Oracle定时任务的创建与禁用/删除
在开始操作之前,先从三W开始,即我常说的what 是什么;why 为什么使用;how?如何使用。
一、Oracle定时器是什么
Oracle定时器是一种用于在特定时间执行任务或存储过程的工具,可以根据需求设置不同的时间段和频率来执行相应的操作。
二、为什么使用Oracle定时器
使用Oracle定时器的好处在于可以自动化执行重复性的任务,比如每天、每周或每月执行一次数据库维护、数据备份等操作,从而减轻了人工操作的负担,提高了工作效率。
三、如何使用Oracle定时器
使用Oracle定时器的方法包括编写存储过程来定义需要执行的任务,然后创建一个定时器Job来调度这个存储过程。可以根据具体需求设置定时器的执行时间、频率和其他参数,以实现自动化执行任务的目的。
四、目前有哪些主流Oracle定时器?有何区别?
目前主流的Oracle定时器有两种:DBMS_SCHEDULER和DBMS_JOB。它们之间有以下区别:
1. DBMS_SCHEDULER:DBMS_SCHEDULER是Oracle 10g及以上版本引入的定时器。它提供了更强大和灵活的功能,可以创建和管理复杂的作业调度。DBMS_SCHEDULER使用了面向对象的方式来定义作业和调度器,并且支持多种类型的作业,如PL/SQL块、存储过程、外部脚本等。它还支持更多的调度选项,如基于时间、日期、事件等触发器,以及更灵活的重复调度设置。
2. DBMS_JOB:DBMS_JOB是Oracle 9i及以下版本中使用的定时器。它相对简单,只能调度PL/SQL块作业。DBMS_JOB使用了过程式的方式来定义作业和调度器,调度选项相对较少,只能基于时间间隔来触发作业。此外,DBMS_JOB的调度信息存储在数据库中的JOB表中。
总的来说,DBMS_SCHEDULER比DBMS_JOB更强大和灵活,适用于复杂的作业调度需求。而DBMS_JOB则更简单,适用于简单的定时任务。
介绍了概念,接下来是实际使用,参考自蒋老师的文章,感谢蒋老师的分享和归纳——
oracle 定时任务 (yuque.com)![]() https://www.yuque.com/ernanbei/fh8sgs/fn20rxtaosmfdfnq?singleDoc#最常见的定时场景就是周期性统计动态变化的数据,以我为例,我需要在项目中加入一个Oracel定时器,每三分钟统计一次数据,那首先得写一个函数用于操作数据的读取和存储,其次是设置定时器,通过定时器定时周期性调度执行该函数,从而实现数据的周期性的获取。
https://www.yuque.com/ernanbei/fh8sgs/fn20rxtaosmfdfnq?singleDoc#最常见的定时场景就是周期性统计动态变化的数据,以我为例,我需要在项目中加入一个Oracel定时器,每三分钟统计一次数据,那首先得写一个函数用于操作数据的读取和存储,其次是设置定时器,通过定时器定时周期性调度执行该函数,从而实现数据的周期性的获取。
1、函数的编写
create PROCEDURE SYNCHRONIZE_HONORING_HISTORY
AS
V_ERR_MSG NVARCHAR2(1000);
V_COUNT_1 NUMBER(1);
V_COUNT_2 NUMBER(5) :=0;
--查询当天的数据
cursor c_job is select APPLY_RECORD_ID,
COMMENDATION_ID,
COMMENDATION_NAME,
USER_NAMES,
UPDATE_DATE,
COMMENDATION_SOURCE,
COMMENDATION_SOURCE_NAME,
COMPETENCE_DIMENSION,
COMPETENCE_DIMENSION_NAME,
