网络和Linux网络_13(高级IO+多路转接)五种IO模型+select编程
目录
1.?五种IO模型
在学习系统部分的时候就讲解过IO,之前学习的IO就是从文件中读数据和写数据,到了后来学习网络的时候,我们知道,从网络中读取和写入数据也是IO,那么IO到底是什么呢?今天来更深刻的认识一下IO。
就拿读取数据来说,无论是调用read还是recv,在文件描述符所指向的struct file中的接收缓冲区如果没有数据的时候,都会阻塞等待。
当缓冲区中有数据后,才会进行读取,所谓读取,本质就是在拷贝,就是将内核缓冲区中的数据拷贝到用户缓冲区中供用户去使用。
无论是等待还是拷贝,都是读取的过程,二者缺一不可。
IO = 等 + 数据拷贝。
那么什么是高效的IO呢?我们知道,IO过程中我们在意的是拷贝,而不是等待,由于各种技术的发展,拷贝所花费的时间几乎是固定的,是由电路或者系统等等机制来保证的,所以拷贝的效率已经很难再有提升了。
高效的IO就是减少等待的比重。
钓鱼的故事
IO的种类有五种,介绍之前讲一个钓鱼的故事简单理解一下:
① 阻塞式IO ? ? ??
? ? ? ? 老赵喜欢钓鱼,一坐就是一整天,他亲历亲为,自己等鱼上钩(等待事件),自己在将鱼钓上来(数据拷贝)。
? ? ? ? 阻塞式IO,我们最常见的IO,阻塞式等待。
② 非阻塞式IO ? ? ??
? ? ? ? 老钱也喜欢钓鱼,他不像老赵干干等着,他看到没有鱼鳔没有上下浮动,就去做其他的事情,偶尔会来检查下是否有鱼上钩,当有鱼上钩了,他会将鱼钓上来。? ? ? ? 非阻塞式IO,程序调用函数,该函数检查是否有事件就绪,没有就继续进行下一项任务,偶尔再来检查下是否就绪。非阻塞式轮询检测等待。
③ 信号驱动式IO
? ? ? ? 老孙也喜欢钓鱼,他有个高科技,他的鱼鳔上有个报警器,他将鱼钩扔进河流就不再管了,去做自己的事情,直到报警器响起,他才来将鱼钓上来。? ? ? ? 信号驱动式IO,当事件就绪,系统会向进程发送SIGIO的信号,进程会调用回调函数来处理IO。
④ 多路复用IO
? ? ? ? 老李酷爱钓鱼并财大气粗精力十足,他一下子买了10个钓鱼用具,都将这些用具同时甩进了河流中,同时等待这10个鱼鳔的响应,哪个上下浮动就去处理将鱼钓上来。? ? ? ? 多路复用IO,多个事件都没有就绪,进程会被阻塞,轮询式检测事件,哪一个就绪就去处理哪一个。
前面4个都属于同步IO模型。
⑤ 异步IO
? ? ? ? 老周也喜欢钓鱼,他是一个老板,自己事情很忙,他告诉手下,他想钓鱼,他的手下就去钓鱼,钓鱼的全过程老周都没有参与,但是收获了鱼。? ? ? ? 在异步IO模型中,进程只需要告诉OS它要读取数据就立即返回,当数据就绪之后,OS会自动的将数据从内核空间拷贝到进程空间。?
同步IO无论是多路复用还是信号驱动,最后都要亲力亲为的将数据从内核缓冲区拷贝到进程空间。而异步IO是直接获取结果,因为待数据就绪之后OS会自动拷贝数据。
下面分别正式介绍一下五种IO模型:
1.1 阻塞IO
① 阻塞IO:在内核将数据准备好之前,系统调用会一直等待,所有的套接字以及文件,默认都是阻塞方式。

如上图所示便是阻塞IO的示意图,在进程调用recvfrom从内核缓冲区中读取数据时,如果数据没有准备好,进程就会阻塞在调用处等待,直到数据准备好,才会将内核缓冲区的数据拷贝到用户缓冲区,并且给进程返回值。
阻塞IO是最常见的IO模型,也是最简单的IO模型,我们之前写的所有IO都是阻塞式的。
1.2 非阻塞IO(代码)
② 非阻塞IO:如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EAGAN或者EWOULDBLOCK错误码。
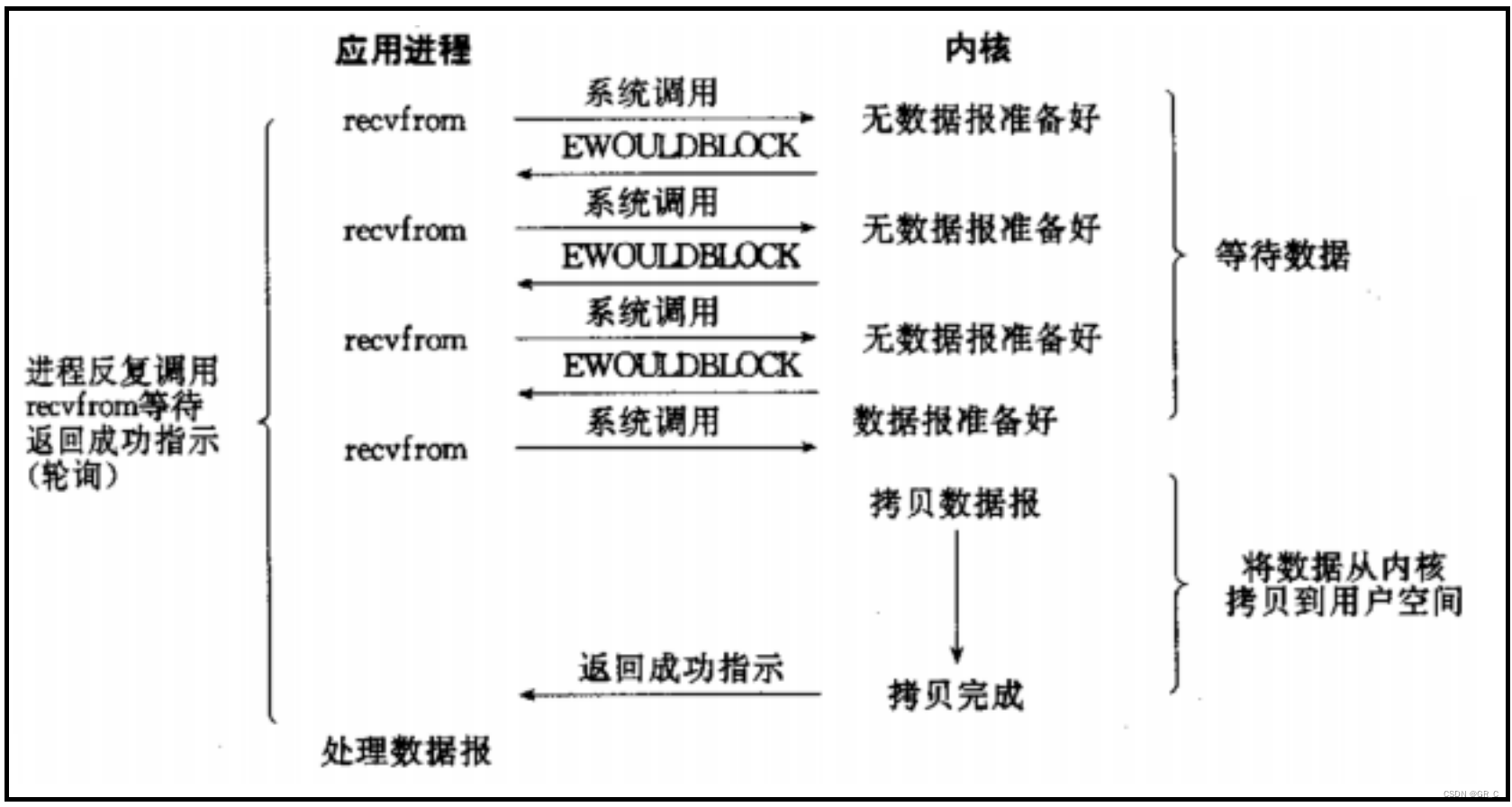
如上图所示,进程调用recvfrom从内核缓冲区中读取数据时,即使数据没有准备好,仍然会给进程一个返回一个EAGAN或者EWOULDBLOCK。
通常情况下使用这种IO方式时,如果返回EAGAN或者EWOULDBLOCK,说明数据没有准备好,就会再次调用recvfrom去读取数据,如此反复,直到数据准备好并且完成拷贝,最后返回表示成功的返回值。
非阻塞IO需要程序员以循环的方式反复尝试读写文件描述符,这个过程称为轮询。这对CPU来说是较大的浪费,一般只有特定场景下才使用。
默认情况下,文件描述符fd指向的struct file中的缓冲区的阻塞式IO,所以我们前面无论是在进行文件操纵还是使用套接字的时候,都是阻塞IO。
以前的阻塞式IO写法:
Makefile:
myfile:myfile.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f myfilemyfile.cc:
#include <iostream>
#include <unistd.h>
int main()
{
char buffer[1024];
while (true)
{
sleep(1);
errno = 0;
ssize_t s = read(0, buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = 0;
std::cout << "echo# " << buffer << std::endl;
}
else
{
std::cout << "read \"error\"" << std::endl;
}
}
return 0;
}编译运行:
没有数据的时候一直阻塞等待。
fcntl设置??一个文件描述符的系统接口,默认都是阻塞IO。
man fcntl:

- int fd:要修改文件的文件描述符fd。
- 返回值fl:大于0表示当前文件的状态,小于0表示调用失败。
- int cmd:对fd所指向的文件要进行的操作,可以传递两个参数:
- F_GETFL:用来获取该文件当前的状态。
- F_SETFL:用来设置该文件当前的状态。
- 可变参数部分:可以传递参数有O_RDONLY,O_WRONLY等等,最重要的是O_NONBLOCK非阻塞IO方式,但是在传参的时候,必须和fl进行按位或,如fl | O_NONBLOCK,意思是在原fl的基础上新增O_NONBLOCK选项。
下面写个函数把0号描述符(标准输入)设置成非阻塞:
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
bool SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL); // 在底层获取当前fd对应的文件读写标志位(f_getfl)
if (fl < 0)
{
return false;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK); // 将文件设置成非阻塞IO(f_setfl, fl | o_nonblock 是在原始的基础上新增)
return true;
}
int main()
{
SetNonBlock(0); //只要设置一次,后续就都是非阻塞了
char buffer[1024];
while (true)
{
sleep(1);
errno = 0;
ssize_t s = read(0, buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = 0;
std::cout << "echo# " << buffer << std::endl;
}
else
{
std::cout << "read \"error\"" << std::endl;
}
}
return 0;
}
没有数据的时候一直读取,读取不到打印了read “error”。
再重新来看一下read系统调用:man 2 read:

如上图所示,可以设置的错误码有这么多,虽然返回值是-1,但是不同的错误码代表着不同的情况,其中EAGAIN或者EWOULDBLOCK表示的就是数据没有准备好,需要稍后再读。(EAGAIN和EWOULDBLOCK都是宏,而且它们的值都是11,本质上是一个东西。)
读取数据时,内核中缓冲区的数据没有准备好并没有错,这是很正常的情况。所以错误码EAGAIN并不表示错误了,只是表示数据暂时没有准备好,需要稍后再来读取。
错误码EINTR表示信号被中断了,改下代码:
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
#include <cerrno>
#include <cstring>
bool SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL); // 在底层获取当前fd对应的文件读写标志位(f_getfl)
if (fl < 0)
{
return false;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK); // 将文件设置成非阻塞IO(f_setfl, fl | o_nonblock 是在原始的基础上新增)
return true;
}
int main()
{
SetNonBlock(0); //只要设置一次,后续就都是非阻塞了
char buffer[1024];
while (true)
{
sleep(1);
errno = 0;
ssize_t s = read(0, buffer, sizeof(buffer) - 1); //出错,不仅仅是错误返回值,errno变量也会被设置,表明出错原因
if (s > 0)
{
buffer[s-1] = 0; // -1去掉回车符 (下一行代码的错误码是0,因为是成功地,没被设置(成功不关心错误码))
std::cout << "echo# " << buffer << " success errno: " << errno << " errstring: " << strerror(errno) << std::endl;
}
else
{
// 如果失败的errno值是11,就代表其实没错,只不过是底层数据没就绪
//std::cout << "read \"error\" " << " errno: " << errno << " errstring: " << strerror(errno) << std::endl;
if(errno == EWOULDBLOCK || errno == EAGAIN) // ewouldblock eagain
{
std::cout << "当前0号fd数据没有就绪, 可以再试试" << std::endl;
continue;
}
else if(errno == EINTR) // eintr
{
std::cout << "当前IO可能被信号中断, 可以再试试" << std::endl;
continue;
}
else
{
// 进行差错处理
}
}
}
return 0;
}编译运行:
此时进程并没有阻塞,而是在轮询,数据没有准备时可以执行其他任务。
1.3?信号驱动IO
信号驱动IO:内核将数据准备好的时候,使用SIGIO信号通知应用程序进行IO操作。
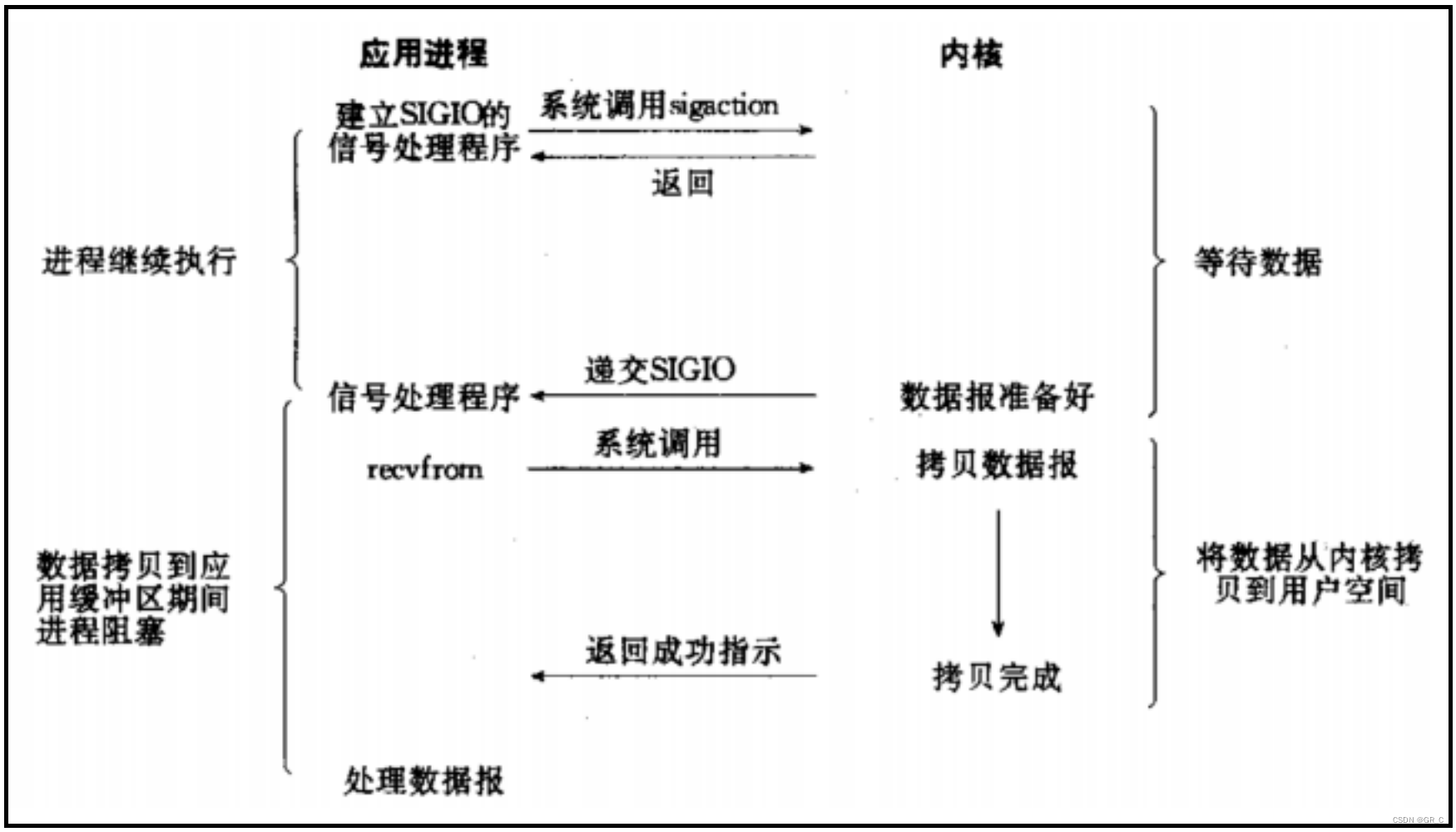
如上图所示信号驱动IO模型,该模式调用recvfrom并不是在主进程中调用,而且使用signal注册信号处理函数,在信号处理函数中调用recvfrom。
进程一直在正常运行,执行自己的逻辑,当内核接收缓冲区有数据到来时,进程会收到系统给发的信号SIGIO,然后就会调用该信号注册的处理方式,在信号处理方式中调用recvfrom读取缓冲区中的数据。
一旦进入信号处理函数中,说明内核缓冲区中的数据已经准备好了,在这里只需要读取,而不再需要等待。
1.4 多路转接IO
多路转接IO:虽然从流程图上看起来和阻塞IO类似,实际上最核心在于多路转接IO能够同时等待多个文件描述符的就绪状态。

如上图多路转接IO模式,该模式中,将IO的等待和拷贝两个步骤分开了。
进程调用select系统调用来等待内核缓冲区中数据就绪,当数据就绪以后通知进程调用recvfrom来将数据拷贝到用户缓冲区中。
IO多路转接模式下,可以同时等待多个文件,当一个或者多个文件的缓冲区中数据就绪时,就会通知上层用户来读取。
此时虽然也有等,但是等的比重就降低了,因为能够一次等待多个文件,进而让上层用户一次来读取多个缓冲区中的数据,拷贝的比重就增加了,从而提高了IO的效率。
1.5?异步IO
异步IO:由内核在数据拷贝完成时,通知应用程序直接去用户缓冲区中使用数据。
