NVIDIA A100 PCIE 40GB k8s-device-plugin install in kubernetes

文章目录
1. 目标
- 一台服务器
- 配置 NVIDIA A100 GPU 40G
- 安装 NVIDIA R450+ datacenter driver
- kubespray 部署单节点 kubernetes v1.27.7
- 部署 NVIDIA k8s-device-plugin
- 应用测试 GPU
2. 简介
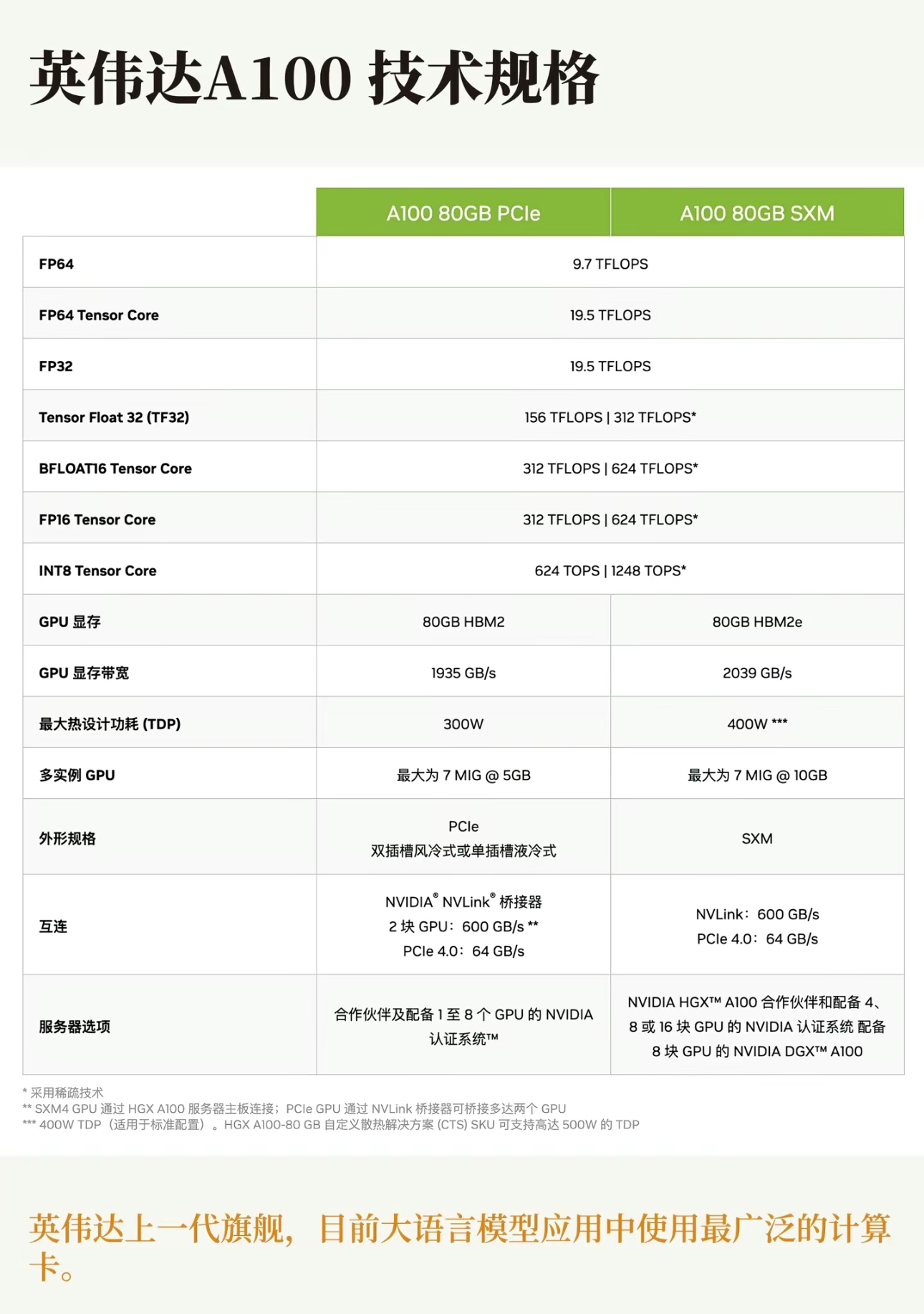
2.1 英伟达 A100 技术规格
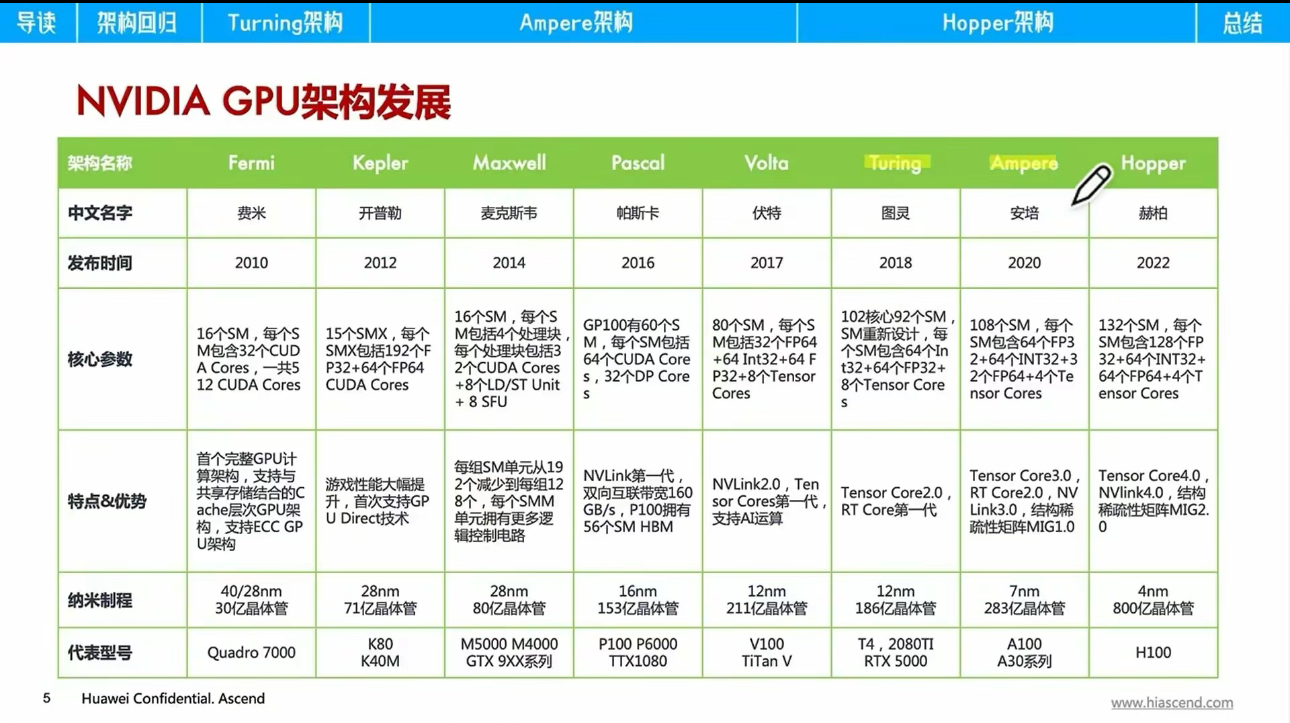
2.2 架构优势
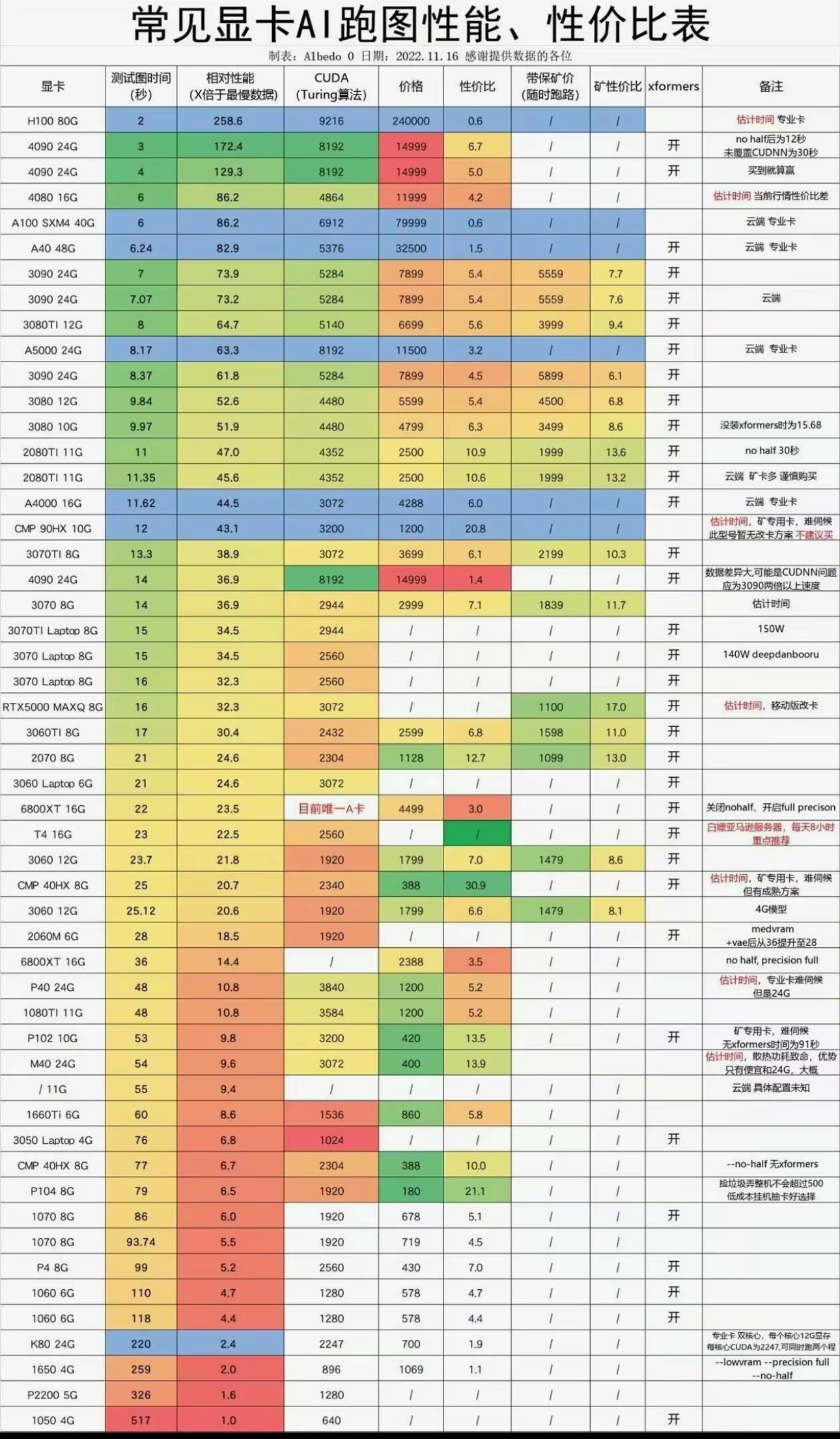
2.3 显卡跑分对比
2.4 英伟达 A100 与 kubernetes
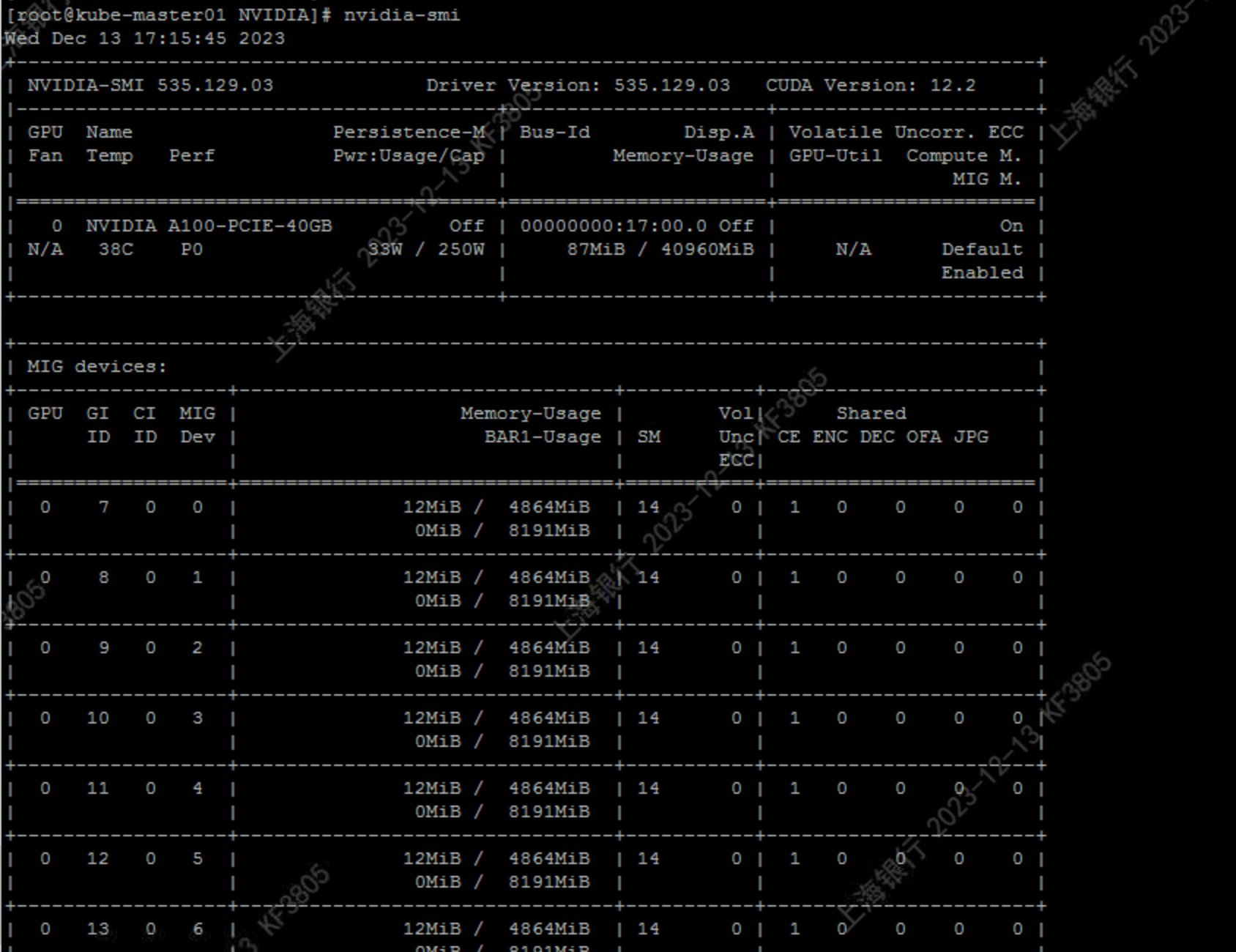
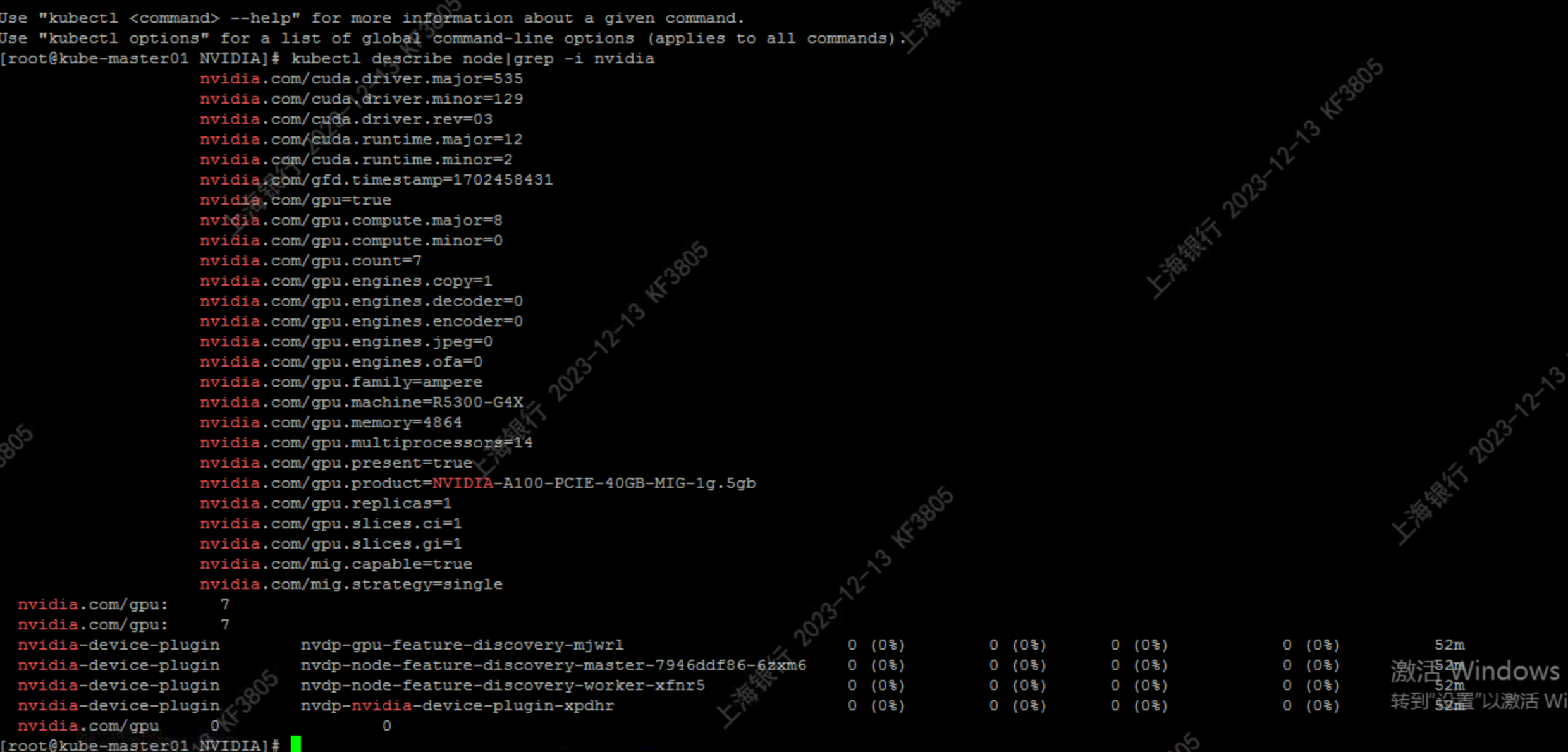
多实例GPU(GPU)功能允许NVIDIA A100 GPU针对CUDA应用安全地划分为多达七个独立的GPU实例,为多个用户提供独立的GPU资源,以实现最佳的GPU利用率。此功能对于未完全饱和GPU计算能力的工作负载特别有益,因此用户可能希望并行运行不同的工作负载以最大限度地提高利用率。
本文档概述了为Kubernetes启用SQL支持所需的软件。有关技术概念的更多详细信息,请参阅“NVIDIA用户指南”,设置"NVIDIA容器工具包“以使用”NVIDIA容器工具包“运行容器。
部署工作流需要以下预配置:
- 您已安装NVIDIA A100所需的NVIDIA R450+数据中心(450.80.02+)驱动程序。
