【吴恩达·机器学习】第一章:机器学习绪论:监督学习和非监督学习
文章目录

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @是瑶瑶子啦
- 每日一言🌼: 勇敢的人,不是不落泪的人,而是愿意含着泪继续奔跑的人。
——《朗读者》
0、声明
本系列博客文章是博主本人根据吴恩达老师2022年的机器学习课程所学而写,主要包括老师的核心讲义和自己的理解。在上完课后对课程内容进行回顾和整合,从而加深自己对知识的理解,也方便自己以及后续的同学们复习和回顾。
- 课程地址👉🏻2022吴恩达机器学习Deeplearning.ai课程
- 课程资料和代码(jupyter notebook)👉🏻2022-Machine-Learning-Specialization
由于课程使用英文授课,所以博客中的表达也会用到英文,会用到中文辅助理解。
🌸Machine learning specialization课程共分为三部分
- 第一部分:Supervised Machine Learning: Regression and Classification
- 第二部分:Advanced Learning Algorithms(deep learning)
- 第三部分:Unsupervised Learning: Recommenders, Reinforcement Learning
💐最后,感谢吴恩达老师Andrew Ng的无私奉献,和视频搬运同学以及课程资料整合同学的无私付出。Cheers!🍻
1、前言:Part1/Week1学习总结
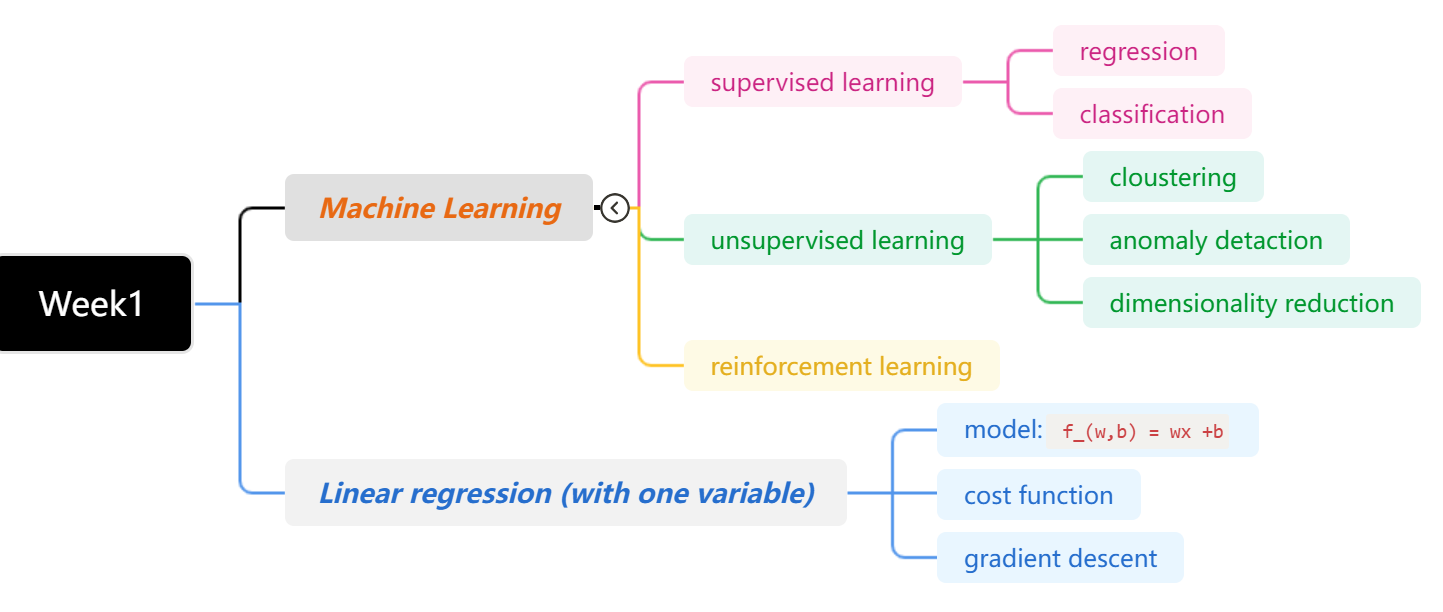
第一周首先是对机器学习进行了介绍(应用以及定义),机器学习主要分为监督学习和非监督学习(还有强化学习)。监督学习中又可分为回归问题和分类问题。无监督学习分为聚类问题、异常检测、降维。
随后,就单变量的线性回归问题进行的深入的讲解。从回归模型的构建开始(线性模型),到代价函数再到梯度下降算法,进行了生动的讲解。
2、机器学习绪论
2.1:什么是机器学习
一言蔽之: Machien can learn without explicit programing.
