线上问题整理
JVM 案例
案例一:服务器内存不足,影响Java应用
问题: 收到报警,某Java应用集群中一台服务器可用内存不足,超过报警阈值。
![[点击并拖拽以移动]](https://img-blog.csdnimg.cn/direct/d561acf20c5f4aa893f656b49a0e4399.png)
排查过程: 首先,通过Hickwall查看该应用各项指标,发现无论是请求数量、CPU使用率、还是JMX的各项指标均未发现异常。仅系统内存占用很高,但是从JMX指标中看,Java应用的Heap Memory、GC等都是正常的,在合理大小和范围内,未发现内存泄漏等问题。故怀疑不是Java应用本身的问题,而是系统上其他组件出了问题,但是从Hickwall等工具上又看不出其他组件的信息。然后,直接ssh登录到该服务器,由于是内存问题,故直接使用简单的top命令,根据内存占用排序后发现,是logagent进程占用了接近一半的系统内存。
由于账号权限限制,无法进一步处理,诱因找到后,随即反馈给网站运营中心的同事,帮忙临时将logagent进程杀死,系统恢复正常。后续经网站运营中心同事排查,发现是logagent内部bug,导致处理格式异常的日志文件时发生内存泄漏,后续打上补丁进行修复。

问题原因及思考: 目前公司各项监控工具已经比较完善,开发人员应熟练掌握并了解其中各项指标的含义,能够在分析具体问题时灵活运用各个工具,快速定位解决问题。
同时本案例虽然不是业务系统的问题,但这一案例也提醒了开发人员:线上实际问题可能是各方各面的,除了具备Java技术栈的相关的排障技能外,同时也要有基本的Linux操作能力,在已有工具无法帮助解决问题时,多一种途径快速定位问题,毕竟运营中心的同事人力有限,可能无法及时提供支持。
扩展
Java Full GC频繁: 可通过Hickwall中的JMX Full gc time/count指标观察Full GC情况,正常情况下不应有Full GC出现,Full GC意味着 STW,JVM会阻塞其他所有线程来进行垃圾回收,频繁的Full GC会严重影响应用的性能。如果出现Full GC通常意味着Java堆内存大小无法满足需求,如果不是代码缺陷导致(可通过以上OOM中JVM Sampler工具相关方法排查)则需要增加堆内存大小。
大数据量处理
案例一:大循环引起的 cpu 负载过高的问题
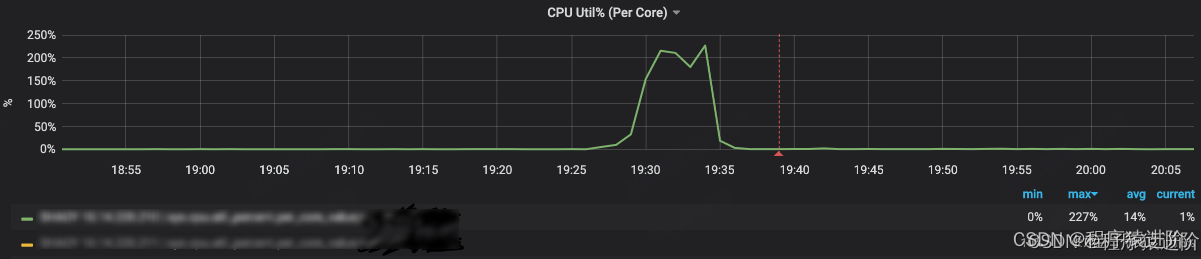
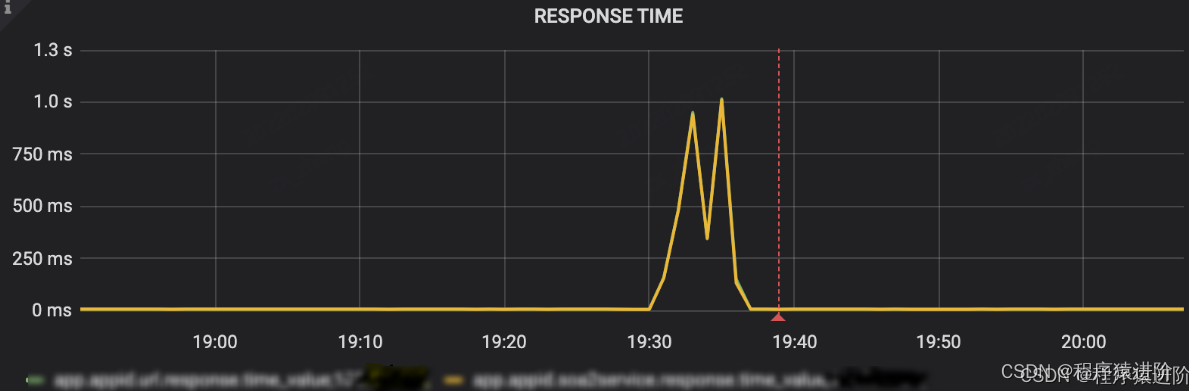
问题: x应用在一次发布时,cpu出现负载过高,其负载率突破200%,并且响应时间也大幅度超时。
代码:
List<CityDataModel> cities = cityDomainService.allCities();
for (CityDataModel city : cities) {
if (city.getCityCode().equalsIgnoreCase(flight.getDepartCity())) {
dCountry = city.getCountryCode();
}
if (city.getCityCode().equalsIgnoreCase(flight.getArriveCity())) {
aCountry = city.getCountryCode();
}
}