- 您已安装NVIDIA容器工具包v2.5.0+
- 您已经启动并运行了Kubernetes部署,并可以访问至少一个NVIDIA A100 GPU。
满足这些先决条件后,您可以继续在集群中部署具有可扩展性的NVIDIA k8s-device-plugin版本和(可选)gpu-feature-discovery组件,以便Kubernetes可以在可用的可扩展性设备上调度pod
所需软件组件的最低版本列举如下:
- NVIDIA R450+ datacenter driver: 450.80.02+
- NVIDIA Container Toolkit (nvidia-docker2): v2.5.0+
- NVIDIA k8s-device-plugin: v0.14.3
- NVIDIA gpu-feature-discovery: v0.2.0+
3. 安装 NVIDIA A100 GPU 40G 硬件
- 视频英伟达 A100 测评:https://www.youtube.com/watch?v=zBAxiQi2nPc

内部构造分布



4. NVIDIA R450+ datacenter driver
- 下载 NVIDIA R450+ datacenter driver: 450.80.02+
- 下载 NVIDIA-Linux-x86_64-535.129.03.run
- -安装:
sh NVIDIA-Linux-x86_64-535.129.03.run
5. NVIDIA Container Toolkit
包名称
如果离线下载需要这四个包
$ ls NVIDIAContainerToolkit/
libnvidia-container1-1.14.3-1.x86_64.rpm nvidia-container-toolkit-1.14.3-1.x86_64.rpm
