10.常用统计分析方法——主成分分析和因子分析
基础知识:
主成分分析概念
主成分分析PCA:是一种数据降维的技巧,将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。
在特征选择方法中有一种方法是方差过滤,即如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同,那这一个特征的取值对样本而言就没有意义(即不带有效信息)。从方差的这种应用可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标就是样本方差,方差越大,特征所带的信息量越多。

?Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,代表这一列样本的均值。(方差计算公式中除的是n-1,是为了得到样本方差的无偏估计)
因子分析概念
探索性因子分析(EFA):是用一系列用来发现一组变量的潜在结构的方法。通过寻找一组更小、更隐蔽的或隐藏的结构来解释已观测到的,显式的变量间的关系。
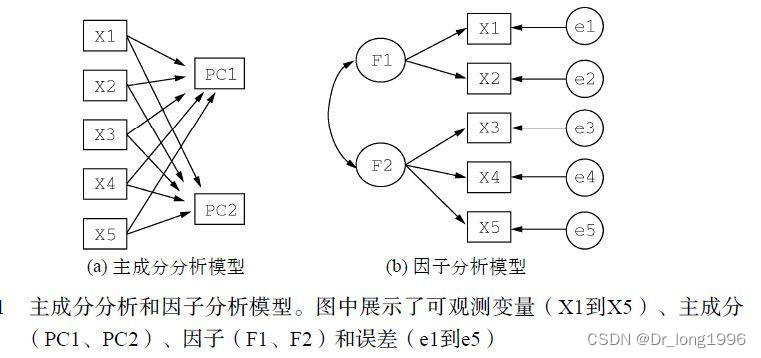
主成分PC1,PC2是观测变量(X1到X5)的线性组合。形成线性组合的权重都是通过最大化各主成分所解释的方差来获得的,同时还要保证各主成分间不相关。
因子F1,F2被当作观测变量的结构基础或“原因”,而不是他们的线性组合。代表观测变量方差的误差(e1到e5)无法用因子解释。
样本量
因子分析需要5-10倍的于变量数的样本量。如果你有几百个观测,样本量已充足。
PCA和EFA的分析函数
推荐psych()包中的函数
| 函数 | 描述 |
|---|---|
| principle()函数 | 含有多种可选的方差旋转方法的主成分分析 |
| fa()函数 | 可用主轴、最小残差、加权最小平方或最大似然法估计因子分析 |
| fa.parallel ( )函数 | 含平行分析的碎石图 |
| factor.plot( )函数 | 绘制因子分析或主成分分析的结果 |
| fa.diagram( )函数 | 绘制因子分析或主成分分析的负荷矩阵 |
| scree()函数 | 因子分析和主成分分析的碎石图 |
主成分分析
主成分分析的基本步骤

?

 ?
?
?psych包主成分分析
案例:数据集USJudegeRatings包含了律师对美国高等法院法官的评分。数据框包含了43各观测,12各变量。
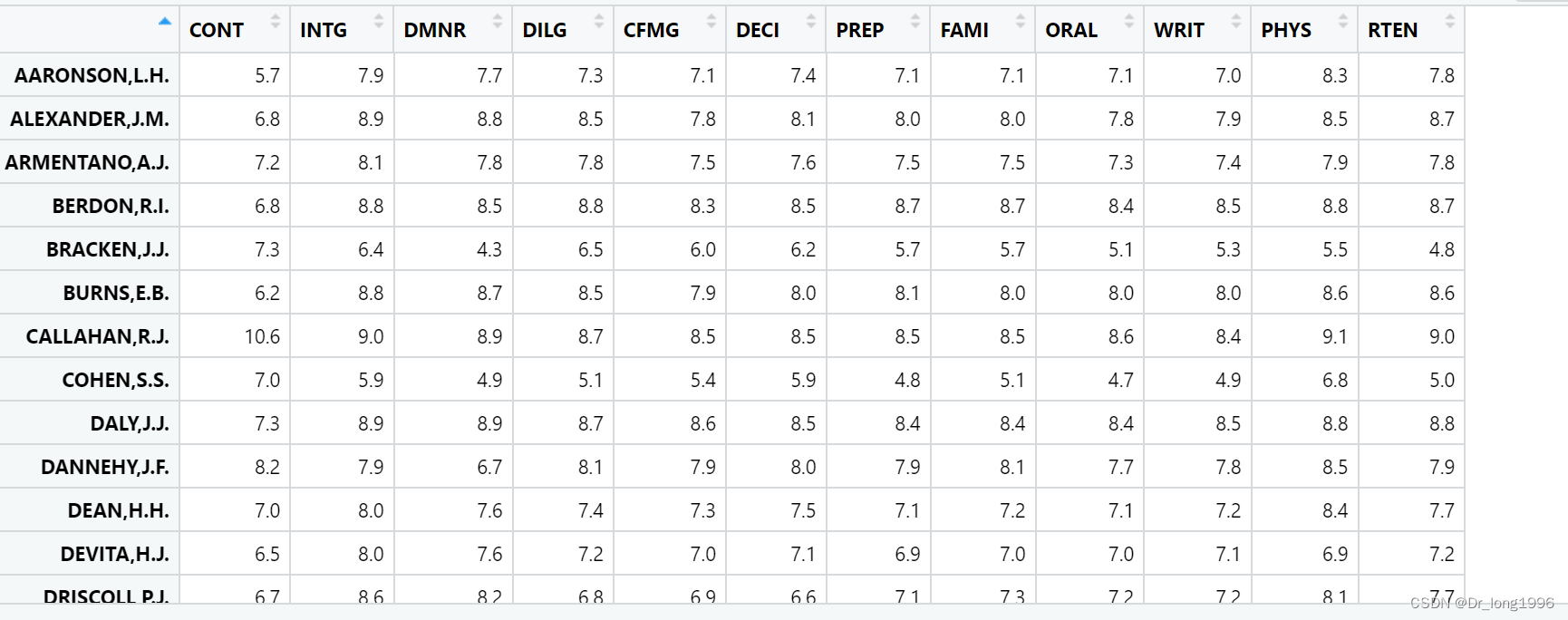
CONT:律师与法官的接触次数;
INTG:法官的正直程度;
DMNR:风度;
DILG:勤勉度;
CFMG:案例流程管理水平;
DECI:决策效率;
PREP:审理前的准备工作
FAMI:对法律的熟悉程度;
ORAL:口头裁决的可靠度;
