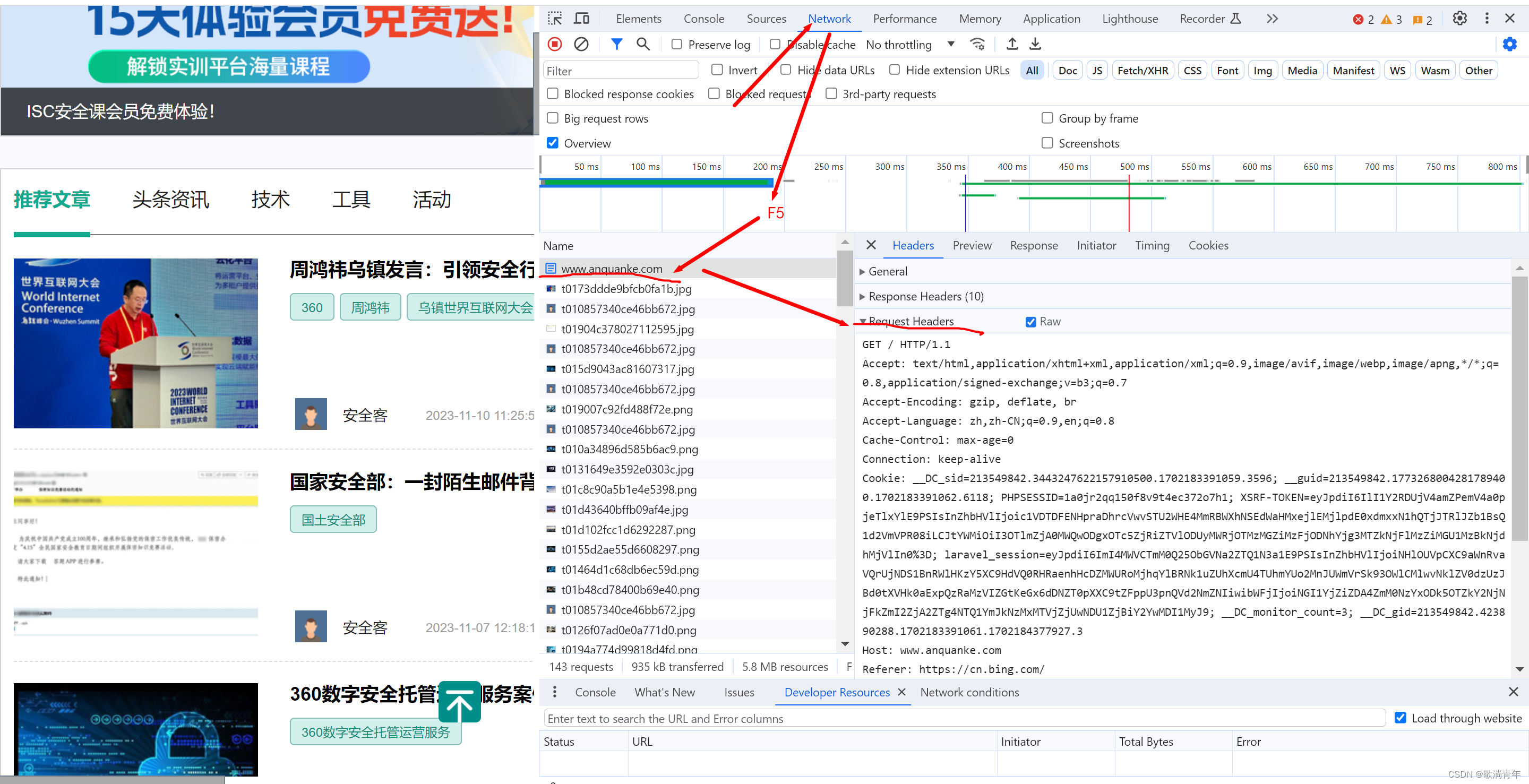
?2.1.1 Requests Headers 转 json 格式有很多种方法
1. 在线转 json 格式的网站:在线HTTP请求/响应头转JSON工具 - UU在线工具
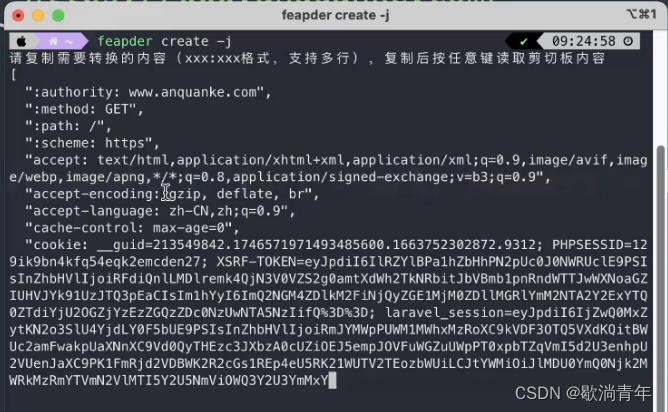
2.如果电脑没网 在终端下载:pip install feapder
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?feapder create -j?