我的理解就是:在机器做出判断or预测的时候,它做的每一步,并不是一开始人为的编程好了的(你可以理解为,它做出这个预测,内部是运行了哪及行代码,变量的值是多少或者说权重是多少,并不是程序员一开始编程好的,写死的),而是通过喂数据,由机器自己通过奇迹学习的算法(像后面提到的梯度下降的算法)自己学习得到的。
这里吴恩达老师举了个例子,说跳棋机器人程序设计者自己的跳棋能力可能不怎么样,但是通过自己和机器人大量的比赛,机器获取了大量的数据,最后机器人的跳棋能力已经远超于程序编写者的跳。能力,这种能力是就是通过大量数据以及机器学习算法,机器自己学习得到的,这就是机器学习。
2.2:监督学习
首先在直接给出提监督学习、回归问题、分类问题这些术语名词定义之前,我们先有一个宏观上的,直觉上的感受。
首先机器学习很大的一个应用,我们所能感受到的,就是做预测,对,预测,这个词我们很熟悉,其实回归和分类本质上就是预测,监督学习只是机器学习到这种预测能力的一种学习方式(即我们怎么喂数据的一种方式)。所以是不是也没有那么害怕继续看下去了?🤔
那怎么用数学的方式表示这种预测呢?给出房子的大小,预测出房价。这是不是很像数学里面的 “映射”——mapping.通常表现为下面这种形式:给定输入X,得到预测结果Y
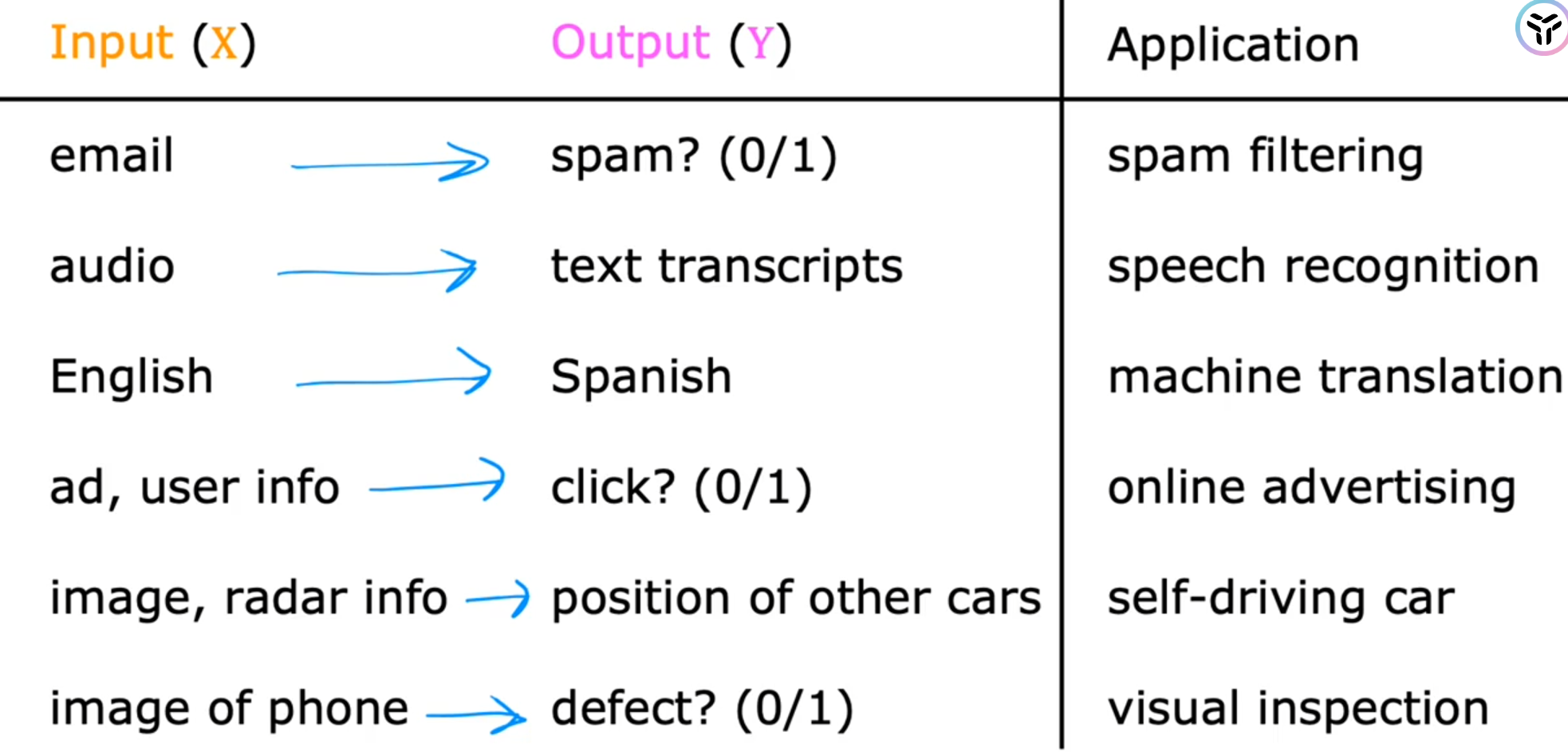
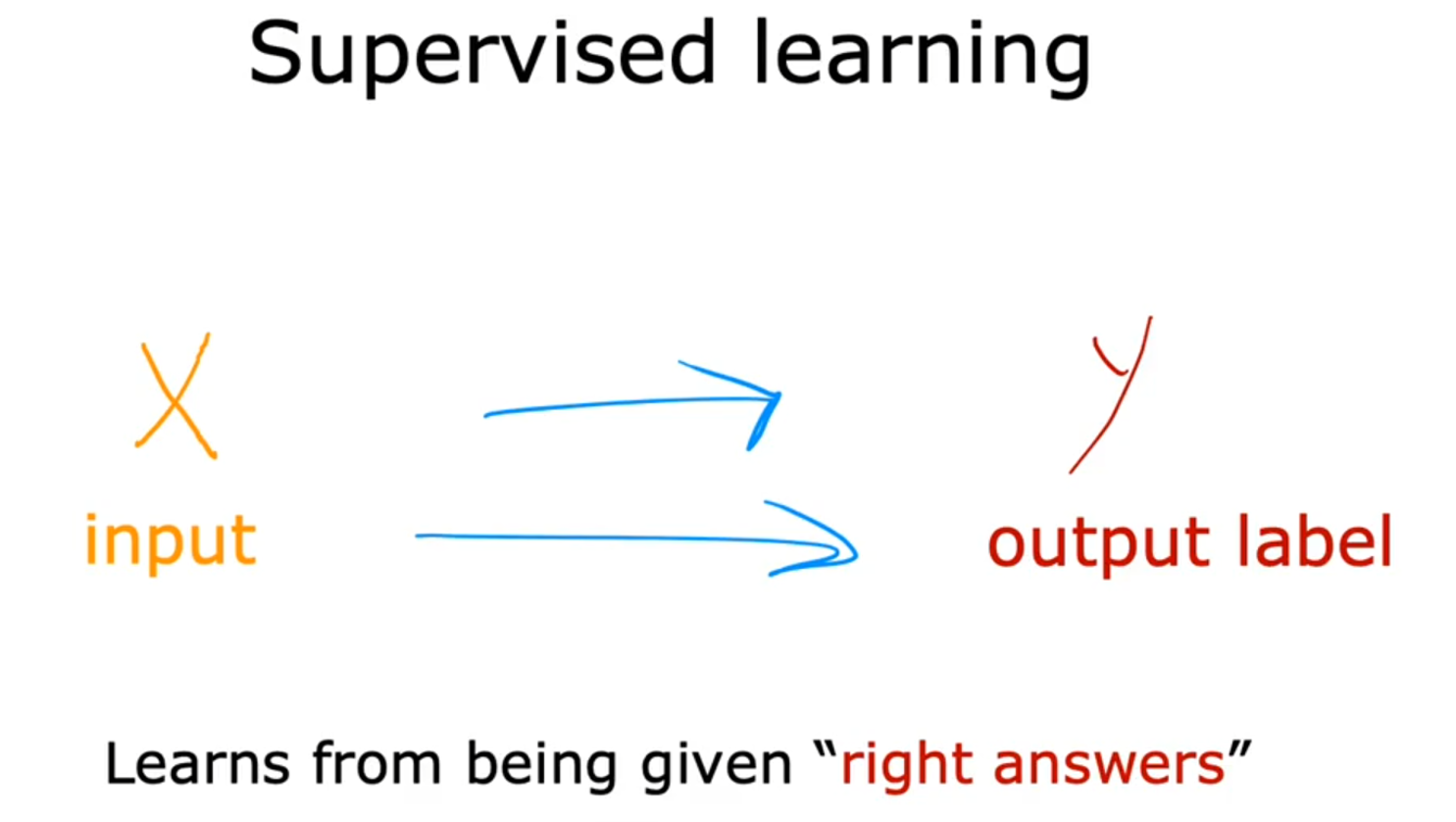
而监督学习就是机器自己学习从而得到这种映射关系的方法(即需要同时给定输入和预测的正确结果,这在后面具体讲到监督学习中的回归模型时会具体感受到)
Learns from being given “right answers”.