WRIT:书面裁决的可靠度;
PHYS:体能;
RTEN:是否值得保留。
判断主成分个数
因为需要使用更少的变量来评估法官,目标是简化数据,所以使用PCA。数据保持原始得分形式,没有缺失值。因此下一步是要判断需要多少个主成分?
判断PCA需要多少个主成分的准则:
- 根据先验经验和理论知识判断主成分数;
- 根据要解释变量方差的累计值的阈值来判断需要的主成分数;
- 通过检查变量间K*K的相关系数矩阵来判断保留的主成分数。
方法一:最常见的是基于特征值的方法:主成分都与相关系数矩阵的特征值相关联,第一个主成分与最大的特征值相关联,第二个主成分与第二大的特征值相关联,依次类推。Kaiser-Harris准则建议保留特征值大于1的主成分。
方法二:Cattle碎石检验则描绘了特征值与主成分数的图形,这类图形可以清晰的展示图形的弯曲状况,在图形变化最大处之上的主成分都可以保留。
方法三:平行分析:进行模拟,依据与初始矩阵相同大小的随机数据矩阵来判断要提取的特征值,若基于真实数据的某个特征值大于一组随机数据矩阵相应的平均特征,那么主成分可以保留。
data(USJudgeRatings)
library(psych)
fa.parallel(USJudgeRatings[,-1],fa="pc",n.iter = 10,
show.legend = F,
main = "Scree plot with parallel analysis")利用fa.parallel()函数对三种特征值判别准则进行评价。对于11种评分(删除CONT)。

?基于观测特征值的碎石检验(由线段和x符合组成)。根据100个随机数据矩阵推到出来的特征均值线(虚线),以及大于 1的特征准则(y=1的水平线)。
结果解读:三种准则都提示一个主成分既可以保留数据集的大部分信息。
提取主成分
基本函数格式:
r是相关系数矩阵或原始数据框矩阵
nfactors设定主成分个数,默认为1
rotate指定旋转的方法(默认最大方差旋转variman)
scores设定需要计算主成分得分(默认不需要)
pc <- principal(USJudgeRatings[,-1],nfactors = 1)
pc

?由于PCA只对相关系数矩阵进行分析,在获取主成分之前,原始数据将会被自动转换为相关系数矩阵。
PC1栏中包含了成分载荷,指观测变量与主成分的相关系数。如果不止一个主成分的话,就会由PC2,PC3等。从结果中PC1与各个变量之间都高度相关,则说明他是一个可用来进行一般性评价维度。
h2栏指成分公因子方差,即每个主成分对每个变量的方差解释度。u2栏指成分唯一性,即方差无法被主成分解释的比例(1-h2)。
ss loading行包含了与主成分相关联的特征值,指的是与特定主成分相关联的标准化后的方差值。本案例中PC1为10。proprotion Var表示每个主成分对整体数据的解释程度。也即是pc1解释了11个变量的92%的方差。