req=requests.get(url=url).text? 是把所有的文本都提取出来,会很乱,所有我们需要筛选,整理一下
可以发现,我们需要的数据在 a 标签中
<a target="_blank" href="/post/id/291754">苹果委托进行数据泄露研究,以强调端到端加密的必要性</a>
数据多了id位数也可能会增加;也可以把id写死,根据291754是个六位数,所以 \d{6}只匹配 id是六位数的。
Title=re.findall(r'<a target="_blank" href="/post/id/\d+">(.*?)</a>',req)
?\d+
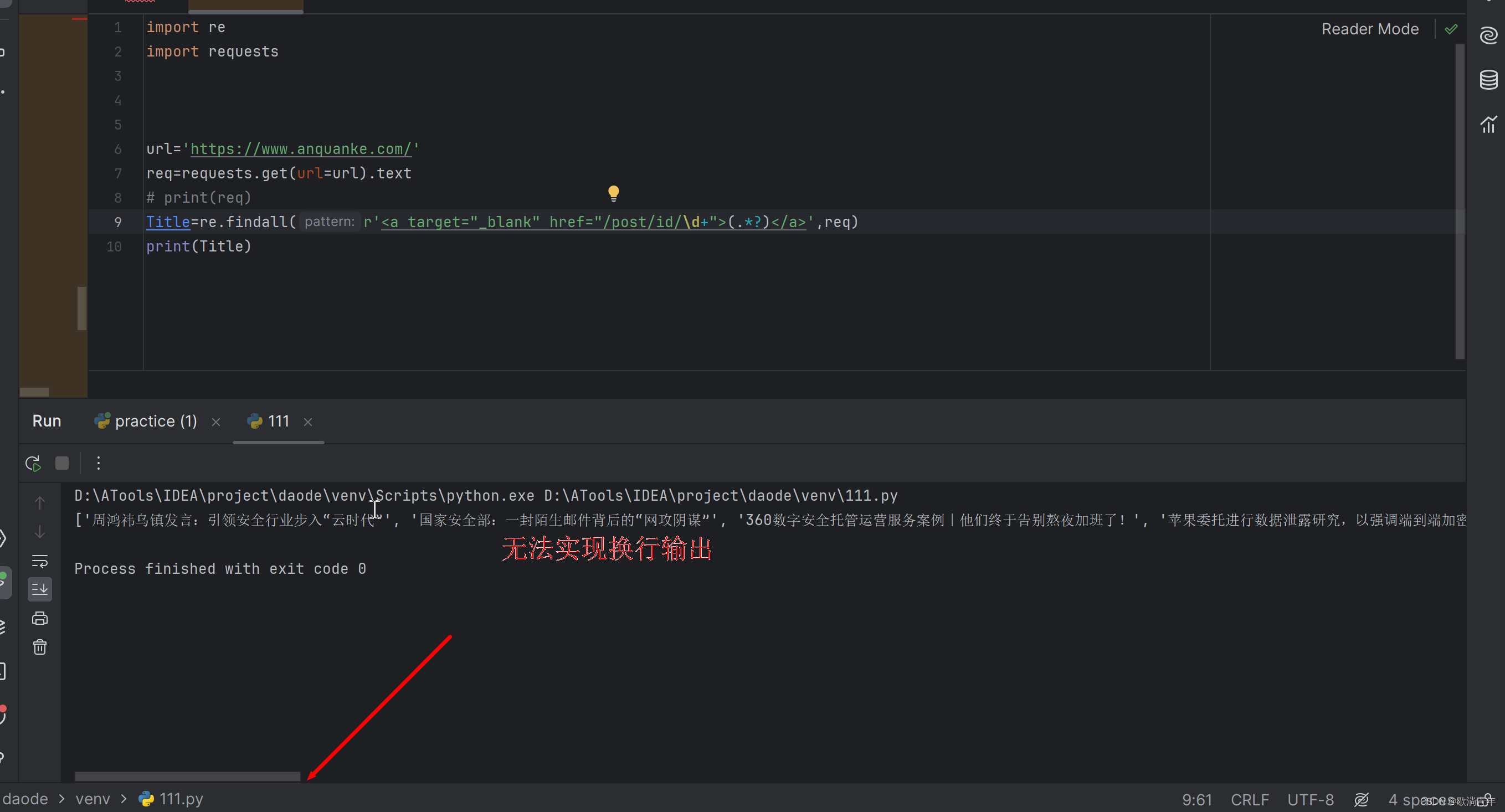
注意代码格式?