同步和异步关注的是消息通信机制:
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回,但是一旦调用返回,就得到返回值了。也就是由调用者主动等待这个调用的结果。
异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。
当一个异步过程调用发出后,调用者不会立刻得到结果,而是在调用发出后,被调用者通过状态、信号等来通知调用者,或通过回调函数处理这个调用。
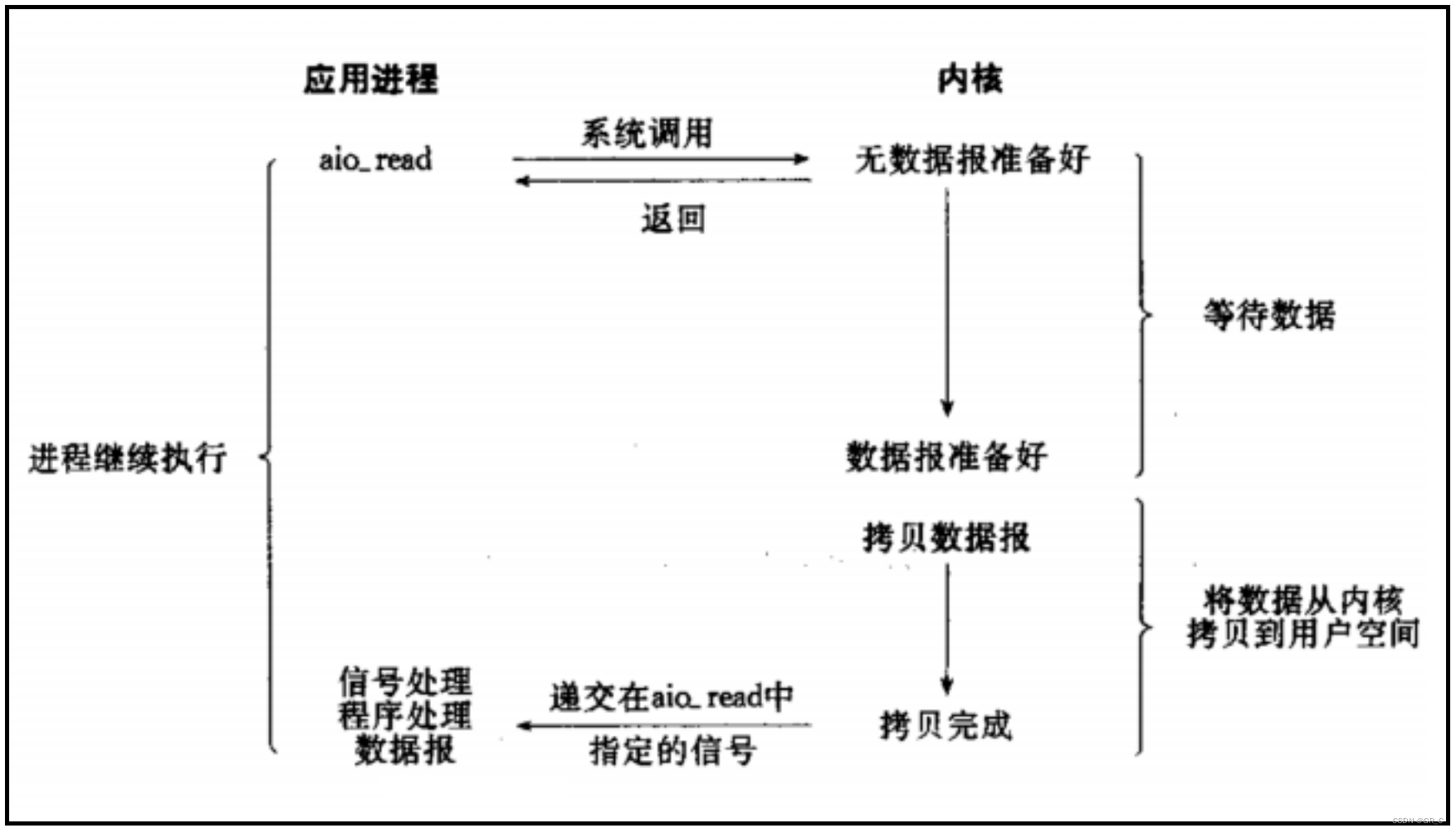
如上图所示异步IO模式示意图,进程调用aio_read,将等待数据就绪和将数据拷贝到用户缓冲区两个步骤的工作全部交给操作系统来完成。
当操作系统完成两个步骤以后,通知上层用户直接去用户缓冲区中使用数据即可。
信号驱动是告诉进程可以从内核缓冲区中拷贝数据到用户缓冲区了,而异步IO连拷贝这一步也不用做了,直接使用数据。
另外,我们回忆在学习多进程多线程的时候,也提到同步和互斥,这里的同步通信和进程之间的同步是完全不同的概念。
进程/线程同步也是进程/线程之间直接的制约关系,是为完成某种任务而建立的两个或多个线程,这个线程需要在某些位置上协调他们的工作次序而等待、传递信息所产生的制约关系。尤其是在访问临界资源的时候。
比较这五种IO模式,阻塞IO模式肯定是效率最低的,但也是最简单的(所以最常用),非阻塞以及信号驱动的IO模式,同样需要参加IO的等待和拷贝两个过程,对于IO的效率是相同的。
异步IO模式也是同样的道理,虽然等待和拷贝不是由线程去做的,而是由操作系统在做,但是线程也得在等待和拷贝完成后才能使用数据,所以IO的效率还是没有提高的。
而多路转接不一样,虽然等待和拷贝两个过程都参与,但是等待时可以一次等待多个文件描述符,拷贝时也是可以拷贝多个文件描述符中的数据。
由于等待的文件描述符数量多,所以有数据就绪的概率就高,进行拷贝也更加频繁。站在上帝视角来看,多路转接模式下,进程在单位时间内进行拷贝的次数要比其他几种模式多。
所以多路转接更加高效,而我们研究的重点也在多路转接模式上,主要有select,poll,epoll三种方式。
其他高级IO:
非阻塞IO,纪录锁,系统V流机制,I/O多路转接(也叫I/O多路复用),readv和writev函数以及存储映射 IO(mmap),这些统称为高级IO。(前两个加粗的会讲,第三个有兴趣可以自己了解)
2. select编程
系统提供select函数来实现多路复用输入/输出模型。
select系统调用是用来让我们的程序监视多个文件描述符的状态变化的,
程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变。
2.1?select函数
man select:

如上图所示,该系统调用有5个参数。
int nfds:要等待的所有文件描述符中的最大fd+1。
假设现在要等待的文件有3个,文件描述符分别是3,5,7,则传参时就需要传7+1=8给nfds。
fd_set* reads:等待读取就绪文件描述符的位图。
select等待的文件有不同的事件会就绪,比如读取就绪,写就绪,异常就绪等等。
fd_set就是一个位图。它有多个比特位,每一个比特位代表一个文件描述符,比特位的状态表示该比特位是否被监听。

如上图所示便是fd_set位图示意图,其中比特位的顺序由低到高从左向右,比特位的下标就是代表文件描述符fd,比特位的内容表示状态,这张图中,文件描述符为1,3,1023的三个文件描述符需要被select监视。
fd_set类型的大小是8字节,所以有1024个比特位,这意味着使用select最多监视1024个文件描述符。
将接收缓冲区所在文件的文件描述符设置到readfds中,当该缓冲区有数据到来时(读就绪),select就会通知上层进程去读取该缓冲区中的数据。
fd_set* writefds:等待写入就绪文件描述符所在位图。
该位图和readfds一样,只是操作系统等待的事件由读就绪变成了写就绪,当发送缓冲区空了以后(写就绪),操作系统就会通知上层进程向该缓冲区中写入数据。
fd_set* exceptfds:等待异常就绪文件描述符所在位图。
打开的文件,如TCP中的套接字,当对端关闭套接字以后,自己这边的套接字就会出现异常,此时操作系统就会通知上层进程处理该异常。
需要操作系统监视哪里事件就将对应的位图传给select,待事件就绪后就会通知上层进程去处理,如果不需要监视直接设置成nullptr就行。
struct timeval* timeout:设置等待方式。
man select里的:

如上图所示struct timeval类型的定义,有两个成员,第一个是秒,第二个是微秒。
该参数传入nullptr的时候,select是阻塞等待,只有当一个或者多个文件描述符就绪时才会通知上层进程去读取数据。
该参数如果是struct timeval timeout = {0, 0},select是非阻塞等待,就需要使用轮询的方式。
该参数如果设置了具体值,如struct timeval timeout = {5, 0},select在5秒内阻塞等待,(后面的0只是0毫秒)如果在5秒内有文件描述符就绪,则通知上层,如果没有文件描述符就绪则超时返回。
返回值:

ret > 0表示有ret个文件描述符fd就绪了,
ret == 0表示没有文件描述符fd就绪,超时返回,
ret == -1(小于0)表示select调用失败了。
为了使用方便,内核还提供了一组宏供用户去设置fd_set位图,将对应的文件描述符设置进去,避免了我们自己使用按位或等运算给位图赋值的麻烦:man 2 select里的:

FD_CLR是将位图中指定文件描述符fd所对应位的状态清零,表示不用操作系统再等待该文件。
FD_ISSET用来判断特定文件描述符fd是否被设置进了位图,如果设置返回1,没有则返回0。
FD_SET用来将指定文件描述符fd对应的位图设置为1,表示需要操作系统等待该文件。
FD_ZER用来将整个位图清空,此时操作系统不等待任何一个文件。
select的五个参数中,后面四个都是输入输出型参数,都是传的指针,意味着操作系统和用户共用一个参数。
调用select传参时,表示用户告诉内核,需要操作系统等待哪个文件,以及哪种事件。操作系统第一时间会将传入的位图参数清空,每就绪一个文件,传入位图相应比特位置一,然后传返回值给用户。