主成分得分
从原始数据中提取成分得分
pc <- principal(USJudgeRatings[,-1],nfactors = 1,scores = T)
head(pc$scores)
案例二:Harman.cor数据集是305个女孩的8个身体测量指标,该数据是相关系数组成,而不是原始数据集。
(1)判断主成分个数:
library(psych)
fa.parallel(Harman23.cor$cov,n.obs = 302,
fa = "pc",n.iter = 100,
show.legend = F,
main = "Scree plot with parallel analysis")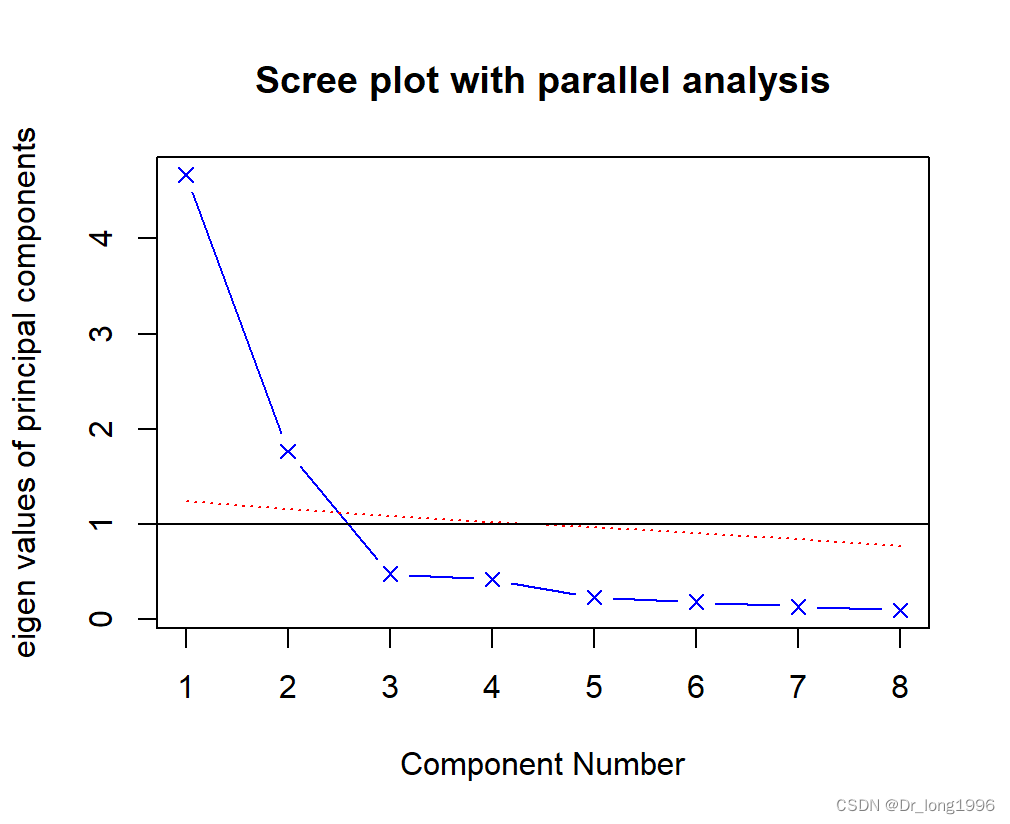
根据图形中K-H准则,碎石检验和平行分析都建议选择两个主成分。
(2)进行主成分分析
pc <- principal(Harman23.cor$cov,nfactors = 2,rotate = "none")
pc 从结果中可以看到第一个主成分解释了身体测量指标58%的方差,而第二个主成分解释了22%的方差,两者综合一共解释了81%的方差,对于height,两者共解释了其88%的方差。
从结果中可以看到第一个主成分解释了身体测量指标58%的方差,而第二个主成分解释了22%的方差,两者综合一共解释了81%的方差,对于height,两者共解释了其88%的方差。
负荷阵解释了成分和因子的含义,第一主成分与每个身体测量指标都呈正相关,第二个主成分与前四个变量呈负相关,与后四个变量呈正相关。当提取多个成分时,对他们进行旋转可以使结果更具解释性。
旋转:
是一系列将成分载荷阵变得更容易解释的数学方法,他们尽可能地对成分去噪。
旋转的方法:
正交旋转:使选择的成分保持不相关
斜交旋转:使选择的成分变得相关
最流行的正交旋转是方差极大旋转。
rc <- principal(Harman23.cor$cov,nfactors = 2,rotate = "varimax")
rc ?
?
?列名由pc变成了rc表明已经被旋转,第一个主成分主要由前四个变量来解释(长度变量),rc2栏的载荷表示第二个主成分主要有变量5-8来解释(容量变量)。两个主成分仍不相关。两个变量的总的解释度81%没有改变,只是rc1由pc1的58%降为了44%,rc2由原来的pc222%升高到37%。准确来说我们此时称呼他们作为成分而不是主成分。
获得主成分得分系数
当主成分分析是基于相关系数矩阵时,原始数据便不可再用,也不可能获取每个观测的主成分得分,但是你可以得到用来计算的主成分得分的系数。
round(unclass(rc$weights),2)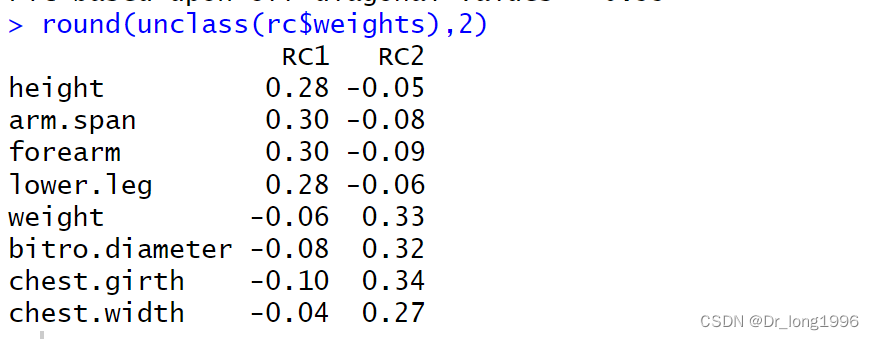
?可以得到以下主成分得分公式:
和
?