通过在测试环境尝试调用一次服务请求,发现其循环的数据是城市列表。该列表的长度达到12000,而且发现该循环本身被执行了11次,String::equalsIgnoreCase方法执行了18万次,也就是说这是一个典型的大循环的代码。 并且通过记录日志发现,在生产中该块代码平均每次请求都会调用24万次左右,这导致很多cpu资源都集中在该方法上,使得cpu load大幅度提高。
问题解决: 由于代码中的大循环非常耗费cpu资源,通过分析,这里的Strings::equalsIgnoreCase方法的主要作用在于遍历判断取数据。 根据这种查找数据的情况,优先选择使用HashMap替代,用空间换时间,经过修改后重新发布,其cpu利用率明显下降,恢复正常。
思考总结:
【1】使用循环时需要特别注意大循环,优先使用O(1)的HashMap,大循环对于cpu性能的压榨在这个问题上表现地淋漓尽致。
【2】镜像机器由于是使用生产流量转发访问,所以镜像发布高度贴近实际生产发布。在每次发布前,先使用镜像机器预发布,可以尽可能地将潜在的问题暴露出来。另外性能实验室中提供了cpu热点、内存分配热点和锁竞争热点的Flamegraph,在预发布中遇到问题时也可以更加直观地帮忙解决问题,并且不会对实际生产机器造成影响。
【3】此次发布前,虽然在测试环境进行了压测,但是并没有复现出该问题,分析原因,其与特定的压测的请求相关。由于在压测时使用的请求没有经过某些代码分支,使得循环的次数相比较少,故而在测试环境压测时没有暴露该问题。
【4】以上总结,除了代码层面的使用注意外,可以进行测试环境多种请求压力测试,以及生产镜像机器预发布等手段,来检测和杜绝这种潜在的问题发生。
案例二:多层嵌套 map
问题: 某日某查询服务器开始不断拉出集群,造成线上订单下跌。
遇到问题需咨询解决。。。
缓存
案例一:篡改缓存
问题: 查询接口下发错误数据故障
故障描述: 包含故障开始时间,发现时间,控制措施,故障排除细节
| Time | Event |
|---|---|
| 15:00 | 接到产品邮件告知下单调用查询接口的结果与前端的数据不一致,要求紧急对问题进行排查。 |
| 15:05 | 开始对问题进行排查,同时了解问题大概影响范围。 |
| 16:00 | 定位到是因为代码bug导致的接口在下发时,输出的结果不正确。3月1日接口由.net切换到了java版查询接口。 |
| 16:20 | 开始着手对bug进行修复,并进行紧急发布。 |
| 16:20 | 与产品沟通影响范围以及问题订单的处理办法。 |
| 16:30 | 确定影响的单量:10万 |
| 16:50 | 着手准备修复问题订单SQL |
| 18:00 | 完成紧急修复的上线 |
故障分析:
【1】为什么接口会下发错误?
.Net接口转Java过程中引发的代码bug,修改了本地缓存对象。
【2】为什么这个错误在代码review中没有被发现?
代码review不充分。虽然接口的逻辑并不复杂,但是代码量较多(40个文件,2000 additions and 1000 deletions),在review过程中遗漏了该错误。
【3】为什么在测试过程中没有发现该bug?
测试不充分,同时这个bug的触发存在一定概率性,当多个订单引用同一个基础服务对象时,在对礼盒进行遍历计算时,最后一个订单的计算结果会覆盖前面所有引用了该基础服务对象的订单。如果测试时选择的订单没有触发该·bug·,·.Net·和·Java·版本的对比结果是一致的。
【4】为什么影响的单量达·10W·以上规模?
该bug从2月12日发布直到3月3日才发现,持续了22天。
【5】为什么从2月12日起该问题直到3月3日才发现?