监督学习主要分为下面两种模型,或称为两种问题:
- 回归:regression
- 分类:classification
下面进行简要的概述
2.2.1:回归
🌸Regression:Predict a number infinitly many outputs
下面是以房价预测的案例:给定房子的大小(House size),预测得到具体的房价(Housing price).
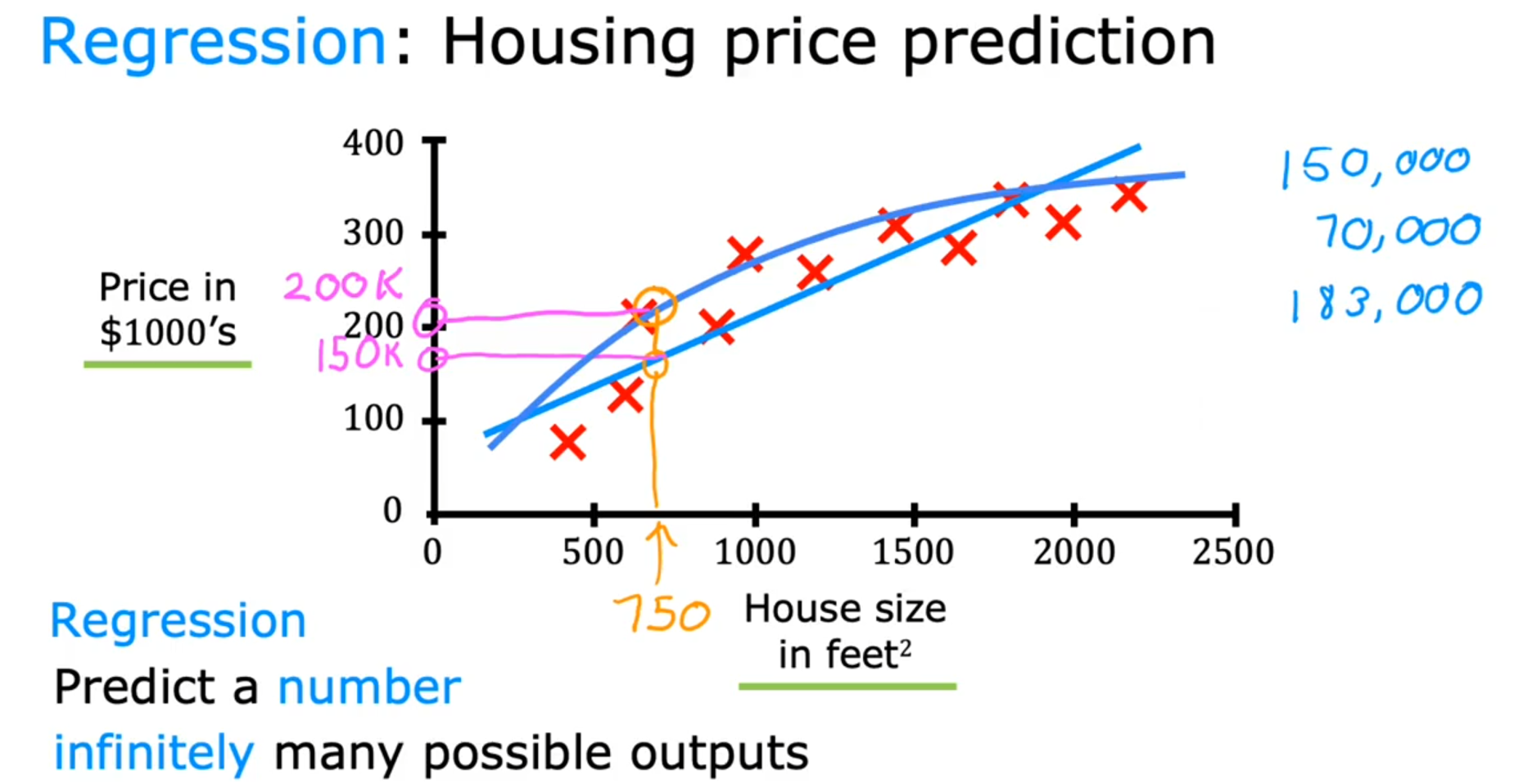
🪧Tips:
- 上面例子是单变量的回归问题,当然也可以是多变量(即输入不止房价,还可以有地理位置等
- 蓝色的曲线和直线是预测函数,也是上文说到的映射