此时就是内核在告诉用户,你关心的多个fd,有哪些已经就绪了。
用户根据返回值来处理调用结果,如果是ret>0,则判断自己当初设置进位图中的文件描述符是否被置一了,如果置一了,说明该文件所对应的事件就绪了,用户就可以进行进一步处理。
由于传入的参数是输入输出型的,操作系统等待后的结果也是在这个参数中,所以用户必须自己再维护一个数据结构来记录自己最初设置要等待的文件描述符。
根据select返回状态以及操作系统修改后的位图,与自己维护的记录结构作对比,得出自己当初要等待的文件是否就绪的结论。
无论是读取数据,还是写入数据,再或者是异常事件,都是采用这样的方式和机制。
struct timeval* timeout表示的阻塞等待时间,操作系统内部也会进行修改,假设初值是{5, 0}表示阻塞等待5s中,如果5s内没有事件就绪则select返回0,表示超时返回,此时原本传入的time的值也变成了{0, 0}。
如果5s内有事件就绪,假设操作系统等待了3秒,selsect返回值大于0,表示不是超时返回,有事件就绪,此时原本传入的time的值也变成了{2, 0},表示设置的阻塞事件还剩两秒。
所以在轮询过程中,每循环一次就需要重新设置一下时间,否则第一次超时返回后,time的值就成了0,之后select就成了非阻塞IO,与初衷不符。
输入输出型参数的作用就是让用户和内核之间相互沟通,互相知晓对方要关心的。
2.2 简易select服务器
前面将创建套接字的代码封装成了一个Sock类,这里再在每个函数前面加上static(这样就类似面向过程了),使用的时候直接调用即可,同样可以将其作为一个小组件。
把之前写的Log.hpp和Sock.hpp拷过来,把Log.hpp的debug返回的注释掉,改一下Sock.hpp。
Sock.hpp:
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <cerrno>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <ctype.h>
#include "Log.hpp"
class Sock
{
private:
const static int gbacklog = 20; // listen的第二个参数,现在先不管
public:
Sock()
{}
~Sock()
{}
static int Socket()
{
int listensock = socket(AF_INET, SOCK_STREAM, 0); // 域 + 类型 + 0 // UDP第二个参数是SOCK_DGRAM
if (listensock < 0)
{
logMessage(FATAL, "create socket error, %d:%s", errno, strerror(errno));
exit(2);
}
int opt = 1;
setsockopt(listensock, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
logMessage(NORMAL, "create socket success, listensock: %d", listensock);
return listensock;
}
static void Bind(int sock, uint16_t port, std::string ip = "0.0.0.0")
{
struct sockaddr_in local;
memset(&local, 0, sizeof local);
local.sin_family = AF_INET;
local.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &local.sin_addr);
if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0)
{
logMessage(FATAL, "bind error, %d:%s", errno, strerror(errno));
exit(3);
}
}
static void Listen(int sock)
{
if (listen(sock, gbacklog) < 0)
{
logMessage(FATAL, "listen error, %d:%s", errno, strerror(errno));
exit(4);
}
logMessage(NORMAL, "init server success");
}
// 一般情况下:
// const std::string &: 输入型参数
// std::string *: 输出型参数
// std::string &: 输入输出型参数
static int Accept(int listensock, std::string *ip, uint16_t *port)
{
struct sockaddr_in src;
socklen_t len = sizeof(src);
int servicesock = accept(listensock, (struct sockaddr *)&src, &len);
if (servicesock < 0)
{
logMessage(ERROR, "accept error, %d:%s", errno, strerror(errno));
return -1;
}
if (port)
*port = ntohs(src.sin_port);
if (ip)
*ip = inet_ntoa(src.sin_addr);
return servicesock;
}
static bool Connect(int sock, const std::string &server_ip, const uint16_t &server_port)
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(server_port);
server.sin_addr.s_addr = inet_addr(server_ip.c_str());