基础包主成分分析
?对相关系数矩阵进行特征分解:
cor.matrix <- Harman23.cor$cov
eigen(cor.matrix) values中显示各个主成分的特征值,前两个特征值大于1,且前两个特征值之和占总特征值总和(总和为变量的个数8)的(80.5%),所以保留前两个主成分。
values中显示各个主成分的特征值,前两个特征值大于1,且前两个特征值之和占总特征值总和(总和为变量的个数8)的(80.5%),所以保留前两个主成分。
前两个主成分可以表示为:
?
还可以使用stat包中的函数princomp()函数完成。
PCA <- princomp(covmat=cor.matrix)
summary(PCA,loadings = T)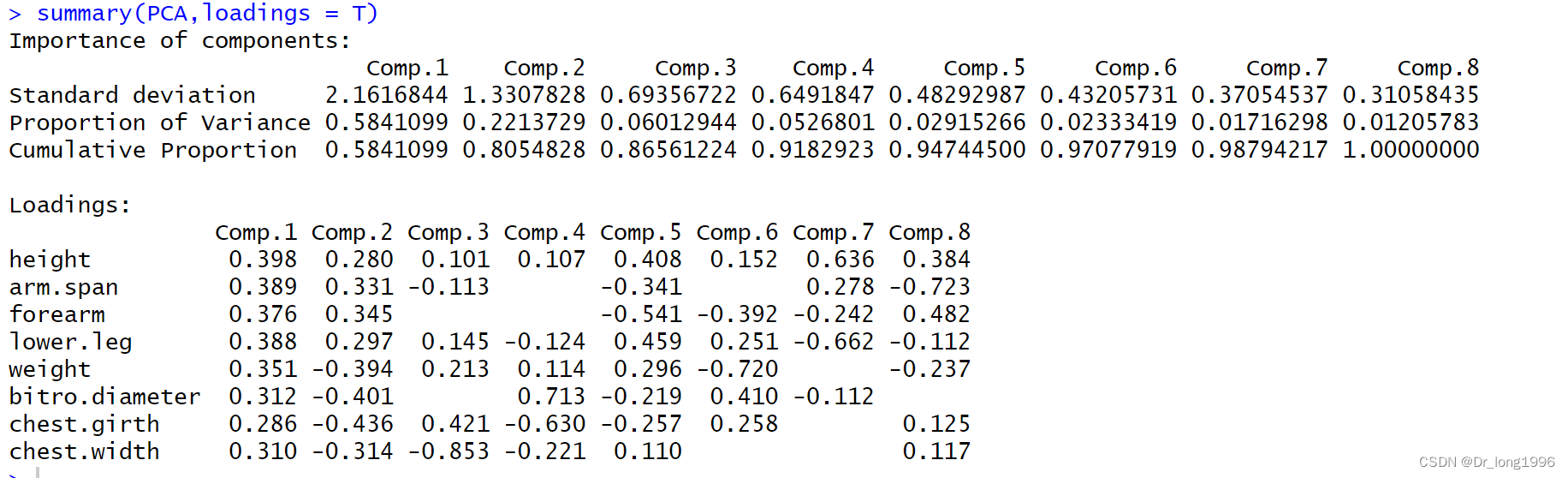
leading=T表示显示载荷矩阵,载荷矩阵中绝对值小于0.1的数值没有显示。如果想要全部显示,可以将参数cutoff设置为0。
绘制碎石图:
screeplot(PCA,type = "lines")
abline(h=1)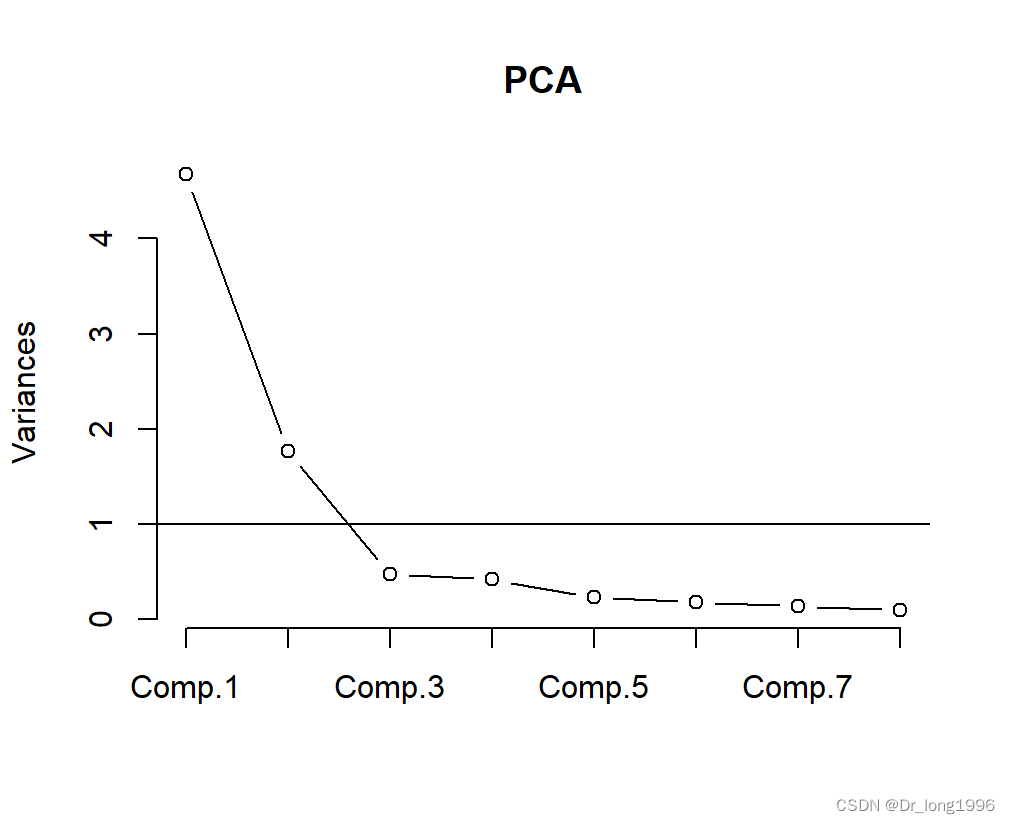
?
后面6个主成分的散点形成平台,且特征值均小于1,因此仅保留前两个。
主成分分析注意事项
(1)当原始变量之间的相关性较小时,应用主成分分析是没有意义的。
(2)主成分分析可以基于协方差矩阵或相关系数矩阵,得到的结果通常是不同的,当指标之间的取值范围彼此相差不大时,可以用协方差矩阵进行主成分分析,这样可以尽量保留了原始变量的意义。而当指标之间的取值范围相差较大或者量纲不同时,应采用相关系数矩阵进行主成分分析。