mapping.直线表示是线性回归,曲线则是非线性(🙎🏻?♀?非线性会比线性复杂,拟合效果好,但是其实曲线也是由直线得到。为什么不直接分析非线性呢?因为线性最简单,人们本身最擅长分析线性问题,就像模电中为什么要在三极管问题中将其转换为等效小信号模型,本质上也是因为人类最擅长分析线性模型——一点自己的理解)
2.2.2:分类
🌸Classification:Predict categories with a small number of possible outputs
下面是根据肿瘤的直径大小来预测癌症的类别(预测结果是有限的)
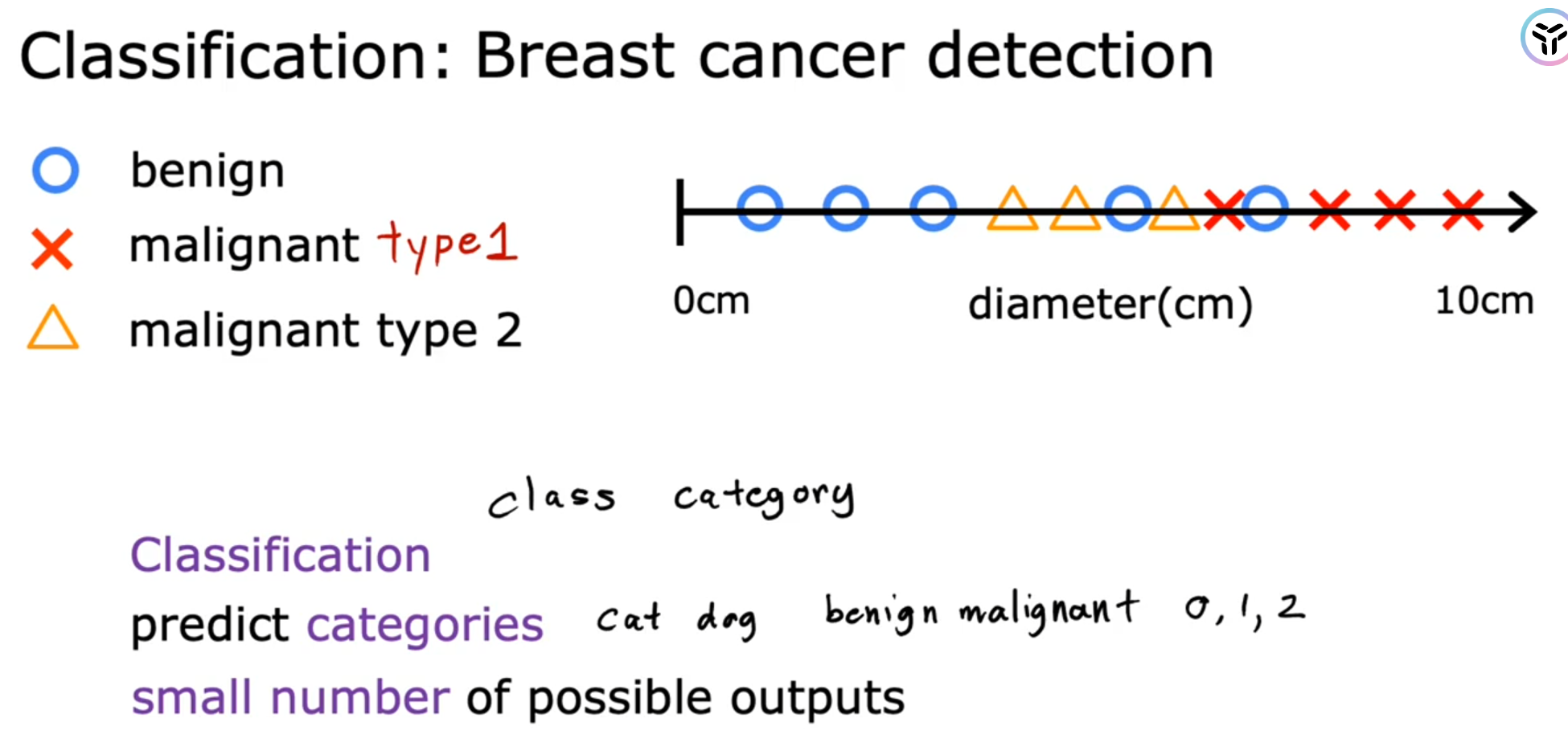
🪧Tips:
-
首先同回归问题一样,上面例子还是输入是单变量的,当然输入也可与是多变量,就像下面这样:
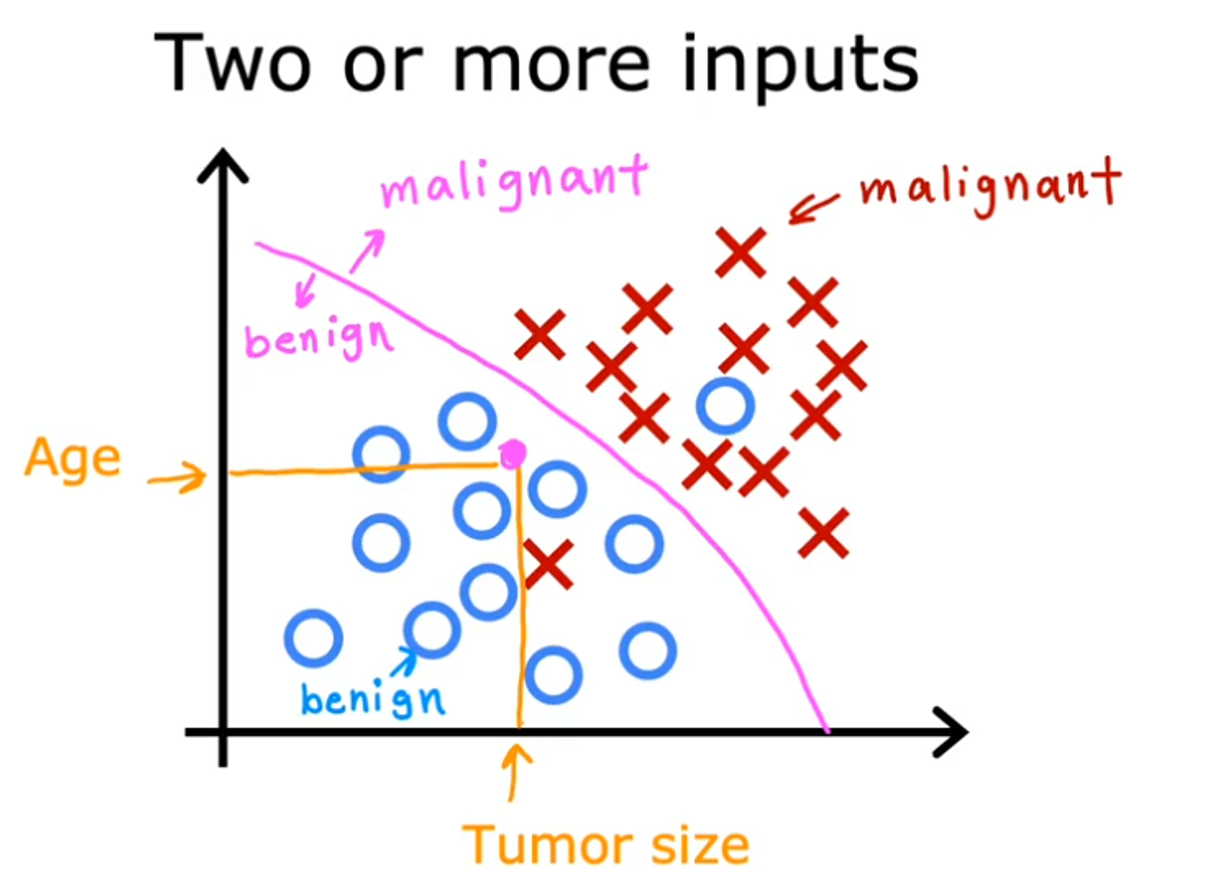
-
和回归问题不同的是,分类问题的结果是离散的,且结果是有限的。
2.2.3:回归和分类对比:
最大的区别是
- 回归的结果是连续的,没有确定范围的
- 分类问题是离散的,有限的

2.3:非监督学习
非监督学习和监督学习的区别在于,在得到预测的映射函数时,不再同时给定输入和对应的正确输出,而是只给输入,让机器自己去找输入数据的内部关系和结构从而做出预测.(可以通过下文的例子很好理解)。
🪧Unsupervised learning: Data only comes with input x, but not outputs labels y. Algorithm has to find structure in the data.