libnvidia-container-tools-1.14.3-1.x86_64.rpm nvidia-container-toolkit-base-1.14.3-1.x86_64.rpm
在线下载安装
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
sudo yum-config-manager --enable nvidia-container-toolkit-experimental
sudo yum install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=containerd
cat /etc/nvidia-container-runtime/config.toml
6. 创建 runtimeclass
cat nvidia-RuntimeClass.yaml <<EOF
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
EOF
kubectl apply -f nvidia-RuntimeClass.yaml
5. MIG Strategies
NVIDIA提供了两种在Kubernetes节点上暴露Android设备的策略。有关策略的更多详细信息,请参阅设计文档。
在Kubernetes中使用策略
本节将介绍为不同的SDK策略部署和运行k8s-device-plugin和gpu-feature-discovery组件所需的步骤。首选的部署方法是通过Helm。
有关替代部署方法,请参阅以下GitHub存储库中的安装说明:
6. 配置仓库
首先,添加nvidia-device-plugin和gpu-feature-discovery helm存储库:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
helm repo update
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm search nvdp
helm search repo nvdp
helm pull nvgfd/gpu-feature-discovery --version 0.14.3 --untar --destination /root/NVIDIA/
helm pull nvdp/nvidia-device-plugin --version 0.14.3 --untar --destination /root/NVIDIA/
helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
helm repo update
helm search repo nvgfd
helm pull nvgfd/gpu-feature-discovery --version 0.8.2 --untar --destination /root/NVIDIA/
如果是离线环境需要下载
7. 下载镜像
docker pull nvidia/k8s-device-plugin:v0.14.3
docker pull registry.k8s.io/nfd/node-feature-discovery:v0.12.1
docker pull nvcr.io/nvidia/gpu-feature-discovery:v0.8.2
docker save -o nvidia-k8s-device-plugin-v0.14.3.tar nvidia/k8s-device-plugin:v0.14.3