(3)主成分分析的主要目的时降维,虽然主成分分析的结果就可以解释一些问题,但是更多情况主成分分析并不是最终目的。
因子分析
EFA的目的时通过发掘隐藏在数据下的一组较少、更为基本的无法观测的变量,来解释一组可观测变量的相关性。
?这些虚拟的、不可观测的变量称作因子。(每个因子被认为可解释多个观测变量间共有的方差,因此也称作公因子)
模型的基本形式:

?F是表示公因子,Ui是Xi变量独有的部分(无法被公因子解释)。ai可以认为是每个因子对复合而成的可观测变量的贡献值。
案例:112个人参加了六个测验,包括非语言的普通智力测验(general1)、画图测验(picture)、积木图案测验(blocks)、迷宫测验(maze)、阅读测验(reading)和词汇测验(vocab)。如何用一组较少、潜在的心理学因素来解释参与者的测验得分。
数据集ability.cov提供了变量的协方差矩阵,可以转化用cov2cor()函数将其转化为相关系数矩阵。
options(digits = 2)
covariances <- ability.cov$cov
correlations <- cov2cor(covariances)判断提取的公共因子数
fa.parallel(correlations,n.obs = 112,fa = "both",
n.iter = 100,
main = "Scree plots with parallel analysis")fa设置为both,同时展示主成分和公共因子分析的结果。
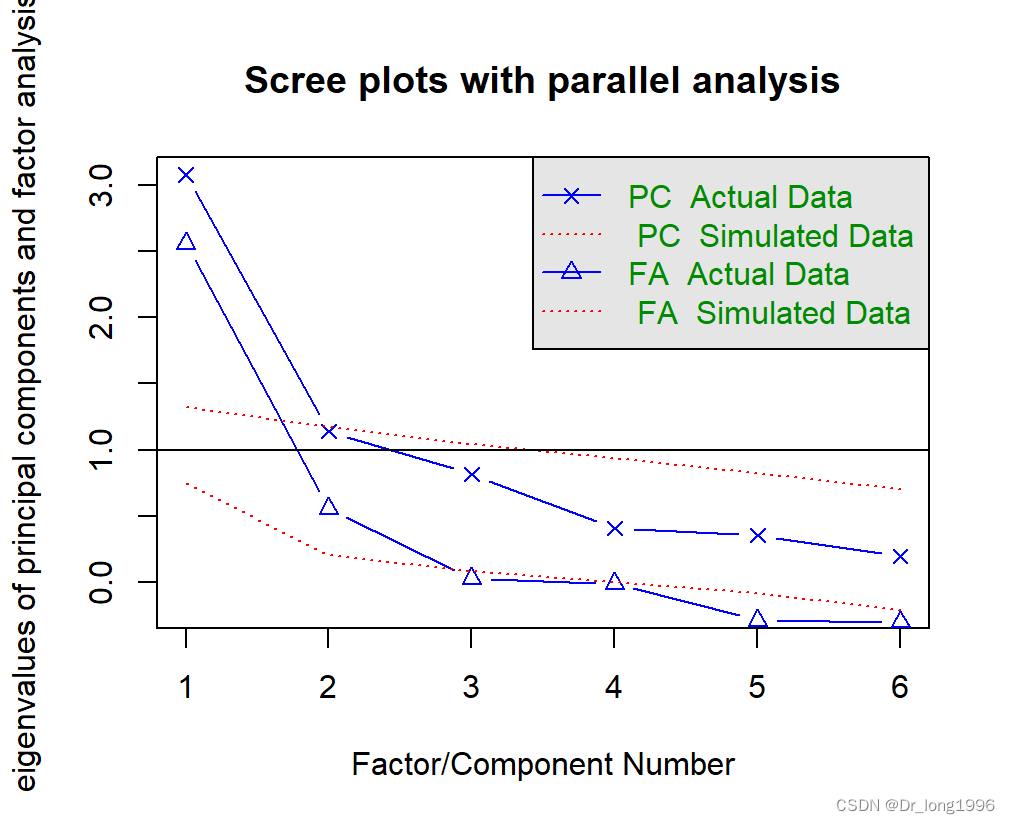
