2023.12.28 关于 Redis 数据类型 List 内部编码、应用场景
发布时间:2023年12月30日
目录
List 编码方式
早期版本
- 早期版本 List 类型的内部编码方式有两种
- ziplist(压缩列表)
- linkedlist(链表)
- 两个配置项
- list-max-ziplist-entries 配置
- list-max-ziplist-value 配置
注意:
- 现版本?Redis 已不再使用这两个配置项
- 且上述的 两种编码方式 为早期版本 Reids 中的 List 类型内部编码方式
现今版本
- 现今版本 Redis 使用 quicklist 作为 List 类型的内部编码方式
- quicklist 相当于?ziplist 和 linkedlist 的结合
- quicklist 整体上还是一个 linkedlist ,但 linkedlist 的每个节点均为一个 ziplist
特点:
- 每个节点上的 ziplist 不会太大,且这多个 ziplist 通过链式结构链接起来
配置项:
- 该配置项描述了每个节点 ziplist 的阈值
- 当 ziplist 满足阈值,便将其分裂成多个列表节点,即多个 ziplist?
- 再将这多个 ziplist 通过链式结构链接起来
注意:
- 观察上图注释信息,ziplist 的阈值为可选项
- 所以我们还需针对当前业务场景,来选择合适的阈值!
实例理解
- 我们通过?object encoding key?来查看编码方式



List 实际应用
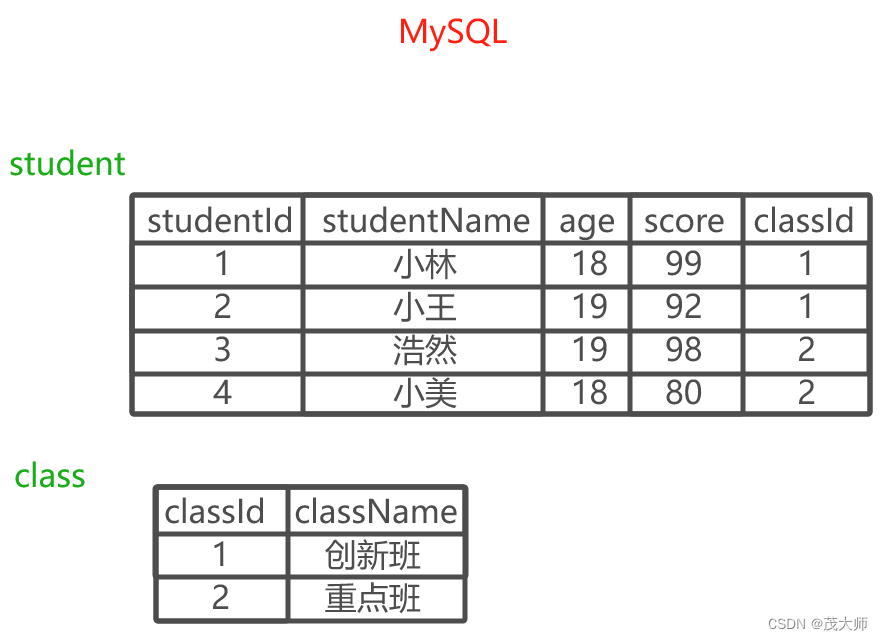
多表之间的关联关系
- 可将?list 作为 数组 这样的结构来存储多个元素
实例理解
- 使用 MySQL 表示学生和班级信息
- 上图?MySQL 表结构 可以很方便的实现 查询指定班级中有哪些同学
- Redis 所提供的查询功能 是不如 MySQL 的
- 所以我们可以通过往 Redis 中插入 List 类型键值对直接将 学生 和 班级信息 进行关联
- 结合上图实例,Redis 通过 List 类型 便可以将 学生 和 班级信息 关联起来
- 从而能很轻易的实现?查询指定班级中有哪些同学
