5.Pytorch模型单机多GPU训练原理与实现
文章目录
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
Pytorch的单机多GPU训练
1)多GPU训练介绍
当我们使用的模型过大,训练数据比较多的时候往往需要在多个GPU上训练。使用多GPU训练时有两种方式,一种叫ModelParallelism,一种是DataParallelism。

ModelParallelism方式,是在模型比较大导致一张显卡放不下的时候,将模型拆分然后分别放到不同的显卡上,将同一份数据分别输入进行模型训练。这种对模型结构各模块之间有联系时很不友好,有可能都不支持拆分。因此,应用更广泛的是DataParallelism的方式。
DataParallelism方式,是将相同的模型拷贝到不同的显卡上,然后将数据平均划分后输入到相应显卡上进行计算,然后根据计算结果更新模型的参数。
DataParallelism方式更新模型参数时,因为每个显卡上都有一个完整的模型,其可以单独根据一个显卡的运算结果更新参数,即异步更新,也可以将各个显卡的运算结果汇总后再根据总的运算结果一次性更新模型参数,即同步更新。因此,使用DataParallelism模型参数的更新有两种选择方式,不过值得注意的是不同显卡上的模型参数是共享的,也就是虽然不同显卡上都有完整的模型,但模型参数用的是同一份,都是相同的。 所以在模型初始化的时候就要给不同显卡上的模型初始化相同的权重值。根据两种权重更新策略的区别,可以发现,对于单个显卡上batch_size本身就比较大的情况,可以使用异步更新,这样不需要显卡之间运算同步,可以提升训练速度;而对于batch_size比较小的情况,根据mini_batch随机梯度下降算法的原理,最好选用同步更新的方式,保证学习效果。
图片引用自【分布式训练】单机多卡的正确打开方式(一):理论基础

参数同步更新
参数异步更新
使用多GPU训练时,还需要注意的是使用BatchNormalization的情况,对于BN层归一化时,是在单个显卡上计算,还是在不同的显卡之间做同步再计算,同样,对于batch_size比较大时建议使用异步运算,小时使用同步计算以保证模型学习的效果。
2)pytorch中使用单机多GPU训练
相对于tensorflow来说,pytorch中设置模型进行多GPU训练的方式就显的简单多了。在这里只介绍现在pytorch中使用最多的多GPU训练方式即使用DistributedDataParallel类。
DistributedDataParallel(DDP)相关变量及含义
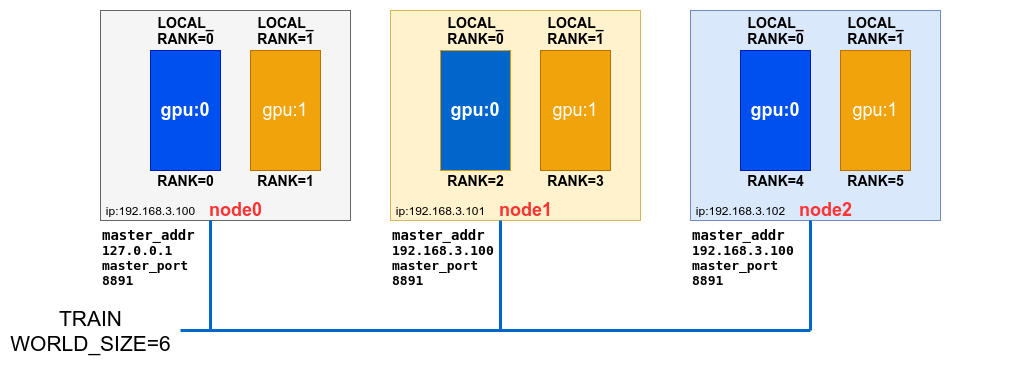
DDP支持在多个机器中进行模型训练,其中每个机器被称之为节点Node,每个机器上有可能有多个GPU,为了不受GIL的限制,DDP会针对每个GPU启动一个进程进行训练,每个进程在对应机器上的编号使用环境变量LOCAL_RANK进行标识。
一次训练,在所有Node上启动的训练进程总和使用WORLD_SIZE来统计。而在分布在所有Node的上某个进程在全局所有进程中的序号使用环境变量RANK进行记录。
介绍到这DDP的整体原理和使用的变量就很清楚了,
DDP
参考上图,是假设有3台机器,每台机器上有2个GPU的情况。值的注意的是master_address和master_port上的参数,这两个参数是告诉其他进程主进程(RANK=0的进程)的端口号和IP地址,以便于其与主进程之间进行通信,包括数据交换,同步等。
下面几部分,就分别对pytorch模型实现单机多GPU训练要进行哪些设置分别进行介绍。
a)初始化
在编写多GPU训练的代码时,需要先对环境进行初始化,需要调用init_process_group来初始化默认的分布式进程组(default distributed process group)和分布式包(distributed package)。使用的是pytorch的torch.distributed.init_process_group方法。
该方法原型:
torch.distributed.init_process_group(backend=None, \
init_method=None, \
timeout=datetime.timedelta(seconds=1800), \
world_size=-1, \
rank=-1, \
store=None, \
group_name='', \
pg_options=None)
函数参数:
backend: 参数类型为str or Backend,根据pytorch编译时的配置来选择,支持mpi/gloo/nccl/ucc,这个后端指的是多GPU之间进行通信的方式,根据不同类型的GPU进行选择,对于NVIDIA的GPU一般选择nccl,对于Intel的GPU一般选择ucc。init_method: 参数类型为str,指定初始化方法,一般使用env://,表示使用环境变量MASTER_ADDR和MASTER_PORT来初始化。和store变量是互斥的。timeout: 参数类型为datetime.timedelta,指定初始化超时时间,如果超时则抛出异常。world_size: 参数类型为int,指定进程组的大小,如果为-1,则使用环境变量WORLD_SIZE来指定,定义store变量时必须指定world_size。rank: 参数类型为int,指定当前进程在进程组中的排位,如果为-1,则使用环境变量RANK来指定,定义store变量时,必须指定rank。store: 参数类型为Store,指定用于保存分布式训练状态的存储Key/Value对象,用于交换连接/地址信息,所有的进程都能访问,和init_method方法互斥。group_name: 参数类型为str,指定进程组的名字,这个变量已经是deprecated了。pg_options: 参数类型为ProcessGroupOptions,指定进程组的其他选项,如allreduce_post_hook等,目前仅对nccl后端支持ProcessGroupNCCL.Options选项。