如果是PCA分析,可能会选择一个成分(碎石检验和平行分析)或者两个成分(特征值大于1),当摇摆不定时,高估因子数会比低估因子数的结果好,因为高估因子数一般较少曲解真实情况。
如果进行EFA分析,碎石检验前两个特征值都在拐角处之上,并且大于基于100次模拟数据矩阵的特征值均值。对于EFA,Kaiser-Harris准则的特征值数大于0而不是1。所以该准则中建议选择两个因子。
提取公因子
fa()函数可以提取公因子
r是相关系数矩阵或原始数据矩阵
nfactor设定提取的因子数目(默认为1);
n.obs是观测数;
rotate设定旋转的方法,默认为互变异数最小法;
scores设定是否计算因子得分;
fm设定因子话的方法(默认极小残差法)
与PCA不同,提取公共因子的方法很多,包括最大似然法(ml),主轴迭代法(pa),加权最小二乘法(wls),广义加权最小二乘法(gls)和最小残差法(minres)
(1)提取未旋转的主轴迭代因子法
fa <- fa(correlations,nfactors = 2,rotate = "none",fm="pa")
fa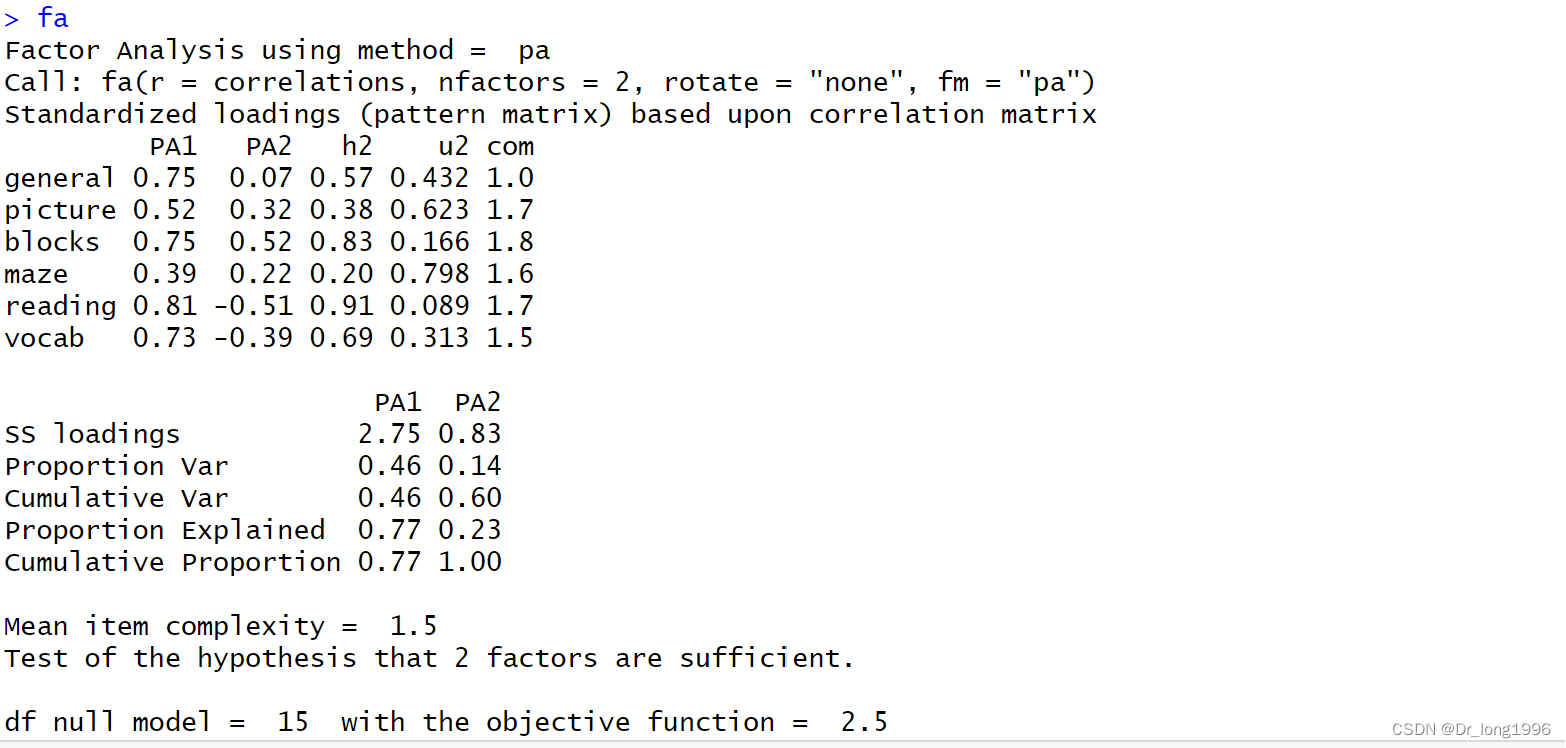
两个因子解释了六个心理学测试60%的方差,不过不太好解释。
(2)用正交旋转提取因子
fa <- fa(correlations,nfactors = 2,rotate = "varimax",fm="pa")
fa
这样结果就便于解释,第一个因子在阅读和词汇上载荷较大,画图、积木图案和迷宫在第二个因子上载荷较大,非语言的普通治理测量在两个因子上载荷较为平均,这表明存在一个语言智力因子和一个非语言智力因子。
