Redis常用内存淘汰策略?
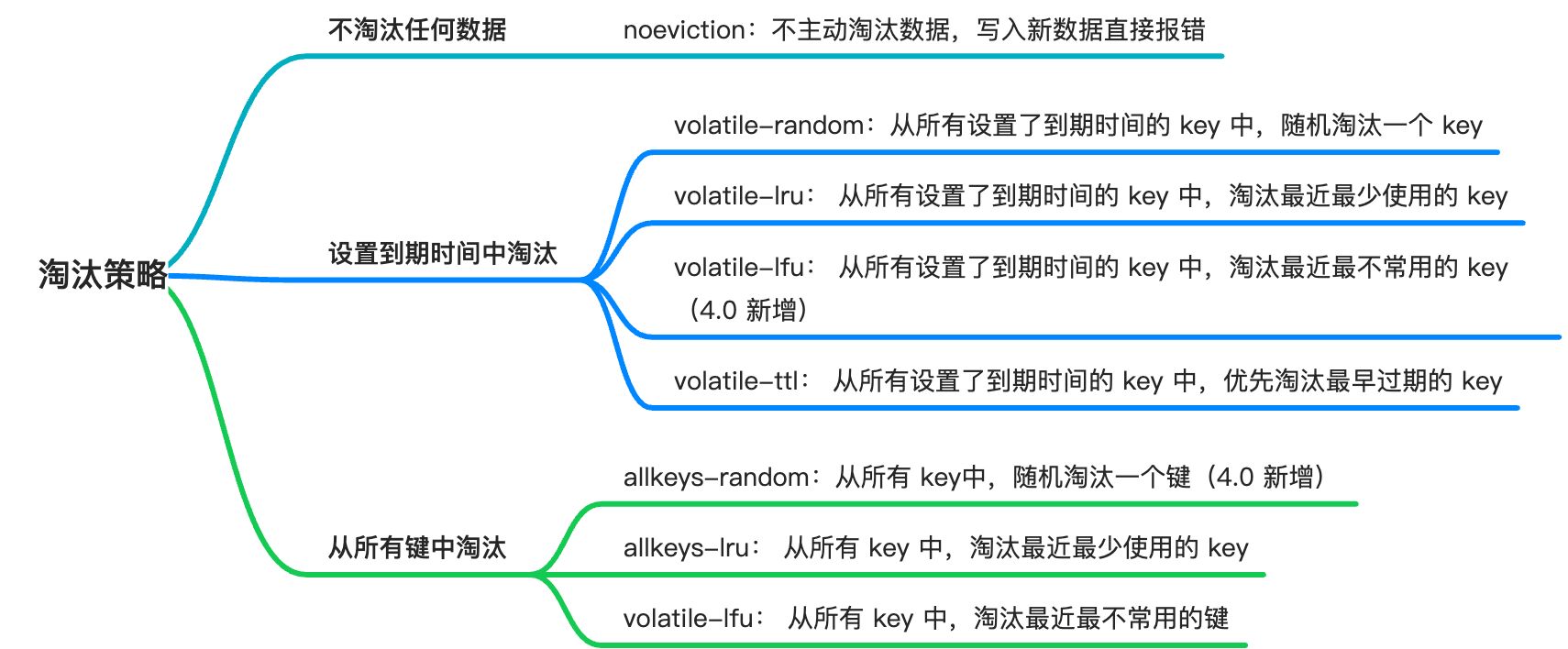
从淘汰范围来说可以分为不淘汰任何数据、只从设置了到期时间的键中淘汰和从所有键中淘汰三类。而从淘汰算法来分,又主要分为 random(随机),LRU(最近最少使用),以及 LFU(最近最不常使用)三种。
内存总是有限的,因此当 Redis 内存超出最大内存时,就需要根据一定的策略去主动的淘汰一些 key,来腾出内存,这就是内存淘汰策略。我们可以在配置文件中通过?maxmemory-policy?配置指定策略。
与到期删除策略不同,内存淘汰策略主要目的则是为了防止运行时内存超过最大内存,所以尽管最终目的都是清理内存中的一些 key,但是它们的应用场景和触发时机是不同的。
算上在 4.0 添加的两种基于 LFU 算法的策略, Redis 一共提供了八种策略供我们选择:
noeviction,不淘汰任何 key,直接报错。它是默认策略**。**volatile-random:从所有设置了到期时间的 key 中,随机淘汰一个 Key。volatile-lru: 从所有设置了到期时间的 key 中,淘汰最近最少使用的 key。volatile-lfu: 从所有设置了到期时间的 key 中,淘汰最近最不常用使用的 key(4.0 新增)。volatile-ttl: 从所有设置了到期时间的 key 中,优先淘汰最早过期的 key。allkeys-random:从所有 key中,随机淘汰一个键(4.0 新增)。allkeys-lru: 从所有 key 中,淘汰最近最少使用的 key。allkeys-lfu: 从所有 key 中,淘汰最近最不常用使用的键。
从淘汰范围来说可以分为不淘汰任何数据、只从设置了到期时间的键中淘汰和从所有键中淘汰三类。而从淘汰算法来分,又主要分为 random(随机),LRU(最近最少使用),以及 LFU(最近最不常使用)三种。
其中,关于 LRU 算法,它是一种非常常见的缓存淘汰算法。我们可以简单理解为 Redis 会在每次访问 key 的时候记录访问时间,当淘汰时,优先淘汰最后一次访问距离现在最早的 key。
而对于 LFU 算法,我们可以理解为 Redis 会在访问 key 时,根据两次访问时间的间隔计算并累加访问频率指标,当淘汰时,优先淘汰访问频率指标最低的 key。相比 LRU 算法,它避免了低频率的大批量查询造成的缓存污染问题。
顺带一提,只要是有类似缓存机制的应用或多或少都会面对这种问题,比如老生常谈的 MySQL 连表查询,在数据量大的时候也会造成缓存污染。
LRU 的实现
LRU 的全称为?Least Recently Used,也就是最近最少使用。一般来说,LRU 会从一批 key 中淘汰上次访问时间最早的 key。
它是一种非常常见的缓存回收算法,在诸如?Guava Cache、Caffeine等缓存库中都提供了类似的实现。我们自己也可以基于 JDK 的?LinkedHashMap?实现支持 LRU 算法的缓存功能。