range() 取值 [?)
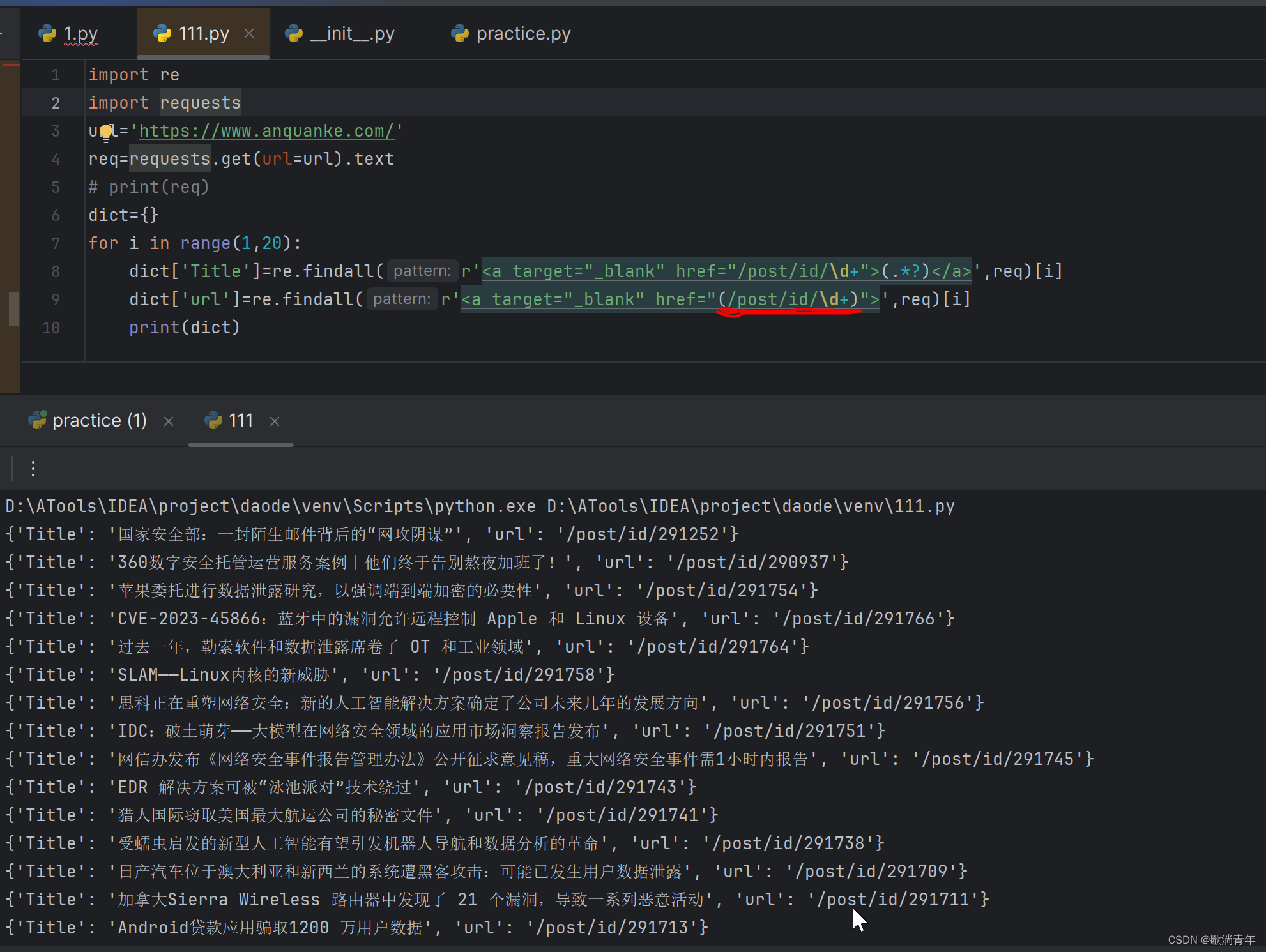
?最终代码:
import re
import requests
#headers={}
url='https://www.anquanke.com/'
req=requests.get(url=url).text
# print(req)
dict={}
for i in range(1,20):
dict['Title']=re.findall(r'<a target="_blank" href="/post/id/\d+">(.*?)</a>',req)[i]
