yarn集群datanode无法启动问题排查
发布时间:2024年01月22日
一、问题场景
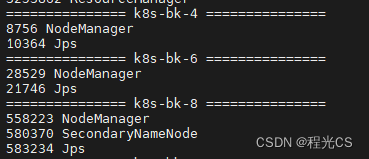
hdfs无法访问,通过jps命令查看进程,发现namenode启动成功,但是所有datanode都没有启动,重启集群(start-dfs.sh)后仍然一样
二、原因分析
先看下启动的日志有无报错。打开Hadoop的日志目录
cd $HADOOP_HOME/logs
按时间排序找出最新的datanode日志文件
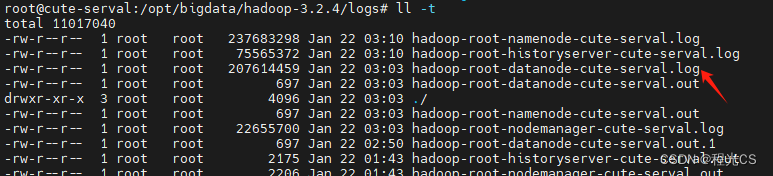
查看日志文件末尾的100行
cat hadoop-root-datanode-cute-serval.log | tail -n 100
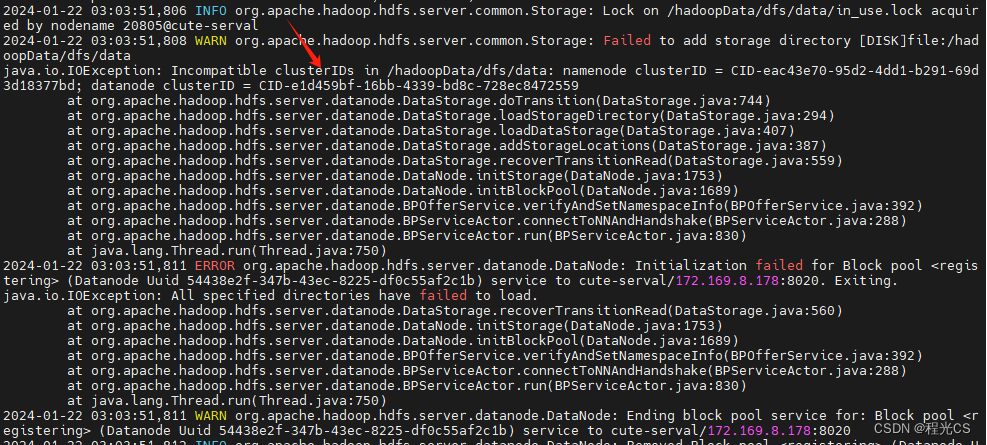
发现报错:datanode和namenode的clusterID不一致,最终导致了datanode无法正常启动
clusterID 是在 HDFS 集群的第一次格式化时生成的唯一标识符,用于确保 NameNode 和所有的 DataNode 属于同一个 HDFS 集群。如果ID 不匹配,DataNode 将无法加入集群。
Hadoop3.2中,NameNode和DataNode的clusterID配置文件在hdfs的数据目录的dfs目录下,在hdfs-site.xml文件中找到hdfs的数据目录,然后打开目录下的dfs目录:

NameNode的clusterID位置:
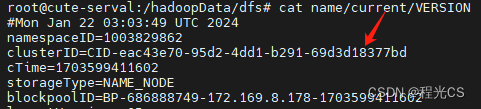
DataNode的clusterID位置:
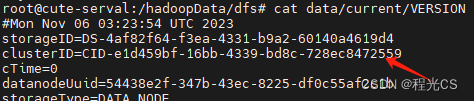
存在不一致
三、解决方案
方案一:将无法启动的datanode节点的clusterID手动改为与namenode一致,然后再重启datanode
方案二:完全重新格式化集群。如果集群还在初期部署阶段,可以考虑完全重新格式化整个集群。这将重置所有的 clusterID,但会导致丢失所有数据。要重新格式化,首先停止所有 HDFS 服务,然后在 NameNode 上运行 hdfs namenode -format,接着手动清除所有 DataNode 上的数据目录,最后重新启动整个集群。
文章来源:https://blog.csdn.net/m0_56602092/article/details/135743694
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!