传统的 LRU 算法实现通常会维护一个链表,当访问过某个节点后就将该节点移至链表头部。如此反复后,链表的节点就会按最近一次访问时间排序。当缓存数量到达上限后,我们直接移除尾节点,即可移除最近最少访问的缓存。
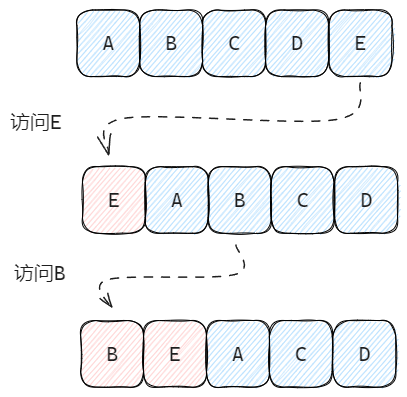
近似 LRU
Redis 中的 LRU 是近似 LRU(NearlyLRU)。当每次访问 key 时,Redis 会在结构体中记录本次访问时间,而当需要淘汰 key 时,将会从全部数据中进行抽样,然后再移除样本中上次访问时间最早的 key。
它的特点是:
- 仅当需要时再抽样,因而不需要维护全量数据组成的链表,这避免了额外内存消耗。
- 访问时仅在结构体上记录操作时间,而不需要操作链表节点,这避免了额外的性能消耗。
当然,有利就有弊,这种实现方式也决定 Redis 的 LRU 是并不是百分百准确的,被淘汰的 key 未必真的就是所有 key 中最后一次访问时间最早的。
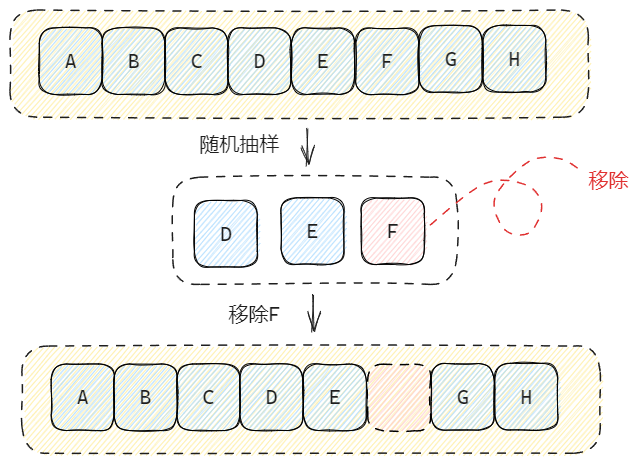
#a. 抽样大小
根据上述的内容,我们不难理解,当抽样的数量越大,LRU 淘汰 key 就越准确,相对的开销也更大。因此,Redis 允许我们通过?maxmemory-samples?配置采样数量(默认为 5),从而在性能和精度上取得平衡。
#b. 缓存污染
LRU 有个最大问题,就是它只认最近一次访问时间。而如果出现系统偶尔需要一次性读取大量数据的时候,会大规模更新 key 的最近访问时间,从而导致真正需要被频繁访问的 key 因为最近一次访问时间更早而被直接淘汰。这种情况被称为缓存污染。
如何选择
软件工程没有银弹,我们不可能指望存在一个能完美适用于所有场景的内存淘汰策略。
在实际场景中,我们需要结合业务特点、数据量大小、数据的冷热……等多个维度来选择合适的淘汰策略。
比如:
- 当使用 Redis 来缓存用户动态时,由于热门用户的动态相对于普通用户往往会被更高频的访问,因此我们可以选择基于 LRU 或者 LFU 算法的策略保证热点数据不会被轻易淘汰。
- 当使用 Redis 缓存菜单树时,由于菜单树数据大部分情况下没有明确的热点区分,因此可以考虑使用随机淘汰策略平衡各个数据的访问频率。
当然,调整淘汰策略也只是优化方案的一种。条件允许的话,在特定情况下直接增加内存、将单机改为集群或者缓存预热同样可以带来显著的收益。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL修炼手册15:备份与恢复:保障数据安全的重要手段
- docker搭建pg并通过xorm操作
- OpenCL编程快速入门
- 插火把(洛谷)
- macOS编译ckb-next
- SCA面面观 | 如何生成一份软件物料清单SBOM?
- Vue - 优雅地处理点击事件:预置防抖
- PLAN B KRYPTO ASSETS GMBH & CO. KG 普兰资产管理公司
- 编程探秘:Python深渊之旅-----数据可视化(八)
- 3d云渲染平台哪个好?如何挑选好的云渲染平台?