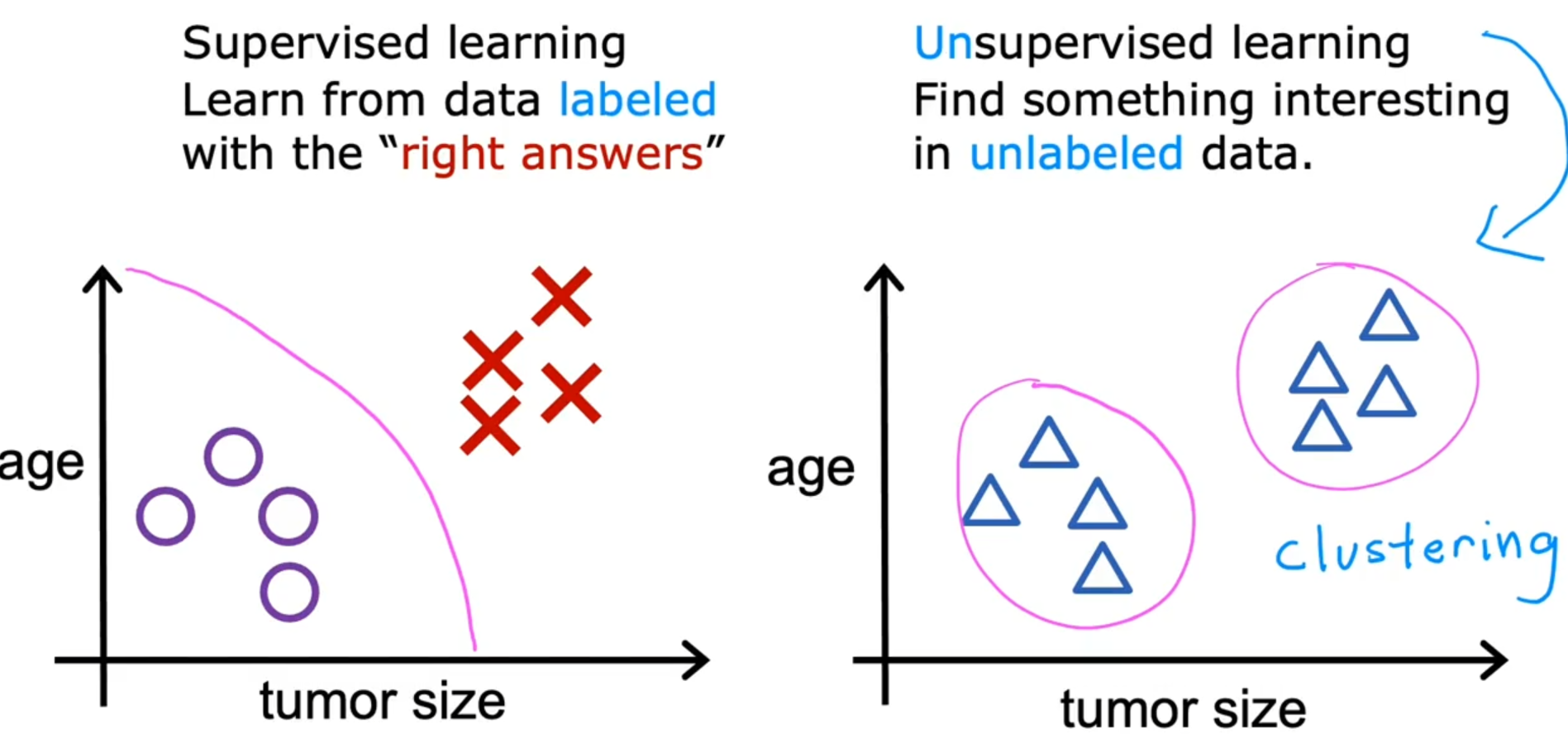
非监督学习下最主要的最常见的一种就是:聚类(Cloustering)
2.3.1: 聚类
下面这是我们在搜索时经常遇到的场景。这是瑶瑶子关于傅里叶变换的一篇博客,当阅读完之后,会发现下方有很多与傅里叶相关的博客展示。这背后运用的就是聚类算法。
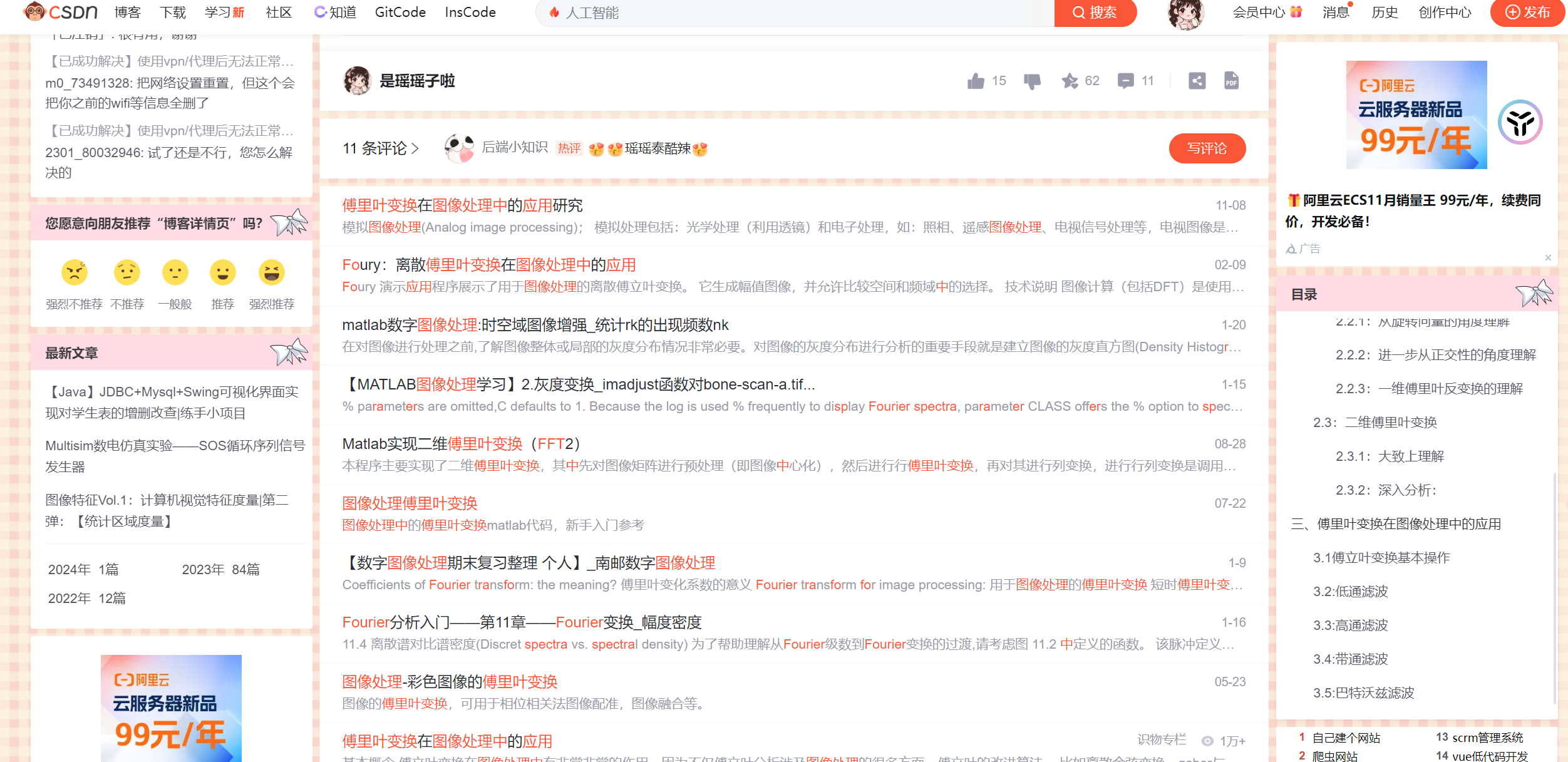
它似乎也是将类似的文章分为一类进行展示,但不同于分类问题的是,它没有具体的类别。我们知道分类问题的预测结果类别是离散的有限的。而这个显然不是,不同的文章下就会有对应的显示,计算机内部也没有事先记录好类别,而是通过聚类算法,自动将类似的文章聚类。这种机器自动发现数据间的结构,从而进行自己聚类的算法即为聚类算法。🪧Clousterinng: group similar data points together
其他非监督学习下的问题:还有缺陷检测和降维

🦄下期预告:单变量的线性回归模型,从数据集到线性模型,再到代价函数和梯度下降。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL事务与MVCC详解
- 4.14 构建onnx结构模型-Min
- 遇到 Out of Memory 怎么办?DolphinDB OOM 应对指南请查收!
- 一文看懂公募私募基金对比了解!到底该如何选?
- 08 通信协议之UART
- mysql 导入数据 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘
- java-方法:函数、过程
- python爬虫如何用代理IP提高效率?
- C/C++ string.h库中的memcpy()和memmove()
- 零售收银软件源码支持二开-副屏广告及赋能