注意:
- 此处除了使用 Hash 类型表示学生信息,也可使用 String + JSON 的方式来表示学生信息
- 即 具体 Redis 中的数据是如何组织的,都需根据实际的业务情况来决定
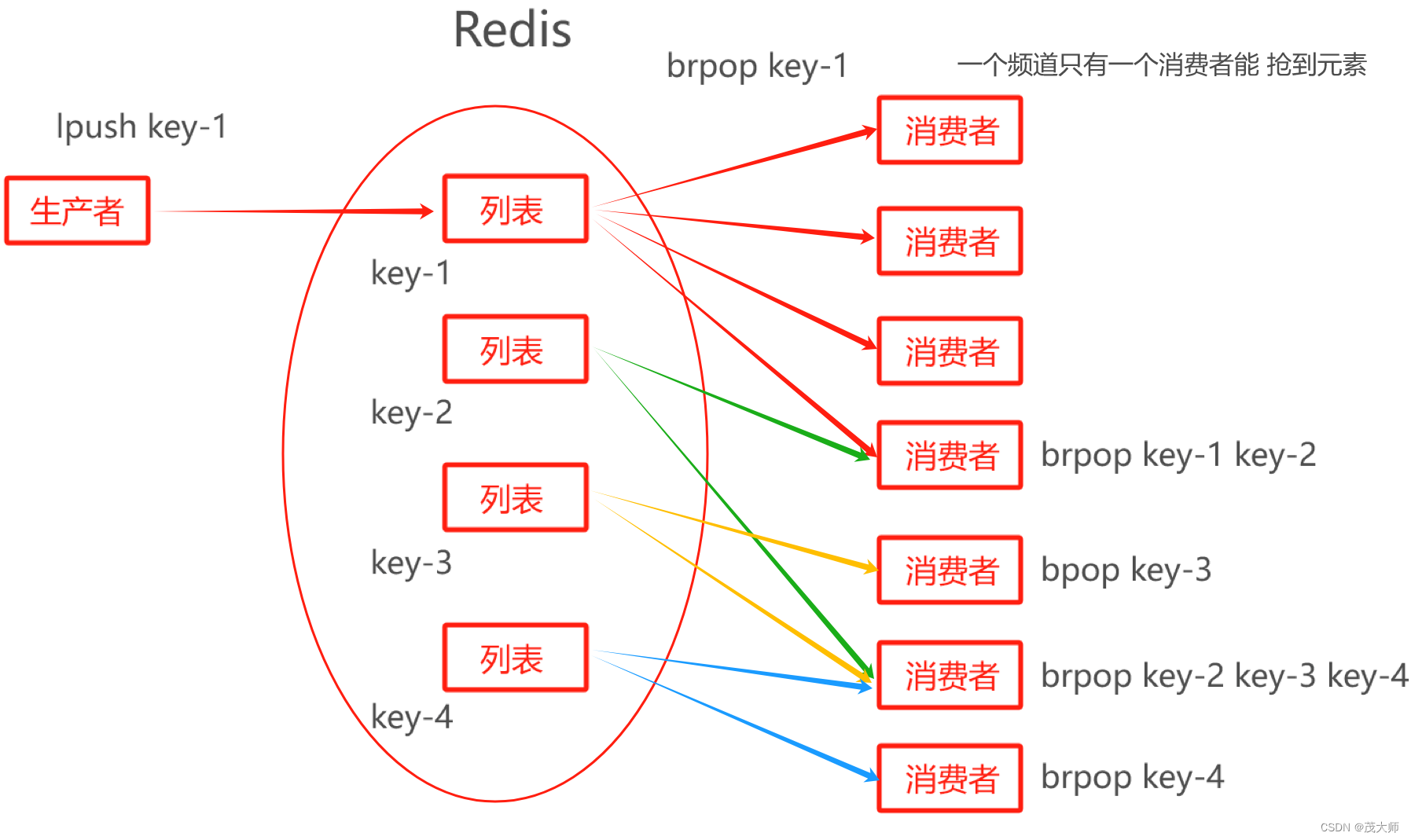
消息队列
- 生产者消费者模型
- 上图的 brpop 为阻塞操作
- 当列表为空时,brpop 命令便会阻塞等待,一直等到其他客户端向列表中 lpush 元素为止
重点理解:
- 此处?只有一个消费者能抢到元素
通俗理解:
- 谁先执行的?brpop 命令,谁就能拿到这个新 lpush 的元素
- 该设定便能很好的构成?"轮询"?效果
实例理解
- 假设此时列表为空,三个消费者(A、B、C)按顺序执行 brpop 命令进行阻塞等待
- 即执行顺序为 消费者A ——>?消费者B ——> 消费者C
- 当有新元素到达列表时,该新元素将被 消费者A 获取,且 brpop 命令立即返回,标志着 消费者A?完成了一次消费操作
- 若消费者A 想要继续消费,必须再次执行 brpop 命令
- 此时执行顺序变为?消费者B?——> 消费者C?——> 消费者A
- 如果再有新元素到达,消费者B 将获取该元素,且 brpop 命令立即返回,标志着 消费者 B 完成了一次消费操作
总结:
- 上述实例所描述的这种轮询方式,即消费者们按照固定的顺序交替执行 brpop 命令
- 很好的实现了对阻塞队列的有序消费
频道(多列表)消息队列
- 多列表/频道 这种场景是比较常见的
实例理解
- 日常使用的程序,比如抖音
- 一个频道 用来传输短视频数据
- 一个频道 用来传输弹幕
- 还可以有多个频道,用来传输点赞、转发、收藏、评论数据
优点:
- 多频道模式 一定程度上保证了在某种数据发生问题的时候,不会对其他数据造成影响
- 具有一定的 解耦合 作用
微博 Timeline
- 每个用户都拥有属于自己的 Timeline(微博列表),现需要分页展示文章列表
- 此时便可以考虑使用列表,因为列表不但是有序的,且支持按照索引范围获取元素
实例理解
- 每篇微博使用 哈希结构存储
- 此处包含三个属性(title、timestamp、content)