(3)用斜交旋转提取因子
正交旋转,因子分析的重点在于因子结构矩阵(变量与因子的相关系数);斜交旋转,因子分析会考虑三个矩阵:因子结构矩阵,因子模式矩阵和因子关联矩阵。
因子模式矩阵即标准化的回归系数矩阵,它列出因子预测变量的权重。因子关联矩阵即因子相关系数矩阵。
fa <- fa(correlations,nfactors = 2,rotate = "promax",fm="pa")
fa
PA1和PA2栏中的值组成了因子模式矩阵,他们是标准化的回归系数,而不是相关系数。
因子关联矩阵显示PA1和PA2的相关系数为0.55,相关性较大。
fsm <- function(oblique){
if(class(oblique)[2]=="fa" & is.null(oblique$Phi)){
warning("Object doesn't look like oblique EFA")
} else{
P <- unclass(oblique$loading)
F <- P %*% oblique$Phi
colnames(F) <- c("PA1","PA2")
return(F)
}
}
fsm(fa)F为因子载荷矩阵,P为因子模式矩阵,Phi为因子关联矩阵,因此因子结构矩阵(载荷矩阵)F=P*Phi

?现在展示的是变量与因子之间的相关系数,将他们与正交旋转得到的因子载荷阵相比,该载荷阵的噪音较大,这是因为之前你允许潜在因子相关。
绘制正交/斜交的结果:
factor.plot(fa, labels = rownames(fa$loadings))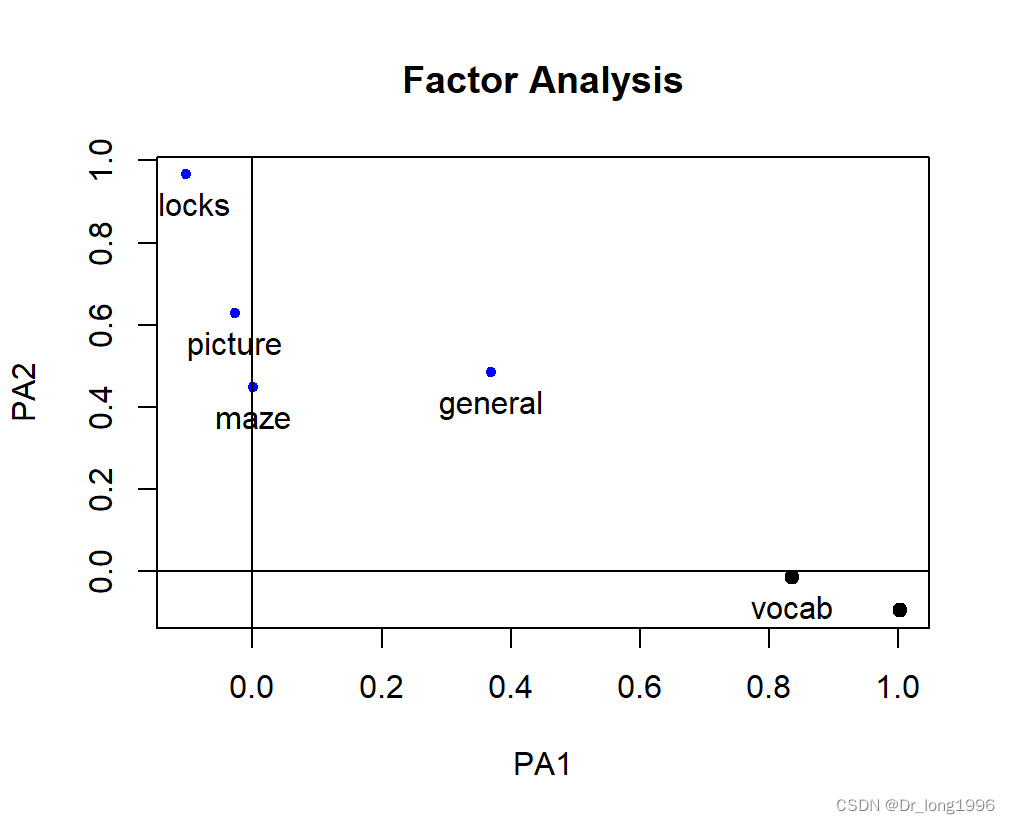
?