使用torch.distributed.init_process_group初始化进程组的两种方式:
- 指定
store/rank/world_size - 指定
init_method,明确给出进程间在哪通过哪种协议发现其他进程并通信,此时rank/world_size是可选的
初始化后,进程组可以通过torch.distributed.get_world_size()和torch.distributed.get_rank()来获取进程组大小和当前进程在进程组中的排位。
所以最简单的初始化方式,只需要指定后端即可:
torch.distributed.init_process_group(backend='nccl')
每个进程的环境变量RANK是在启动时由torchrun命令行工具自动添加的,WORLD_SIZE是在torchrun启动时根据启动的进程数自动添加的。
b)数据准备
在pytorch中,数据的准备是先实例化torch.utils.data.Dataset的数据类,然后再将其放入数据加载器torch.utils.data.DataLoader中,以控制加载数据的进程数num_worker、采样器sampler和batch_size大小等。
在使用DistributedDataParallel实现训练时,在数据加载器中上需要使用两个采样器sampler = DistributedSampler(data)和batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size, drop_last=True)来指定数据采样器,这样可以保证每个进程每个batch只处理属于自己的数据。
这里一起来看下DistributedSampler和BatchSampler。
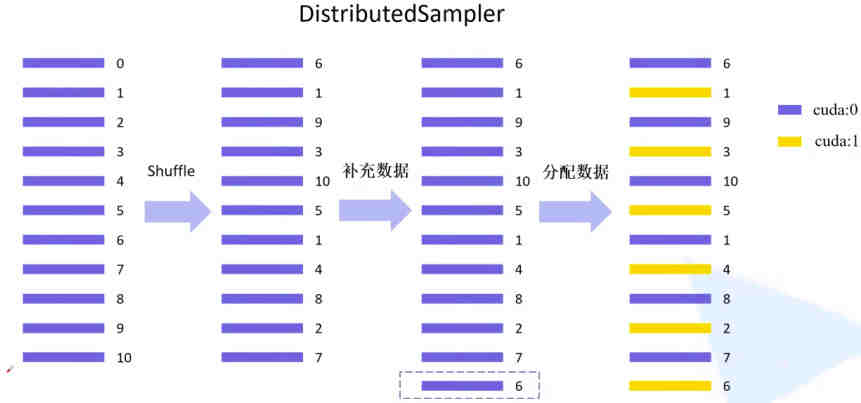
DDP模式就是将数据均分到多个GPU上来优化算法,对于每个GPU该如何从总的训练数据中采样属于自己用的数据,这就需要一个采样策略,这正是DistributedSampler发挥的作用。
DistributedSampler
如上图,假设有11个样本,GPU的数量为2,DistributedSampler的作用先是把数据打散,然后均分到每个gpu上,当数据不组时,会采用循环重复的策略来补满。
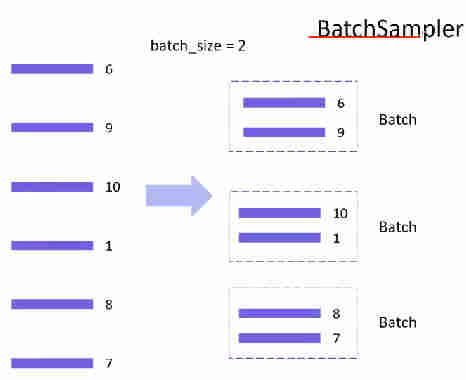
torch.utils.data.BatchSampler则是指定每个batch的样本数量,以及是否丢弃最后一个可能不足的batch。当设置drop_last=True时,会将最后不足一个batch的数据丢弃。
BatchSampler
上面介绍的过程是对于一轮数据训练时数据加载器的工作过程,对整个训练过程,为了保证学习的效果,需要在每个epoch设置采样器能重新打散数据,因此要在每一轮训练开始前调用DistributedSampler的set_epoch方法。
sampler = DistributedSampler(data)
batch_sampler = torch.utils.data.BatchSampler(
sampler, batch_size, drop_last=True)
dataloader = torch.utils.data.Dataloader(data_set, batch_sampler=train_batch_sampler)
for i in range(epoches):
sampler.set_epoch(epoch)
...
c)模型准备
使用DistributedDataParallel进行模型训练时,需要将模型放在DistributedDataParallel类中,这样模型就可以在多GPU上并行计算。
此外,还有一些需要注意的。
在设置device时,要想指定使用的GPU需要设置环境变量CUDA_VISIBLE_DEVICES=1,2,在代码中对于模型,可以使用model.to(device)来设置,device从LOCAL_RANK中获取,当设置CUDA_VISIBLE_DEVICES时,LOCAL_RANK的0时从指定的GPU开始的,而不是硬件上的GPU序号,例如指定CUDA_VISIBLE_DEVICES=1,2时,LOCAL_RANK=0时对应的是GPU1,LOCAL_RANK=1时对应的是GPU2。
# in train.py
import os
device = f'cuda:{os.getenv(LOCAL_RANK)}'
执行,