if (connect(sock, (struct sockaddr *)&server, sizeof(server)) == 0)
return true;
else
return false;
}
};Log.hpp:
#pragma once
#include <iostream>
#include <cstdio>
#include <cstdarg>
#include <ctime>
#include <string>
// 日志是有日志级别的
#define DEBUG 0
#define NORMAL 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
const char *gLevelMap[] = {
"DEBUG",
"NORMAL",
"WARNING",
"ERROR",
"FATAL"
};
// #define LOGFILE "./threadpool.log"
#define LOGFILE "./calculator.log"
// 完整的日志功能,至少: 日志等级 时间 支持用户自定义(日志内容, 文件行,文件名)
void logMessage(int level, const char *format, ...) // 可变参数
{
// #ifndef DEBUG_SHOW
// if(level== DEBUG)
// {
// return;
// }
// #endif
char stdBuffer[1024]; // 标准日志部分
time_t timestamp = time(nullptr); // 获取时间戳
// struct tm *localtime = localtime(×tamp); // 转化麻烦就不写了
snprintf(stdBuffer, sizeof(stdBuffer), "[%s] [%ld] ", gLevelMap[level], timestamp);
char logBuffer[1024]; // 自定义日志部分
va_list args; // 提取可变参数的 -> #include <cstdarg> 了解一下就行
va_start(args, format);
// vprintf(format, args);
vsnprintf(logBuffer, sizeof(logBuffer), format, args);
va_end(args); // 相当于ap=nullptr
printf("%s%s\n", stdBuffer, logBuffer);
// FILE *fp = fopen(LOGFILE, "a"); // 追加到文件
// fprintf(fp, "%s%s\n", stdBuffer, logBuffer);
// fclose(fp);
}Makefile:
selectServer:main.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f selectServermain.cc:
#include "selectServer.hpp"
#include <memory>
int main()
{
std::unique_ptr<SelectServer> svr(new SelectServer());
svr->Start();
return 0;
}select的第五个参数timeout
下面就开始慢慢写selectServer.hpp了,先写个大概跑起来:
#ifndef __SELECT_SVR_H__
#define __SELECT_SVR_H__
#include <iostream>
#include <sys/select.h>
#include "Log.hpp"
#include "Sock.hpp"
using namespace std;
// select 这里只完成读取,写入和异常不做处理 -- epoll(写完整)
class SelectServer
{
public:
SelectServer(const uint16_t &port = 8080)
: _port(port)
{
_listensock = Sock::Socket();
Sock::Bind(_listensock, _port);
Sock::Listen(_listensock);
logMessage(DEBUG, "%s", "create base socket success");
}
void Start()
{
fd_set rfds;
FD_ZERO(&rfds);
struct timeval timeout = {5, 0};
while (true)
{
// 如何看待listensock -> 获取新连接,我们把它依旧看做成为IO,input事件,如果没有连接到来呢 -> 阻塞
// int sock = Sock::Accept(listensock, ...); //不能直接调用accept了
FD_SET(_listensock, &rfds); // 将listensock添加到读文件描述符集中
int n = select(_listensock + 1, &rfds, nullptr, nullptr, &timeout);
switch (n)
{
case 0:
logMessage(DEBUG, "%s", "time out..."); // 可以添加回调函数
sleep(1);
break;
case -1:
logMessage(WARNING, "select error: %d : %s", errno, strerror(errno));
break;
default:
// 成功的 要处理事件
logMessage(DEBUG, "get a new link event...");
sleep(1);
break;
}
}
}
~SelectServer()
{
if (_listensock >= 0)
close(_listensock);
}
private:
uint16_t _port;
int _listensock;
};
5秒后,每1秒打印了一次time out,不应该一直每5秒打印一次time out吗?