dict['url']=re.findall(r'<a target="_blank" href="(/post/id/\d+)">',req)[i]
print(dict)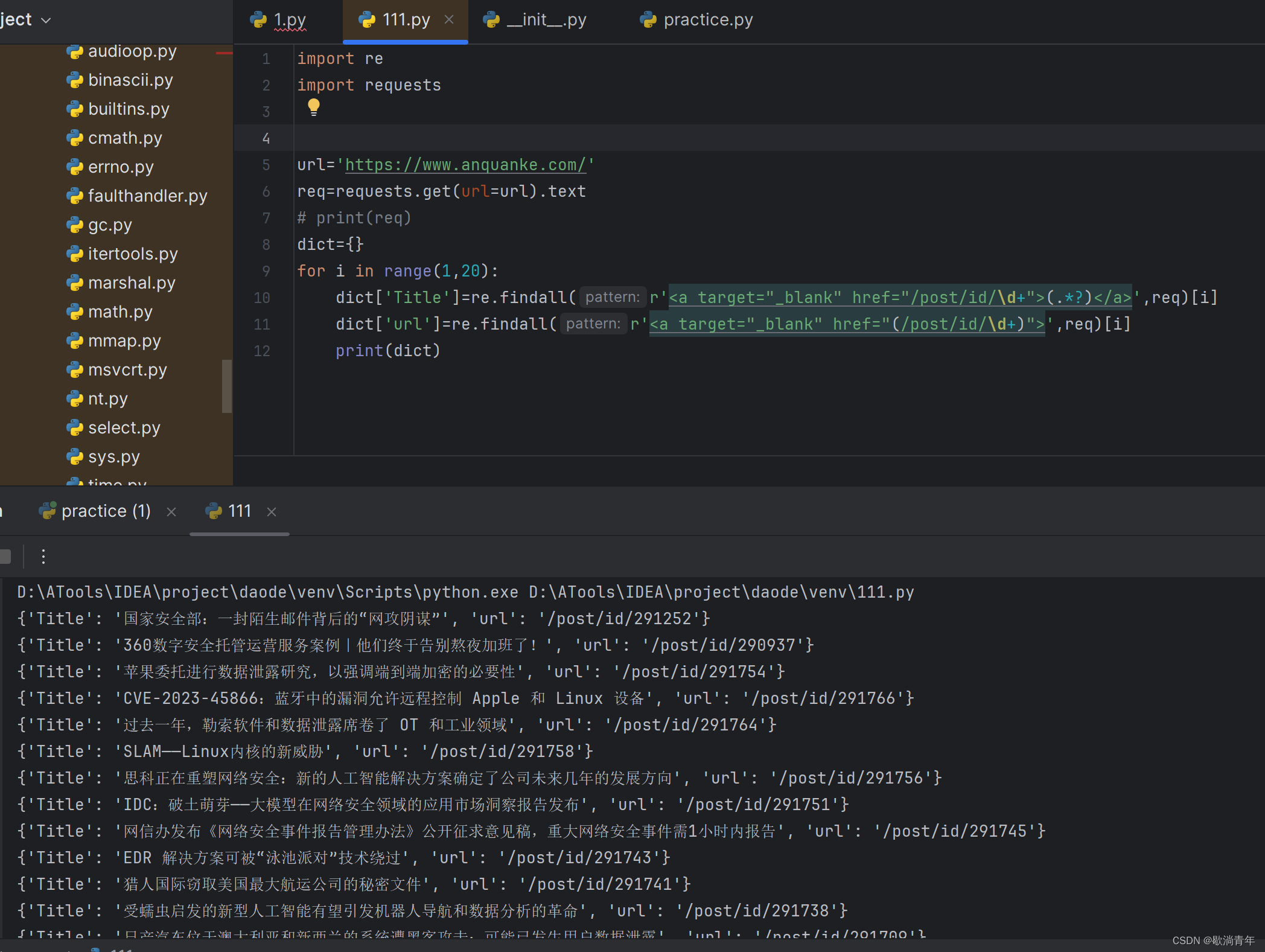
?优化后的代码:
import re
import requests
url='https://www.anquanke.com/'
req=requests.get(url=url)
print(req.status_code)
req=req.text
dict={}