CUDA_VISIBLE_DEVICES=1,2 torchrun --nnodes 1 --nproc_group_size 2 train.py
加载模型后对于使用多GPU时还需注意的是参数初始化,要使用同一份权重值对模型进行初始化,否则在模型训练时,每个GPU上的模型参数就会不一样,从而导致训练效果不佳。一种方案是将主进程上的权重先保存下来,然后再加载到其他进程的模型上:
model = Model()
if not os.path.exists(weights_path):
checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")
if rank == 0:
torch.save(model.state_dict(), checkpoint_path)
dist.barrier()
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
上面的代码的功能很明了,值得注意的是dist.barrier()语句,它表示等待所有进程都到达这个语句处,然后才进行下一步操作,确保所有进程都执行到这一步,然后才开始进行权重加载。
当模型使用BatchNormalization时,除了需要将模型放入DistributedDataParallel类中,还需要使用torch.nn.SyncBatchNorm.convert_sync_batchnorm方法对模型上的BN层进行转化,这样模型训练时,每个GPU上的BatchNormalization层就会与其他GPU上的BN层进行同步更新。
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[int(os.environ['LOCAL_RANK'])])
到这里,能够在多GPU上训练的模型就准备好了。下面再来看下模型训练时需要留意的地方。
- 训练过程中平均损失值的计算。在单个进程中
loss是在单个进程数据上计算的,为了记录训练过程,打印平均损失值时,要将所有进程上的loss值累加后除以进程组的大小,以得到平均损失值。
def reduce_value(value, average=True):
world_size = get_world_size()
if world_size < 2: # 单GPU的情况
return value
with torch.no_grad():
dist.all_reduce(value)
if average:
value /= world_size
return value
reduace_value(loss)
注意上面代码中使用的dist.all_reduce函数,它用于进行数据同步,将数据从所有进程收集到主进程上,并将主进程上的数据广播到所有进程上,这样所有进程上的数据就相同了。
-
训练完一个
epoch时,在每个进程中要使用torch.cuda.synchronize(device),以确保使用当前设备的所有进程都计算完成。 -
在训练过程中使用
DDP模型,进程验证时,也需要使用dist.all_reduce来统计所有的运算结果:
@torch.no_grad()
def evaluate(model, data_loader, device):
model.eval()
sum_num = torch.zeros(1).to(device)
# 在进程0中打印验证进度
if os.getenv("RANK")==0:
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = dist.all_reduce(sum_num)
return sum_num.item()
d)清理
在训练代码的最后,定义完训练逻辑后,需要调用torch.distributed.destroy_process_group来关闭进程组,结束进程之间的通信。
torch.distributed.destroy_process_group()
e)运行
pytorch DistributedDataParallel多GPU训练任务启动的命令通常使用的是python -m torch.distributed.launch,在torch1.9.0版本后引入了torchrun命令,两者功能基本类似,python -m torch.distributed.launch 和 torchrun 在功能上是类似的。它们都是用于启动分布式训练的命令行工具,可以自动设置环境变量并启动训练脚本。torchrun 是 PyTorch 1.9.0 版本引入的新命令,旨在为分布式训练提供更简洁和一致的接口。与python -m torch.distributed.launch相比,torchrun具有一些额外的功能和灵活性,例如支持不同的运行模式和分布式运行时后端。对于使用较新版本PyTorch的情况,建议使用torchrun` 来保持一致性以使用其提供的新功能。
关于torchrun和python -m torch.distributed.launch命令支持的选项可以使用--help来查看。
torchrun --nnodes 1 --nproc_per_node 2 train.py train_args
python -m torch.distributed.launch --nnodes 1 --nproc_per_node train.py train_args
