MYSQL数据库主从复制
一、为什么要做主从复制?
在业务复杂的系统中,mysql主从复制有这样几个情景,
1、有个SQL语句需要锁表,导致暂时不能使用读的服务,那么就影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运行。
2、做数据的热备,主库宕机后能够及时替换主库,保证业务可用性及连续性。
3、架构的扩展,业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
?
二、MySQL主从复制的原理
MySQL主从复制也可以称为MySQL主从同步,它是构建数据库高可用集群架构的基础。它通过将一台主机的数据复制到其他一台或多台主机上,并重新应用relay log中的SQL语句来实现复制功能。MySQL支持单向、双向、链式级联、异步复制,MySQL 5.5版本之后加入的半同步复制,5.6版本之后的GTID复制,MySQL 5.7的多源复制、并行复制、loss-less复制。
MySQL主从复制是一个异步的复制过程,主库发送更新事件到从库,从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。
几个概念需要了解下:
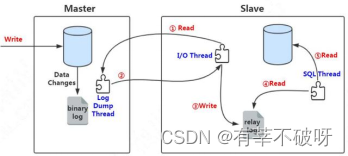
binlog:binary log,主库中保存所有更新事件日志的二进制文件。binlog是数据库服务启动的一刻起,保存数据库所有变更记录(数据库结构和内容)的文件。在主库中,只要有更新事件出现,就会被依次地写入到binlog中,之后会推送到从库中作为从库进行复制的数据源。
binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。 对于每一个即将发送给从库的SQL事件,binlog输出线程会将其锁住。一旦该事件被线程读取完之后,该锁会被释放,即使在该事件完全发送到从库的时候,该锁也会被释放。在从库中,当复制开始时,从库就会创建从库I/O线程和从库的SQL线程进行复制处理。
从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。 从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
从库通过创建两个独立的线程,使得在进行复制时,从库的读和写进行了分离。因此,即使负责执行的线程运行较慢,负责读取更新语句的线程并不会因此变得缓慢。比如说,如果从库有一段时间没运行了,当它在此启动的时候,尽管它的SQL线程执行比较慢,它的I/O线程可以快速地从主库里读取所有的binlog内容。这样一来,即使从库在SQL线程执行完所有读取到的语句前停止运行了,I/O线程也至少完全读取了所有的内容,并将其安全地备份在从库本地的relay log,随时准备在从库下一次启动的时候执行语句。
主从同步过程中主服务器有一个工作线程I/O dump thread,从服务器有两个工作线程I/O thread和SQL thread。主库把外界接收的SQL请求记录到自己的binlog日志中,从库的I/O thread去请求主库的binlog日志,并将binlog日志写到relay log中继日志中,然后从库重做中继日志的SQL语句。主库通过I/O dump thread给从库I/O thread传送binlog日志。
?三、常见的几种主从架构
1)单向主从模式:Master ——> Slave
2)双向主从模式:Master <====> Master
3)级联主从模式:Master ——> Slave1 ——> Slave2
4)一主多从模式
5)多主一从模式
四、mysql高可用HA架构
1、MySQL Cluster
?? ?MySQL Cluster(MySQL集群)是一个高性能、可扩展、集群化数据库产品,其研发设计的初衷就是要满足许多行业里的最严酷应用要求。这些应用中经常要求数据库运行的可靠性要达到99.999%。
?? ?MySQL Cluster是基于无共享的可由多台服务器组成的、同时对外提供数据管理服务的分布式集群系统。通过合理的配置,可以将服务请求在多台物理机上分发实现负载均衡 ;同时内部实现了冗余机制,在部分服务器宕机的情况下,整个集群对外提供的服务不受影响,从而能达到99.999%以上的高可用性。?
? MySQL Cluster设计之初出于性能考虑,将数据完全存放在内存当中,因此MySQL Cluster可以当作一种分布式的内存数据库。随着MySQL Cluster技术的成熟和需求的增加,目前MySQL Cluster已支持磁盘存储,可以指定数据表存储在磁盘上,减少MySQL Cluster集群对内存的需求,从而实现存储更大的容量。
2、MySQL Cluster(NDB)
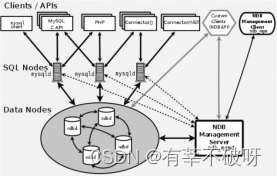
MySQL从结构看,由3类节点(计算机或进程)组成,分别是:?
管理节点: 用于给整个集群其他节点提供配置、管理、仲裁等功能。
数据节点: MySQL Cluster的核心,存储数据、日志,提供数据的各种管理服务。
SQL节点(API): 用于访问MySQL Cluster数据,提供对外应用服务。
3、MySQL Group Replication(MGR)
MMM(Master Replication Manager for MySQL)
MMM(Master Replication Manager for MySQL)是在MySQL Replication的基础上,对其进行优化。MMM是双主多从结构,这是Google的开源项目,使用Perl语言来对MySQL Replication做扩展,提供一套支持双主故障切换和双主日常管理的脚本程序,主要用来监控MySQL主主复制并做失败转移。
4、MHA(Master High Availability)
?? ?MHA(Master High Availability)是在MySQL Replication的基础上,对其进行优化。MHA是多主多从结构,这是日本DeNA公司的youshimaton开发,主要提供更多的主节点,但是缺少VIP(虚拟IP),需要配合keepalived等一起使用。
要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FPGA - 240102 - FPGA期末速成
- java——网络编程
- 制造领域 图号、零件号、物料号的区别
- 【算法】哈希表介绍 | 哈希表的链式地址法代码实现(C/C++)
- 运维工程师——敢问路在何方!
- 架构设计: 如何提供设计方案
- JAVA 学习 面试(二)多线程篇
- linux centos 添加临时ip
- macbookpro怎么录屏?Camtasia Studio2023进行屏幕录制的方法教程
- 手机崩溃日志的查找与分析