SUM_SCORE,
BASE_DEPT_ID
from (select APPLY_RECORD_ID,
COMMENDATION_ID,
COMMENDATION_NAME,
substr(USER_NAME, 0, instr(USER_NAME, ',', -1) - 1) USER_NAMES,
UPDATE_DATE,
COMMENDATION_SOURCE,
COMMENDATION_SOURCE_NAME,
COMPETENCE_DIMENSION,
COMPETENCE_DIMENSION_NAME,
SUM_SCORE,
BASE_DEPT_ID
from (
select A.APPLY_RECORD_ID,
A.COMMENDATION_ID,
C.COMMENDATION_NAME,
xmlagg(xmlelement(e, d.name, ',').extract('//text()')).getclobval() USER_NAME,
A.UPDATE_DATE,
C.COMMENDATION_SOURCE,
E.DICT_VALUE COMMENDATION_SOURCE_NAME,
c.COMPETENCE_DIMENSION,
F.DICT_VALUE COMPETENCE_DIMENSION_NAME,
sum(B.SCORE) SUM_SCORE,
A.BASE_DEPT_ID
from (
select APPLY_RECORD_ID,
COMMENDATION_ID,
UPDATE_DATE,
BASE_DEPT_ID
from DIAN_COMMENDATION_APPLY_RECORD A
where APPLY_STATUS = 'APPROVED'
and UPDATE_DATE >= trunc(sysdate)
and UPDATE_DATE <= trunc(sysdate+ 1)) A
left join (select SOURCE_ID, USER_ID, SCORE,USER_ACCOUNT_ID
from DIAN_COMMENDATION_DISTRIBUTE_RECORD DR
where DR.CREATION_DATE >= trunc(sysdate)
and DR.CREATION_DATE <= trunc(sysdate+ 1)) B
on a.APPLY_RECORD_ID = B.SOURCE_ID
left join DIAN_COMMENDATION C
on A.COMMENDATION_ID = c.COMMENDATION_ID
left join (select A.USER_ID,A.NAME,B.USER_ACCOUNT_ID
from DIAN_USER_EXPAND A
left join DIAN_USER_ACCOUNT b
on a.USER_ID=b.USER_ID
) D
on B.USER_ID = D.USER_ID
and B.USER_ACCOUNT_ID = D.USER_ACCOUNT_ID
left join (select DICT_VALUE, DICT_KEY
from DIAN_DICTIONARY_MAP
where DICT_TYPE = 'COMMENDATION_SOURCE'
and IS_ENABLE = 1) E
on E.DICT_KEY = c.COMMENDATION_SOURCE
left join (select DICT_VALUE, DICT_KEY
from DIAN_DICTIONARY_MAP
where DICT_TYPE = 'COMPETENCE_DIMENSION'
and IS_ENABLE = 1) F