Title=re.findall(r'<a target="_blank" href="(/post/id/\d+)">(.*?)</a>',req)
# print(Title)
for title in Title:
dict['Title']=title[1]
dict['url']=url+title[0]
print(dict)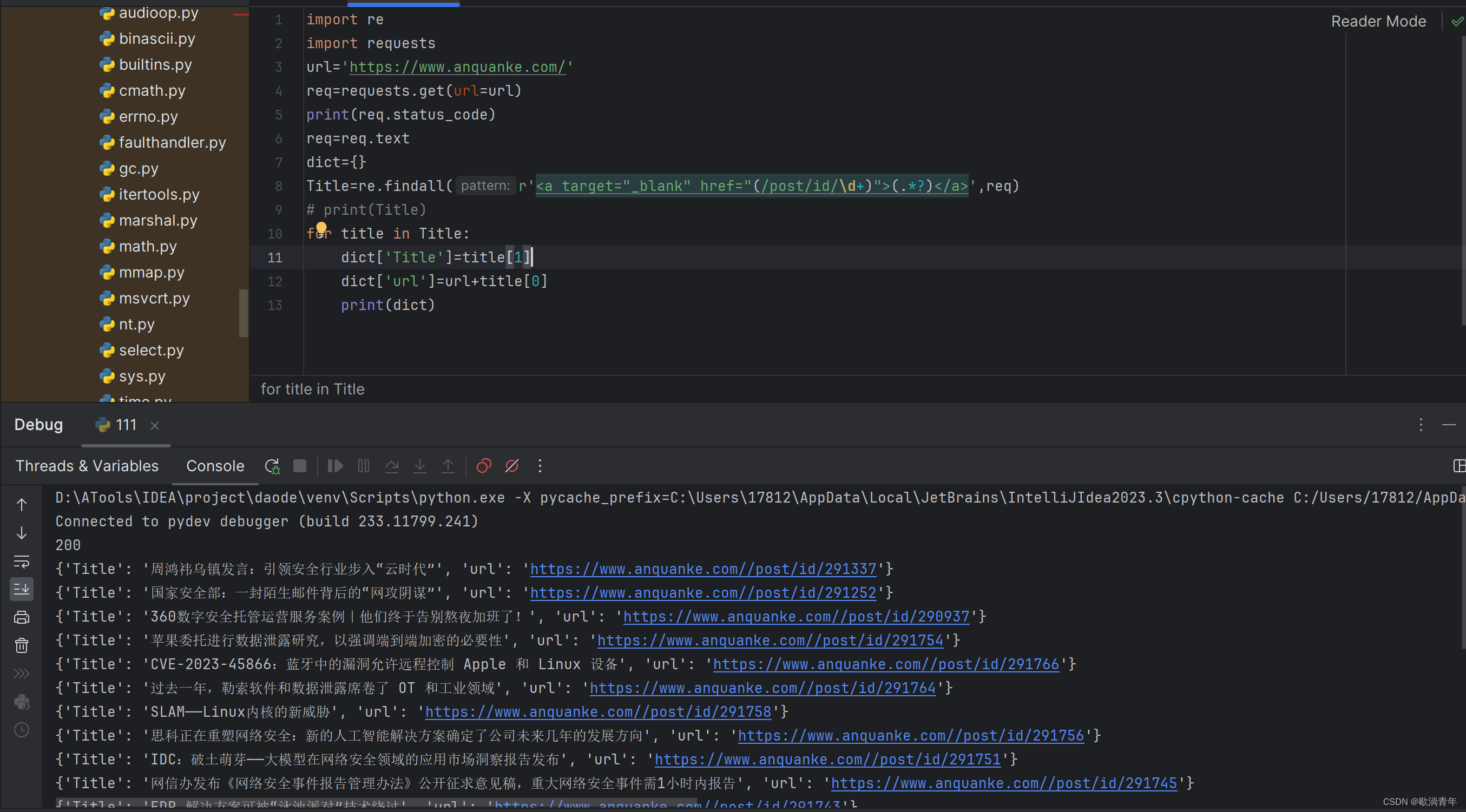
文章来源:https://blog.csdn.net/ssss39/article/details/134906871
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!