更底层的方法可以使用torch.multiprocessing.spawn函数来启动训练,它需要传递一个训练函数和进程数量作为参数。
3)使用DistributedDataParallel训练模型的一个简单实例
import torch
import torchvision
import os
import math
import tqdm
import sys
batch_size=256
epoches = 100
num_classes = 10
torch.distributed.init_process_group(backend='nccl')
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(128),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[1.0, 1.0, 1.0])])
train_dataset = torchvision.datasets.CIFAR10(root="./data/cifar10",
train=True,
download=True,
transform=transform)
val_dataset = torchvision.datasets.CIFAR10(root="./data/cifar10",
train=False,
download=True,
transform=transform)
num_classes = len(val_dataset.classes)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset)
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler,
batch_size,
drop_last=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset,
batch_sampler=train_batch_sampler,
pin_memory=True,
num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
sampler=val_sampler,
pin_memory=True,
num_workers=4)
device = f'cuda:{os.getenv("LOCAL_RANK")}' if torch.cuda.is_available() else 'cpu'
device = torch.device(device)
m = torchvision.models.mobilenet_v3_small(pretrained=False,
num_classes=num_classes)
ckpt_path = "/tmp/init_weight.pt"
if int(os.getenv("LOCAL_RANK")) == 0:
torch.save(m.state_dict(), ckpt_path)
torch.distributed.barrier()
m.load_state_dict(torch.load(ckpt_path, map_location=device))
m = torch.nn.SyncBatchNorm.convert_sync_batchnorm(m).to(device)
m = torch.nn.parallel.DistributedDataParallel(m, device_ids=[int(os.getenv("LOCAL_RANK"))])
params = [ param for param in m.parameters() if param.requires_grad ]
optimizer = torch.optim.SGD(params=params,
lr=0.001,
momentum=0.9,
weight_decay=0.005)
lr_func = lambda x : (1 + math.cos(x * math.pi / epoches)) / 2 * (1 - 0.1) + 0.1
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=optimizer,
lr_lambda=lr_func)
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(epoches):
train_sampler.set_epoch(epoch)
m.train()
optimizer.zero_grad()
avg_loss = torch.zeros(1, device=device)
right_pred_num = torch.zeros(1, device=device)
best_acc = 0.0
if int(os.getenv("LOCAL_RANK")) == 0:
pbar = tqdm.tqdm(train_dataloader, file=sys.stdout)
else:
pbar = train_dataloader
for i, (image, label) in enumerate(pbar):