这是因为select的第五个参数为输入输出型参数,可以把timeout放在循环里面:

然后现象就是每5秒打印一次了,运行图片和上面一样,看不出来就不贴了。
再改成非阻塞{0,0},然后把case 0 的sleep(1); 注释掉就看到time out刷屏了。

这样就验证了select的第五个参数,然后后面这个参数就设置成nullptr阻塞的就行了。
改成nullptr后试着链接一下:
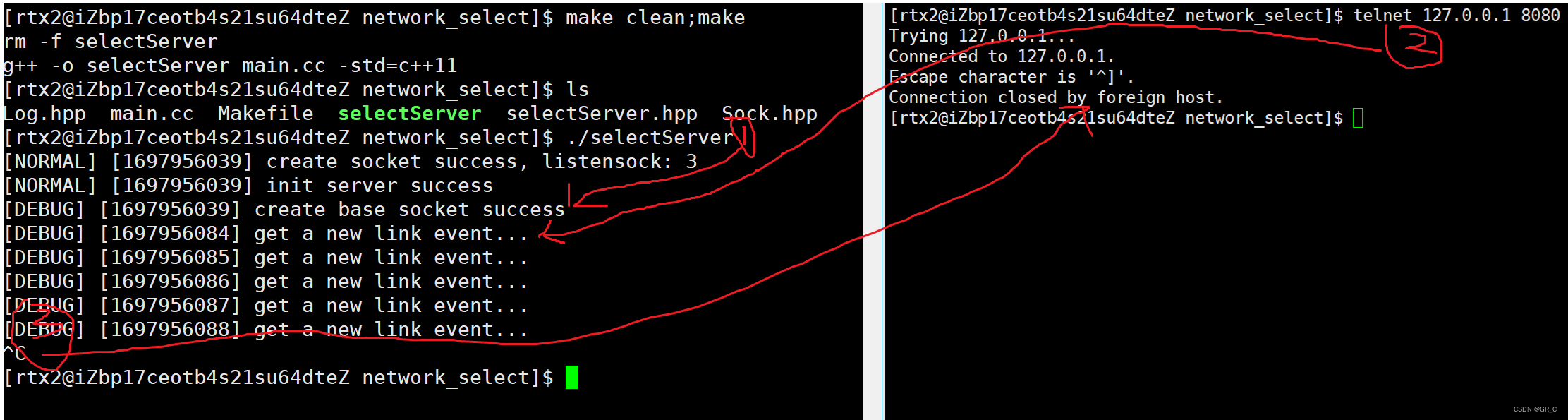
链接后没有处理事件,select会一直通知你,所以每隔1秒打印了一次信息。
下面写一大部分的HandlerEvent,直接放selectServer.hpp代码了,后面再写个Recver。
跟着代码和注释一起看:
selectServer.hpp
(加上下面的Recver函数,再放开注释就是最终的selectServer.hpp了)
#ifndef __SELECT_SVR_H__
#define __SELECT_SVR_H__
#include <iostream>
#include <sys/select.h>
#include "Log.hpp"
#include "Sock.hpp"
#define BITS 8
#define NUM (sizeof(fd_set) * BITS)
#define FD_NONE -1
using namespace std;
// select 这里只完成读取,写入和异常不做处理 -- epoll(写完整)
class SelectServer
{
public:
SelectServer(const uint16_t &port = 8080)
: _port(port)
{
_listensock = Sock::Socket();
Sock::Bind(_listensock, _port);
Sock::Listen(_listensock);
logMessage(DEBUG, "%s", "create base socket success");
for(int i = 0; i < NUM; i++)
{
_fd_array[i] = FD_NONE;
}
_fd_array[0] = _listensock; // 规定 : _fd_array[0] = _listensock;
}
void Start()
{
while (true)
{
// // 测试select的第五个参数
// fd_set rfds;
// FD_ZERO(&rfds);
// struct timeval timeout = {0, 0}; // 输入输出型,后面会变成0,
// // 如何看待listensock -> 获取新连接,我们把它依旧看做成为IO,input事件,如果没有连接到来呢 -> 阻塞
// // int sock = Sock::Accept(listensock, ...); //不能直接调用accept了
// FD_SET(_listensock, &rfds); // 将listensock添加到读文件描述符集中
// int n = select(_listensock + 1, &rfds, nullptr, nullptr, nullptr);
// 1. nfds: 随着获取的sock越来越多,添加到select的sock越来越多,注定了nfds每一次都可能要变化,所以需要对它动态计算
// 2. rfds/writefds/exceptfds:都是输入输出型参数,输入输出不一定是一样的,所以我们每一次都要对rfds进行重新添加
// 上两点 -> 必须自己将合法的文件描述符需要单独全部保存起来 用来支持:1.更新最大fd 2.更新位图结构 -> 所以定义数组
DebugPrint();
fd_set rfds;
FD_ZERO(&rfds); // 每次都清零
int maxfd = _listensock;
for (int i = 0; i < NUM; i++) // 1.更新最大fd 2.更新位图结构
{
if (_fd_array[i] == FD_NONE)
continue;
FD_SET(_fd_array[i], &rfds);
if (maxfd < _fd_array[i])
maxfd = _fd_array[i];
}
// rfds未来,一定会有两类sock,listensock,普通sock,select中,而且就绪的fd会越来越多
int n = select(maxfd + 1, &rfds, nullptr, nullptr, nullptr);
switch (n)
{
case 0:
// printf("hello select ...\n");
logMessage(DEBUG, "%s", "time out...");
break;
case -1:
logMessage(WARNING, "select error: %d : %s", errno, strerror(errno));
break;
default:
// 成功的
logMessage(DEBUG, "get a new link event...");
HandlerEvent(rfds);
break;
}
}
}
~SelectServer()
{
if (_listensock >= 0)
close(_listensock);
}
private:
void HandlerEvent(const fd_set &rfds) // fd_set 是一个集合,里面可能会存在多个sock
{
for (int i = 0; i < NUM; i++)
{
if (_fd_array[i] == FD_NONE) // 1. 去掉不合法的fd
continue;
// 2. 合法的fd不一定就绪了
if (FD_ISSET(_fd_array[i], &rfds)) // 如果fd就绪
{
if (_fd_array[i] == _listensock) // 读事件就绪:连接事件到来,accept