on F.DICT_KEY = c.COMPETENCE_DIMENSION
group by A.APPLY_RECORD_ID,
A.COMMENDATION_ID,
C.COMMENDATION_NAME,
A.UPDATE_DATE,
C.COMMENDATION_SOURCE,
E.DICT_VALUE,
c.COMPETENCE_DIMENSION,
F.DICT_VALUE,
A.BASE_DEPT_ID
));
/**
* create by: lcb
* create date:2023-10-30
* modify by:wxx
* modify date:2023-12-8 加入基地ID BASE_DEPT_ID
* describe:同步当天表彰历史数据 (每3分钟同步一次)
*/
BEGIN
--循环
FOR ITEM IN C_JOB
LOOP
-- 判断数据是否存在
SELECT COUNT(1) INTO V_COUNT_1 FROM DIAN_HONORING_HISTORY WHERE APPLY_RECORD_ID = ITEM.APPLY_RECORD_ID;
IF V_COUNT_1 = 0 THEN
-- 不存在则添加数据
INSERT INTO DIAN_HONORING_HISTORY(APPLY_RECORD_ID,
COMMENDATION_ID,
COMMENDATION_NAME,
USER_NAMES,
UPDATE_DATE,
COMMENDATION_SOURCE,
COMMENDATION_SOURCE_NAME,
COMPETENCE_DIMENSION,
COMPETENCE_DIMENSION_NAME,
SUM_SCORE,
BASE_DEPT_ID)
VALUES (ITEM.APPLY_RECORD_ID,
ITEM.COMMENDATION_ID,
ITEM.COMMENDATION_NAME,
ITEM.USER_NAMES,
ITEM.UPDATE_DATE,
ITEM.COMMENDATION_SOURCE,
ITEM.COMMENDATION_SOURCE_NAME,
ITEM.COMPETENCE_DIMENSION,
ITEM.COMPETENCE_DIMENSION_NAME,
ITEM.SUM_SCORE,
ITEM.BASE_DEPT_ID);
IF V_COUNT_2 < 100 THEN
V_COUNT_2 := V_COUNT_2 + 1;
ELSE
V_COUNT_2 := 0;
COMMIT;
END IF;
END IF;
END LOOP;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
V_ERR_MSG := SQLERRM || CHR(13) || DBMS_UTILITY.FORMAT_ERROR_BACKTRACE;
JA_WRITE_LOG(JA_UTILS_PKG.GET_FN_NAME(), 'ERROR', V_ERR_MSG, -1, 1);
END;
/
2、设置Oralcle定时器
-- 表彰历史
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
JOB_NAME => 'SYNCHRONIZE_HONORING_HISTORY2',
JOB_TYPE => 'PLSQL_BLOCK',
JOB_ACTION => 'SYNCHRONIZE_HONORING_HISTORY;',
START_DATE => to_date('18-10-2022 00:00:00', 'dd-mm-yyyy hh24:mi:ss'),--开始时间