fa.diagram(fa,simple = F)simple设置为TRUE,仅显示每个因子下最大的载荷,以及因子间的相关系数。
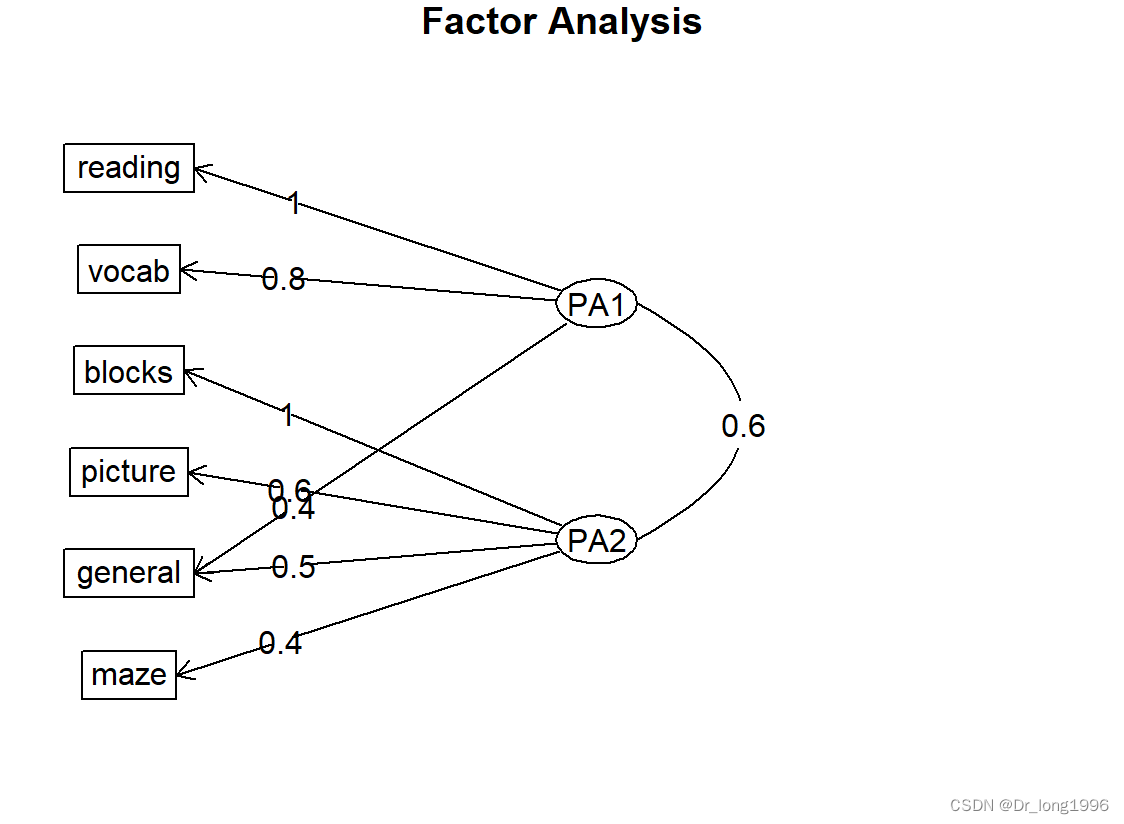
?
因子分析与主成分分析的关系
主成分分析严格来说不是一种模型,而是一种线性变换。
因子分析模型是将原始变量表示为公共因子和特殊因子的线性组合,因此其初始因子载荷中包含了特殊因子的影响。同时,因子载荷不是唯一的,因子旋转便于对因子载荷进一步简化,使得各个公共因子具有明确的实际意义。当特殊因子变差为0时,主成分分析和因子分析时等价。主成分分析的重点是在综合原始变量的信息,而因子分析的重点在于解释原始变量之间的关系。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!