{
Accepter();
}
else // 读事件就绪:INPUT事件到来,read / recv
{
// Recver(i); // 这个函数后面写
logMessage(DEBUG, "message in, get IO event: %d", _fd_array[i]);
sleep(1);
}
}
}
}
void Accepter()
{
string clientip;
uint16_t clientport = 0;
// listensock上面的读事件就绪了,表示可以读取了,获取新连接了
int sock = Sock::Accept(_listensock, &clientip, &clientport); // 这里进行accept不会阻塞
if (sock < 0)
{
logMessage(WARNING, "accept error");
return;
}
logMessage(DEBUG, "get a new line success : [%s:%d] : %d", clientip.c_str(), clientport, sock);
// 不能read / recv ,因为我们不清楚该sock上面数据什么时候到来, recv、read就有可能先被阻塞,IO = 等+数据拷贝
// 谁可能最清楚该sock上面数据什么时候到来 -> select
// 得到新连接的时候,应该考虑的是,将新的sock托管给select,让select帮我们进行检测sock上是否有新的数据
// 有了数据select,读事件就绪,select就会通知我,我们再进行读取,此时就不会被阻塞了
// 要将sock添加 给 select,只要将fd放入到数组中即可
int pos = 1; // 规定了 _fd_array[0] = _listensock; 不用管
for(;pos < NUM; pos++) // 将fd放入到数组中 -> 找一个合法的位置
{
if (_fd_array[pos] == FD_NONE)
break;
}
if (pos == NUM) // 满了不能加了
{
logMessage(WARNING, "%s:%d", "select server already full, close: %d", sock);
close(sock);
}
else // 找到了合法的位置
{
_fd_array[pos] = sock;
}
}
void DebugPrint() // 打印一下数组里合法的fd
{
cout << "_fd_array[]: ";
for (int i = 0; i < NUM; i++)
{
if (_fd_array[i] != FD_NONE)
cout << _fd_array[i] << " ";
}
cout << endl;
}
private:
uint16_t _port;
int _listensock;
int _fd_array[NUM]; // 可以用vector,但现在看看select的缺点
// int _fd_write[NUM]; 这里就不写了
};
#endif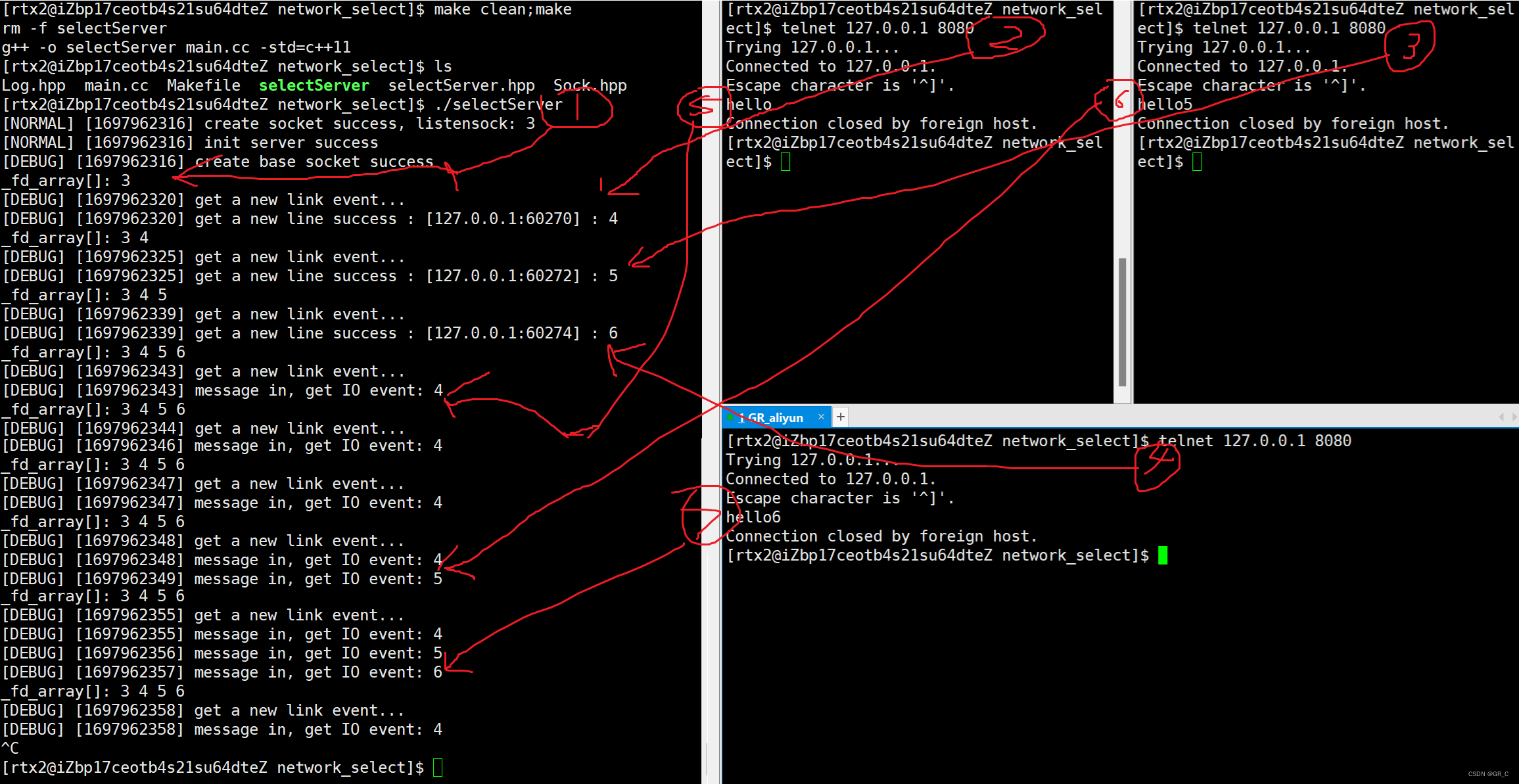
此时就成功获取了读事件和IO事件,下面写Recver处理IO事件:
void Recver(int pos)
{
// 读事件就绪:INPUT事件到来、recv,read
logMessage(DEBUG, "message in, get IO event: %d", _fd_array[pos]);
// 此时select已经帮我们进行了事件检测,fd上的数据一定是就绪的,即 本次 不会被阻塞
// 怎么保证以读到了一个完整的报文呢? -> 模拟实现epoll的时候再考虑
char buffer[1024];
int n = recv(_fd_array[pos], buffer, sizeof(buffer)-1, 0);
if(n > 0) // 正常读取
{
buffer[n] = 0;
logMessage(DEBUG, "client[%d]# %s", _fd_array[pos], buffer);
}
else if(n == 0) // 对端把链接关了
{
logMessage(DEBUG, "client[%d] quit, me too...", _fd_array[pos]);
close(_fd_array[pos]); // 关闭不需要的fd
_fd_array[pos] = FD_NONE; // 不要让select帮我关心当前的fd了
}
else // 读取错误
{
logMessage(WARNING, "%d sock recv error, %d : %s", _fd_array[pos], errno, strerror(errno));
close(_fd_array[pos]); // 关闭不需要的fd
_fd_array[pos] = FD_NONE; // 不要让select帮我关心当前的fd了
}
}再把上面调用的Recver放开就是最终代码了,编译运行:

服务器上只有一个进程(线程),客户端有多个,此时服务端可以同时接收多个客户端的连接请求和数据。多路转接实现了我们之前只能通过多进程或者多线程才能实现的功能,而且效率非常高。
2.3 select的优缺点
优点就像上面说的效率高,还有应用场景是:有大量的链接,只有少量是活跃的,省资源。select的优点也是所有多路转接都具备的优点。
看看缺点:
①select能同时等待的文件fd是有上限的,除非重新修改内核,否则无法解决。 fd_set位图大小只有1024个比特位,意味着select同时最多只能等待1024个文件描述符。
②必须借助第三方数组等结构来维护需要select等待的文件描述符fd。 由于select的后四个参数都是输入输出型参数,操作系统也会修改这几个参数,这就导致用户层必须自己维护一个数组来记录自己曾经想要让select等待的文件描述符。 并且每轮询一次就需要重新设置一次fd_set位图,不仅繁琐,而且对于效率相对较低。