目前对于这类问题缺乏有效的检测机制,只能被动的等待客户投诉发生后才会反馈到开发团队。
分析总结:
【1】通过以上故障示例,我们可以发现缓存被修改带来的影响通常具有以下特性:
■ 不容易发现,因为数据可能只在特定条件下被修改。
■ 影响面非常广,因为数据本身是被频繁使用才会被加入缓存。
■ 不确定性,因为数据被修改具有“随机性”,该特性导致影响范围难以确定,数据也难以清洗。
【2】缓存篡改通常如何发生:
■ 从缓冲获取一个对象(引用),后续过程中修改了该对象的内部成员。
public class CityCache {
private static final CityCache INSTANCE = new CityCache();
private final Map<String, City> cityMap = new HashMap<>();
public static CityCache getInstance() {
return INSTANCE;
}
private CityCache() {
// 此处为了简便,没有写定时刷新
loadDataFromDB();
}
public City getCityByCode(String cityCode) {
return cityMap.get(cityCode);
}
private void loadDataFromDB() {
// load cities from database and put them into cityMap
}
}
@Data
public class City {
public City() {
}
public City(String code, int id) {
this.code = code;
this.id = id;
}
private String code;
private int id;
}
@Test
public void errorTest() {
// 通过SHA获取到缓存实体,该实体的三字码与SHA相同
City city1 = CityCache.getInstance().getCityByCode("SHA");
assertTrue("SHA".equals(city1.getCode()));
// 业务代码直接修改了city1的三字码(CityCache中的实体被修改)
city1.setCode("BJS");
// ...
// 再次通过SHA获取到缓存实体,该实体的三字码与SHA不相同了(非期望值)
City city2 = CityCache.getInstance().getCityByCode("SHA");
assertFalse("SHA".equals(city2.getCode()));
}
@Test
public void correctTest() {
// 通过SHA获取到缓存实体,该实体的三字码与SHA相同
City city1 = CityCache.getInstance().getCityByCode("SHA");
assertTrue("SHA".equals(city1.getCode()));
// 业务代码不能直接修改缓存实体,正确做法是先Copy一个对象,修改Copy对象的属性,后续业务使用该Copy对象
City cityCopy = new City(city1.getCode(), city1.getId());
cityCopy.setCode("BJS");
// ...
// 通过SHA获取到缓存实体,该实体的三字码与SHA相同
City city2 = CityCache.getInstance().getCityByCode("SHA");
assertTrue("SHA".equals(city2.getCode()));
}
■ 从缓冲获取一个集合(引用),后续过程中往该集合中添加/删除了元素。
public class CityCache {
private static final CityCache INSTANCE = new CityCache();
@Getter
private final Map<String, City> cityMap = new HashMap<>();
public static CityCache getInstance() {
return INSTANCE;
}
private CityCache() {
// // 此处为了简便,没有写定时刷新
loadDataFromDB();
}
private void loadDataFromDB() {
// load cities from database and put them into cityMap
}
}
@Data
public class City {
public City() {
}
public City(String code, int id) {
this.code = code;
this.id = id;
}
private String code;
private int id;
}
@Test
public void errorTest() {
Map<String, City> cityMap = CityCache.getInstance().getCityMap();
// 通过SHA获取到缓存实体,该实体的三字码与SHA相同
City city1 = cityMap.get("SHA");
assertTrue("SHA".equals(city1.getCode()));
// 业务代码直接修改缓存集合
cityMap.put("SHA", new City("BJS", 2));
// cityMap.remove("SHA");
// 再次通过SHA获取到缓存实体,该实体的三字码与SHA不相同了(非期望值)
City city2 = CityCache.getInstance().getCityMap().get("SHA");
assertFalse("SHA".equals(city2.getCode()));
}
■ 缓存实体被修改
public class CityCache {
private static final CityCache INSTANCE = new CityCache();
@Getter
private final Map<String, City> cityMap = new HashMap<>();
public static CityCache getInstance() {
return INSTANCE;
}
private CityCache() {
// // 此处为了简便,没有写定时刷新
loadDataFromDB();
}
private void loadDataFromDB() {
// load cities from database and put them into cityMap
}
}
@Data
public class City {
public City() {
}
public City(String code, int id) {
this.code = code;
this.id = id;
}
private String code;
private int id;
}
@Test
public void errorTest() {
Map<String, City> cityMap = CityCache.getInstance().getCityMap();
// 通过SHA获取到缓存实体,该实体的三字码与SHA相同
City city1 = cityMap.get("SHA");
assertTrue("SHA".equals(city1.getCode()));
// 运行期间非预期的修改了缓存集合中的对象
cityMap.forEach((k, v) -> {
if (!"SHA".equals(k)) {
return;
}
// ...