image = image.to(device)
label = label.to(device)
pred = m(image)
loss = loss_func(pred, label)
loss.backward()
torch.distributed.all_reduce(loss)
avg_loss = (avg_loss * i + loss.detach()) / (i + 1)
if int(os.getenv("LOCAL_RANK")) == 0:
pbar.desc = f"[epoch: {epoch}] step: {i}, learning_rate: {scheduler.get_last_lr()} average loss: {round(avg_loss.item(), 3)}"
assert torch.isfinite(loss), f"Nan Loss, Training End."
optimizer.step()
optimizer.zero_grad()
torch.cuda.synchronize(device=device)
m.eval()
with torch.no_grad():
if int(os.getenv("LOCAL_RANK")) == 0:
pbar = tqdm.tqdm(val_dataloader, file=sys.stdout)
else:
pbar = val_dataloader
for i, (image, label) in enumerate(pbar):
image = image.to(device)
label = label.to(device)
pred = m(image)
pred = torch.max(pred, dim=1)[1]
right_pred_num += torch.eq(pred, label).sum()
torch.cuda.synchronize(device=device)
torch.distributed.all_reduce(right_pred_num)
if int(os.getenv("LOCAL_RANK")) == 0:
acc = round(right_pred_num.item() / len(val_dataset), 3)
print(f"Val Accuracy: {acc}")
if acc > best_acc:
best_acc = acc
print(f"New Best Accuracy: {acc}, Model Saved: best.pt")
torch.save(m.state_dict(), "best.pt")
# CUDA_VISIBLE_DEVICES=3,4 torchrun -nnodes 1 --nproc_per_node 2 train.py
# [epoch: 31] step: 23, learning_rate: [0.0007911220577405485] average loss: 3.66:
# 100%|██████████████████████████████████████████████| 5/5 [00:01<00:00, 3.01it/s]
# Val Accuracy: 0.239
# New Best Accuracy: 0.239, Model Saved: best.pt
# [epoch: 32] step: 23, learning_rate: [0.0007790686370876671] average loss: 3.635:
# 100%|██████████████████████████████████████████████| 5/5 [00:01<00:00, 3.18it/s]
# Val Accuracy: 0.247
# New Best Accuracy: 0.247, Model Saved: best.pt
代码也可从‵gitee`仓库中下载https://gitee.com/lx_r/object_detection_task。
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
1.https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/train_multi_GPU
2.pytorch多GPU并行训练教程
3.https://zhuanlan.zhihu.com/p/178402798
4.https://pytorch.org/tutorials/beginner/ddp_series_multigpu.html?highlight=multi
5.https://pytorch.org/tutorials/beginner/ddp_series_theory.html#why-you-should-prefer-ddp-over-dataparallel-dp
6.https://medium.com/red-buffer/getting-started-with-pytorch-distributed-54ae933bb9f0
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!