ENABLED => TRUE, --创建完成后激活
REPEAT_INTERVAL => 'TRUNC(SYSDATE,''MI'')+3/(24*60)', --每3分钟执行一次
-- REPEAT_INTERVAL => 'TRUNC(SYSDATE + 1) + (8*60 + 30)/(24*60)', --每天8:30执行
COMMENTS => '每三分钟统计表彰历史'
);
END;注意:
如果是第一次使用定时器,需要手动将先前数据同步,如果数据量少可以从开始时间直接同步至当前时间对应数据,但是数据量较大则不建议这么做,会加剧数据库查询和存储的的负担,因此可能需要分时间对其切片,设置开始时间和结束时间并且跨度不宜过大,一点点同步到当前时间,后面就由定时器自动同步就好。
3.定时器的禁用与删除
也会遇到不再使用该定时器的情况,这时候提供了两种操作——禁用或删除。
操作步骤如下:
先查询数据库中的定时任务,查到相关信息如任务名,通过对查询到的任务名执行禁用/删除。
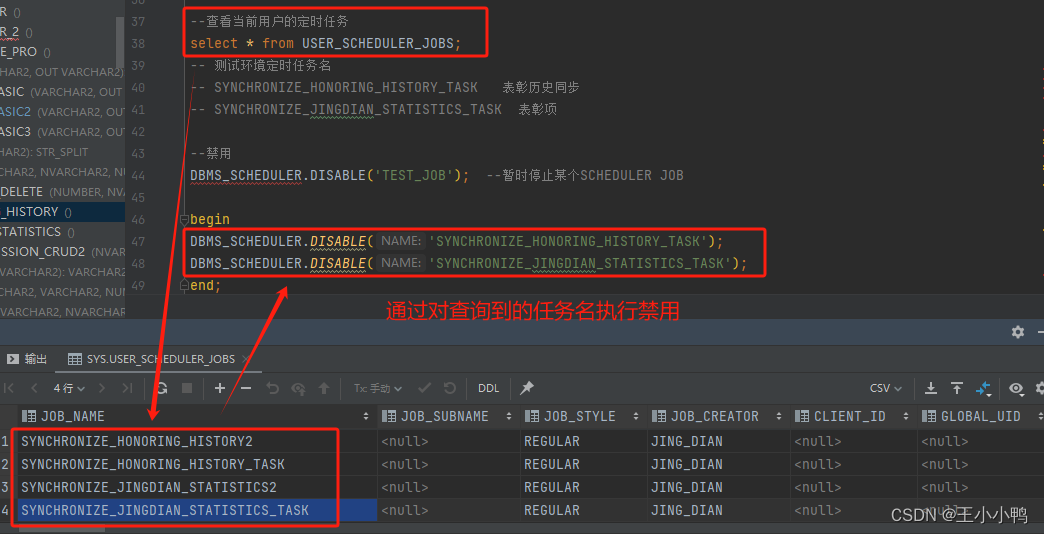
查看当前用户的定时任务指令
--查看当前用户的定时任务
select * from USER_SCHEDULER_JOBS;-- 测试环境定时任务名 -- SYNCHRONIZE_HONORING_HISTORY_TASK 表彰历史同步 -- SYNCHRONIZE_JINGDIAN_STATISTICS_TASK 表彰项
禁用指令
--禁用
DBMS_SCHEDULER.DISABLE('TEST_JOB'); --暂时停止某个SCHEDULER JOB--禁用定时任务
begin
DBMS_SCHEDULER.DISABLE('SYNCHRONIZE_HONORING_HISTORY_TASK');
DBMS_SCHEDULER.DISABLE('SYNCHRONIZE_JINGDIAN_STATISTICS_TASK');
end;
删除指令
--删除
DBMS_SCHEDULER.DROP_JOB(JOB_NAME => 'TEST_USER_INSERT',FORCE => TRUE);-- 删除定时任务 begin DBMS_SCHEDULER.DROP_JOB(JOB_NAME => 'SYNCHRONIZE_HONORING_HISTORY_TASK',FORCE => TRUE); DBMS_SCHEDULER.DROP_JOB(JOB_NAME => 'SYNCHRONIZE_JINGDIAN_STATISTICS_TASK',FORCE => TRUE); end;
这里我用的是禁用,状态可以在查询中查看,再次执行代码
--查看当前用户的定时任务 select * from USER_SCHEDULER_JOBS;
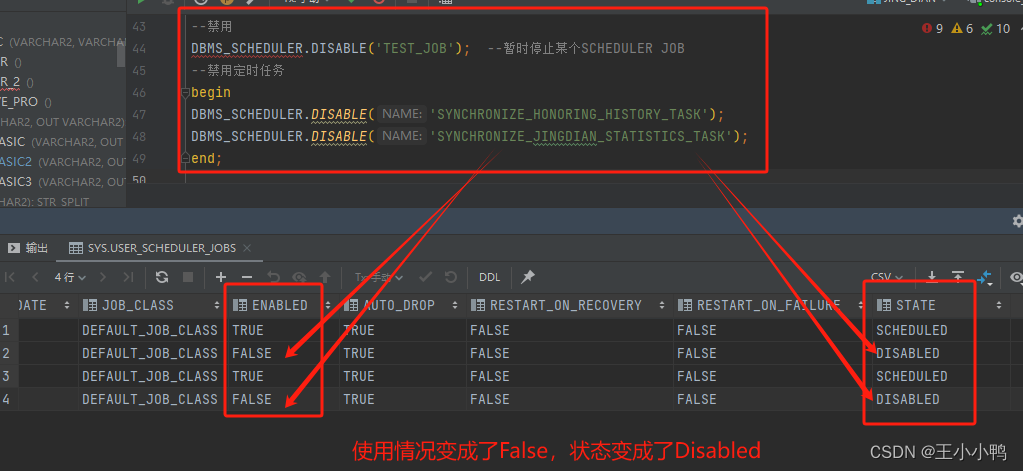
可以看到使用情况变成了False,状态变成了Disabled,应用成功啦!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++内存分配策略
- 剑指offer题解合集——Week1day5
- 自然语言处理4——深度学习驱动情感分析 - Python高级实践
- 重磅!2024版一建新教材开始预售!(新大纲版)
- 探讨接口方法中的 public 修饰符
- 字符串数据处理方式
- 【2023年度总结】多变的2023 | 成长的2023 | 蜕变的2023
- 【技术篇】Linux下一键安装Mysql5.7的脚本以及安装包附百度网盘脚本下载
- Effective C++——尽可能使用const
- 深入了解 Python MongoDB 查询:find 和 find_one 方法完全解析