docker save -o nfd-node-feature-discovery-v0.12.1.tar registry.k8s.io/nfd/node-feature-discovery:v0.12.1
docker save -o nvidia-gpu-feature-discovery-v0.8.2.tar nvcr.io/nvidia/gpu-feature-discovery:v0.8.2
镜像入库, 以 registry01.ghostwritten.com为例
docker load -i nvidia-k8s-device-plugin-v0.14.3.tar
docker load -i nfd-node-feature-discovery-v0.12.1.tar
docker load -i nvidia-gpu-feature-discovery-v0.8.2.tar
docker tag nvidia/k8s-device-plugin:v0.14.3 registry01.ghostwritten.com/nvidia/k8s-device-plugin:v0.14.3
docker tag registry.k8s.io/nfd/node-feature-discovery:v0.12.1 registry01.ghostwritten.com/nvidia/node-feature-discovery:v0.12.1
docker tag nvcr.io/nvidia/gpu-feature-discovery:v0.8.2 registry01.ghostwritten.com/nvidia/gpu-feature-discovery:v0.8.2
docker push registry01.ghostwritten.com/nvidia/k8s-device-plugin:v0.14.3
docker push registry01.ghostwritten.com/nvidia/node-feature-discovery:v0.12.1
docker push registry01.ghostwritten.com/nvidia/gpu-feature-discovery:v0.8.2
8. 打标签
kubectl label nodes kube-master01 feature.node.kubernetes.io/pci-10de.present=true
kubectl label nodes kube-master01 nvidia.com/gpu=true
kubectl label nodes kube-master01 feature.node.kubernetes.io/pci-10de.present=true
kubectl label nodes kube-master01 feature.node.kubernetes.io/cpu-model.vendor_id=NVIDIA
kubectl label nodes kube-master01 nvidia.com/gpu.present=true
9. 设置master 可调度
kubernetes 设置节点可调度
kubectl taint node node01 node-role.kubernetes.io/master-
10. 定制 charts
$ vim nvidia-device-plugin/values.yaml
.....
migStrategy: single
...
image:
repository: registry01.ghostwritten.com/nvidia/k8s-device-plugin
pullPolicy: IfNotPresent
tag: "v0.14.3"
....