③select存在遍历成本。 在上面实现的服务器代码中,对于用户层来说,存在多处遍历所维护的数组。 在将文件描述符设置到fd_set位图中的时候,需要遍历数组中的所有元素来找到合法的fd设置到位图中。 在select完成等待后,同样需要遍历一次数组,来确定是哪个fd的事件就绪了,然后再去处理。内核也要进行遍历。select的第一个参数传参时传入的是最大文件描述符fd + 1,这个参数就是为了让内核确定遍历的范围,这个值之前的所有文件描述符,操作系统都会进行查看,看看是否有事件就绪。
④内核和用户层来回拷贝的成本问题。select采用的是位图来标记哪个文件的事件就绪,无论是用户层告诉内核,还是内核告诉用户层,都需要拷贝,这样来回进行数据拷贝也是有很大的成本。
⑤编码比较复杂,这是上面的缺点导致的,我们的简易select服务器还没加读和写就挺复杂的了。
3. 相关笔试选择题
1. 以下关于非阻塞IO说法不正确的是()
A.非阻塞调用是指发生调用之后,当不能得到结果时,直接返回
B.非阻塞IO需要搭配循环来使用
C.当非阻塞IO模型时,用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果
D.在使用非阻塞IO的时候CPU使用率一定很高
2.?以下关于信号驱动IO说法不正确的是()
A.信号驱动IO是指内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作
B.信号驱动IO需要注册一个信号处理函数
C.当使用信号驱动IO的时候,线程可以做其他事情,并不需要一直去关注数据是否已经准备好
D.当使用信号驱动IO的时候,调用者需要配合循环来时不时的关注是否可以进行IO操作
3.?以下关于IO复用说法不正确的是()
A.IO多路转接能够同时等待多个文件描述符的就绪状态
B.在所有的POSIX兼容的平台上,select函数使我们可以执行IO多路转接
C.select的参数会告诉内核我们所关心的描述符
D.以上说法都不正确
4.?以下关于异步IO说法不正确的是()
A.System V的异步IO信号是SIGPOLL
B.POSIX异步IO接口使用AIO控制块来描述IO操作
C.当使用异步IO的时候,由内核在数据拷贝完成时, 通知应用程序
D.当使用异步IO的时候,由内核告诉应用程序何时可以开始拷贝数据
5.?以下是关于阻塞IO说法不正确的是()
A.典型的阻塞IO的例子为:data = socket.read();
B.用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态
C.当调用socket.read()后,如果内核数据没有就绪,当前调用者的进程中所有线程都会阻塞
D.阻塞调用是指调用结果返回之前,当前线程会被挂起
答案及解析
1. D
非阻塞指的是如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK错误码,但是这时候并没有获取到数据,因此也就意味着,非阻塞的调用需要搭配循环来使用。
换个实际的场景,也就是意味着,当用户发起一个read操作之后,如果内核没有准备好数据,则read返回,返回-1,并重置errno为EWOULDBLOCK 表示数据未就绪
但是非阻塞IO虽然需要配合循环来使用,但是并不一定CPU使用率就很高,CPU使用率很高,意味着CPU在做大量的运算(逻辑运算或者算术运算),所以不一定CPU使用率会高,因为返回后不一定会立即进行没有就绪的IO操作。
2. D
D错误:当时用信号驱动IO的时候,由于是注册了信号处理函数,当内核将数据准备好,通过SIGIO来通知用户进程,进程这时候再进行IO操作,所以不需要配合循环来关注IO操作。
3. D
IO复用也是指的是IO多路转接,可以同时监听多个文件描述符的状态,多路转接模型有:select,poll,epoll,其中select遵循posix标准,因此POSIX平台可以使用select
int select(int nfds, fd_set *readfds, fd_set *writefds,?fd_set *exceptfds, struct timeval *timeout);
可以通过setect函数的readfds,writefds,告诉系统需要监控的描述符以及对应的监控状态
所以ABC都是正确的描述。
4. D
A正确:与SIGIO同义,表示文件描述符准备就绪, 可以开始进行输入/输出操作
B正确:POSIX中定义了异步 IO 应用程序接口(AIO API)
C正确:内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据),也就是说信号驱动是告诉进程什么时候可以进行IO, 而异步IO是告诉进程什么时候IO完成了。
D错误。
5. C
C错误:如果在内核数据没有就绪的时候进行read调用,则只会阻塞调用线程这一个执行流,并不会阻塞所有线程。
本篇完。
多路转接是一个非常重要的IO模式,而select方式只最基础的一种,它主要的作用是带领我们理解多路转接,后面还会学习poll和epoll多路转接方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Windows10开启本地代理设置
- 24款奔驰GLE450升级小柏林音响 中规高配主机 实现导航地图
- 了解什么是UV纹理?
- 蒙特卡洛方法:Python实现
- MySQL进阶篇:索引(概述,结构,分类,语法,SQL性能分析,索引使用,设计原则)
- 鸿蒙OS:不止手机,是物联网应用开发
- R语言【cli】——ansi_nchar():计数ANSI彩色字符串中的字符数
- 【教程】cocos2dx资源加密混淆方案详解
- R语言【base】——cat() 输出对象,连接表示法,其运行的转换比 print 少得多
- Verilog语法——3.模块设计实战