【数据结构】栈算法(算法原理+源码)
博主介绍:?全网粉丝喜爱+、前后端领域优质创作者、本质互联网精神、坚持优质作品共享、掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战?有需要可以联系作者我哦!
🍅附上相关C语言版源码讲解🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
目录
一、栈算法
栈(Stack)是一种具有特定规则的数据结构,它基于后进先出(Last In, First Out,LIFO)的原则。这意味着最后进栈的元素将会是最先出栈的。栈常常用于实现函数调用、表达式求值、括号匹配等问题。
栈的基本操作:
- Push: 将元素压入栈顶。
- Pop: 从栈顶弹出元素。
- Top(或Peek): 查看栈顶元素但不弹出。
- isEmpty: 检查栈是否为空。
- Size: 获取栈中元素的数量。
栈的应用:
- 函数调用: 保存函数调用的上下文,包括局部变量、返回地址等。
- 表达式求值: 中缀表达式转后缀表达式,然后使用栈进行求值。
- 括号匹配: 检查表达式中的括号是否匹配。
- 浏览器前进后退: 使用两个栈分别保存前进和后退的页面。
- 撤销操作: 记录操作历史,可以通过栈实现撤销功能。
栈的实现方式:
- 数组: 使用数组实现栈,需要注意栈的大小限制。
- 链表: 使用链表实现栈,动态分配内存,栈大小可以灵活调整。?
二、算法实现
?通过
push、pop和peek操作对栈进行操作。
#include <iostream>
#define MAX_SIZE 100
class Stack {
private:
int arr[MAX_SIZE];
int top;
public:
Stack() {
top = -1;
}
bool isEmpty() {
return top == -1;
}
bool isFull() {
return top == MAX_SIZE - 1;
}
void push(int value) {
if (!isFull()) {
arr[++top] = value;
std::cout << "Pushed: " << value << std::endl;
} else {
std::cout << "Stack overflow!" << std::endl;
}
}
void pop() {
if (!isEmpty()) {
std::cout << "Popped: " << arr[top--] << std::endl;
} else {
std::cout << "Stack underflow!" << std::endl;
}
}
int peek() {
if (!isEmpty()) {
return arr[top];
} else {
std::cout << "Stack is empty!" << std::endl;
return -1; // Assuming -1 as an error value
}
}
};
int main() {
Stack myStack;
myStack.push(5);
myStack.push(10);
myStack.push(20);
std::cout << "Top of the stack: " << myStack.peek() << std::endl;
myStack.pop();
myStack.pop();
myStack.pop();
myStack.pop(); // Trying to pop from an empty stack
return 0;
}
执行结果:
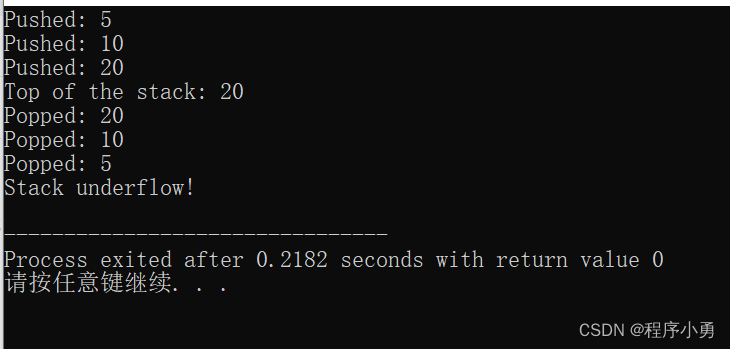
?三、小结
堆栈(栈)是一种基本的数据结构,其优点主要应用在一下方面:
-
简单直观: 栈的操作相对简单,主要包括入栈(Push)和出栈(Pop)两种基本操作。这种简单性使得栈易于理解和实现。
-
高效的操作: 由于遵循后进先出(LIFO)的原则,栈的操作具有常数时间复杂度。入栈和出栈的操作都只涉及栈顶元素,不需要遍历整个数据结构,因此效率较高。
-
内存管理: 栈的内存管理是自动的,当一个函数被调用时,其局部变量和函数调用信息被压入栈,函数执行完毕后自动弹出。这种自动管理有助于避免内存泄漏和提高程序的稳定性。
-
函数调用: 栈被广泛用于实现函数调用。每次函数调用时,局部变量和返回地址被存储在栈中,函数执行完毕后可以轻松地回到调用点。
-
递归: 栈为递归算法提供了自然的支持。递归调用时,每次调用都会创建一个新的栈帧,形成递归调用链。
-
表达式求值: 栈在中缀表达式转后缀表达式、以及后缀表达式求值等方面的应用是非常常见的,提供了一种简单而有效的解决方案。
-
回溯算法: 在深度优先搜索中,通常使用栈来存储搜索路径,以便回溯到先前的状态。
-
括号匹配: 栈常被用来检查表达式中的括号是否匹配,这是许多编程语言编译器和解释器的基本操作。
大家点赞、收藏、关注、评论啦 !
谢谢哦!如果不懂,欢迎大家下方讨论学习哦。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++-赋值-string字符串类-函数
- Excel删除重复项?4个方法帮你提升效率!
- js 文件下载 file-download
- React 18 新增的钩子函数
- 奇偶分家 PTA
- TCP/IP 传输层协议
- 当代大学生是怎么被废掉的?
- [uniapp] 文件查找失败:‘./iconfont.woff?t=1703574566334‘
- 展开运算符(Spread Operator)
- dnSpy调试工具断点信息是保存在哪里的呢