tolerations:
- key: nvidia.com/gpu
operator: Exists
...
nfd:
nameOverride: node-feature-discovery
enableNodeFeatureApi: false
master:
extraLabelNs:
- nvidia.com
serviceAccount:
name: node-feature-discovery
worker:
tolerations:
- key: "nvidia.com/gpu"
operator: Exists
gfd:
enabled: enable
nameOverride: gpu-feature-discovery
$ vim nvidia-device-plugin/charts/gpu-feature-discovery/values.yaml
image:
repository:registry01.ghostwritten.com/nvidia/gpu-feature-discovery
pullPolicy: IfNotPresent
tag: "v0.8.2 "
11. 部署
helm install --version=0.14.3 nvdp -n nvidia-device-plugin --set migStrategy=single --set runtimeClassName=nvidia --create-namespace
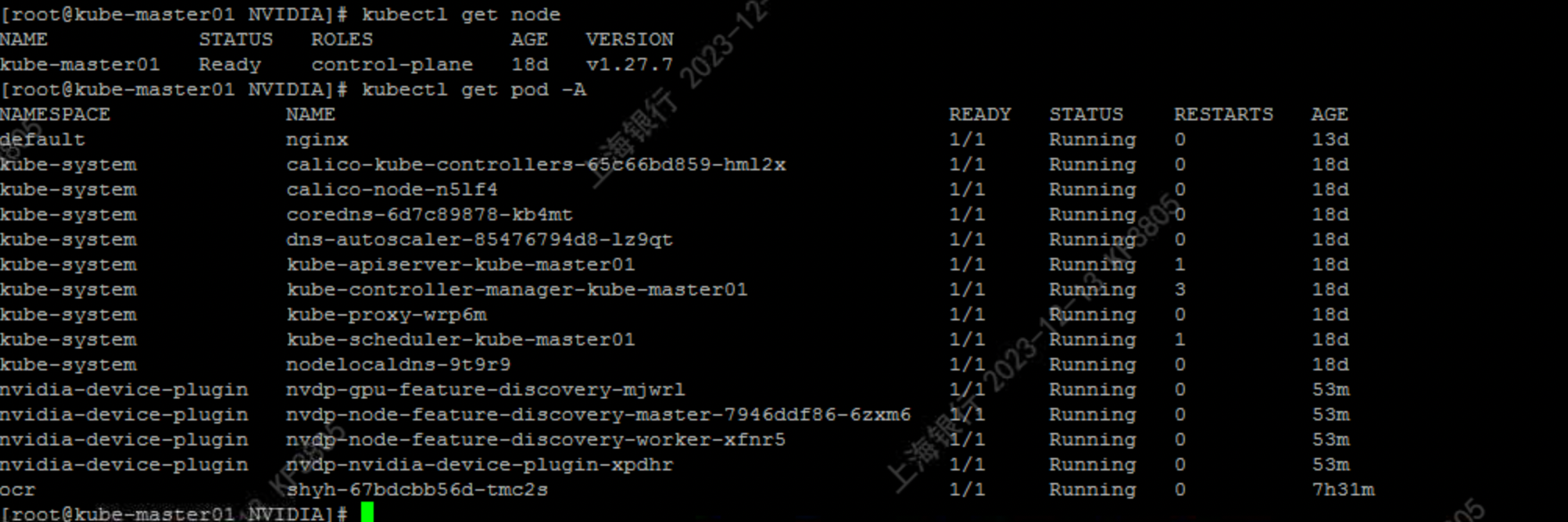
12. 测试
kubectl run -it --rm \
--image=registry01.ghostwritten.com/nvidia/cuda:9.0-base \
--restart=Never \
--limits=nvidia.com/gpu=1 \
mig-none-example -- nvidia-smi -L
输出:
GPU 0: A100-SXM4-40GB (UUID: GPU-15f0798d-c807-231d-6525-a7827081f0f1)
13. 问题
-
Getting nvidia-device-plugin container CrashLoopBackOff | version v0.14.0 | container runtime : containerd
创建 runtimeclass
cat nvidia-RuntimeClass.yaml <<EOF
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
EOF
kubectl apply -f nvidia-RuntimeClass.yaml
参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!