hmset mblog:1 title xx timestamp 1476536196 content xxxxx ... hmset mblog:n title xx timestamp 1476536196 content xxxxx
- 向用户 Timeline 添加微博,使用 List 类型
- 此处使用 user:<uid>:mblogs 作为微博的键
lpush user:1:mblogs mblog:2 mblog:4 ... lpush user:k:mblogs mblog:n
- 分页获取用户的 Timeline
- 此处假设获取用户1 的前 5 篇微博
keylist = lrange user:1:mblogs 0 4 for key in keylist { hgetall key }问题一:
- 当前一页中有多少数据是不确定,所以有可能会导致 for 循环比较大
- 从而会触发多次 hgetall 命令,即多次?网络请求
解决方法:
- 使用 pipeline(流水线、管道)
- 虽然此处是多个 Redis 命令,但是通过 pipeline 我们可以将这些命令合并成一个 网络请求 进行通信
- 由此可以大大降低 客户端 和 服务器 之间的交互次数
问题二:
- lrange 在列表两端表现较好,获取列表中间的元素表现较差
解决方案:
- 将文章对应的 list 进行切分
- 假设某用户发布了?1w 篇微博,则 list 的长度为?1w
- 如果将这 1w 篇微博拆分成 10 份,即 每份1k 篇微博
- 此时如果想获取第 5k 篇左右的微博
- 即直接找到第五个列表,进行遍历即可
- 通过这样的拆分方式便能降低单个 list 的长度,并加快中间位置元素的查询速度
栈 & 队列
- 同侧存取(lpush+lpop 或 rpush+rpop)为栈
- 异侧存取(lpush+rpop 或 rpush+lpop)为队列


文章来源:https://blog.csdn.net/weixin_63888301/article/details/135280192
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!