v.setCode("BJS");
});
// 再次通过SHA获取到缓存实体,该实体的三字码与SHA不相同了(非期望值)
City city2 = CityCache.getInstance().getCityMap().get("SHA");
assertFalse("SHA".equals(city2.getCode()));
}
【3】如何避免缓存篡改:
■ 在可能需要修改数据的场景,从缓存获取一个深拷贝对象/集合。
■ 将缓存对象设计为只读状态,确保一旦构建就不可再修改其内部数据。
多线程
"多线程"这个话题想必开发人员或多或少都会接触到。 使用多线程最主要的原因是提高系统的资源利用率。 但在使用的过程中可能会遇到各种各样的问题,"死循环"便是其中比较棘手的一类。 下文分析了多线程环境下的死循环场景,希望对大家有所帮助。
死循环危害
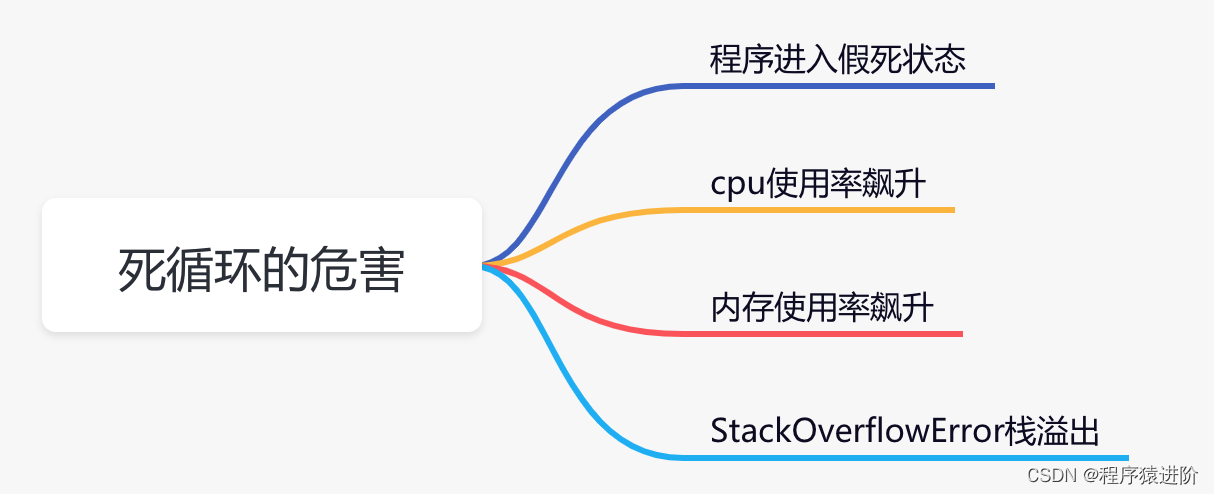
程序进入假死状态: 当某个请求导致死循环,该请求会在很大一段时间内,都无法获取接口的返回。
CPU 使用率飙升: 代码出现死循环后,由于没有休眠,一直不断抢占cpu资源,导致cpu长时间处于繁忙状态,必定会使cpu使用率飙升。
内存使用率飙升: 代码出现死循环时,循环体内有大量创建对象的逻辑,垃圾回收器无法及时回收,会导致内存使用率飙升。同时,如果垃圾回收器频繁回收对象,也会造成cpu使用率飙升。
StackOverflowError栈溢出: 在一些递归调用的场景,如果出现死循环,多次循环后,最终会报 StackOverflowError 栈溢出,程序直接挂掉。
案例一:多线程环境下的死循环案例
问题: 循环条件不正确
案例: 这里以二分查找为例
int search(List<Integer> nums, int target) {
int l = 0, r = nums.size() - 1;
while (l < r) {
int mid = (l + r) / 2;
if (nums.get(mid) > target)
r = mid - 1;
else
// 可能出问题位置
l = mid;
}
if (nums.get(l) == target)
return l;
else
return -1;
}
首先,会不会产生死循环的关键是l和r是否在每次循环后至少有一个的值发生了改变, 而while循环体中,若走入了else语句,l的值有可能不发生变化,就会导致死循环的产生。 可以对循环体做以下调整:
while (l < r) {
int mid = (l + r) / 2;
if (nums.get(mid) >= target)
r = mid;
else
l = mid + 1;
}
案例二:flag 线程间不可见
有时候我们的代码需要一直做某件事情,直到某个条件达到,有个状态告诉它,要终止任务了,它就会自动退出。 这时候,很多人都会想到用while(flag)实现这个功能:
public class FlagTest {
private boolean flag = true;
public void setFlag(boolean flag) {
this.flag = flag;
}
public void fun() {
while (flag) {
}
System.out.println("done");
}
public static void main(String[] args) throws InterruptedException {
final FlagTest flagTest = new FlagTest();
new Thread(() -> flagTest.fun()).start();
Thread.sleep(200);
flagTest.setFlag(false);
}
}
这段代码在子线程中执行无限循环,当主线程休眠200毫秒后,将flag变成false,这时子线程就会自动退出了。想法是好的,但是实际上这段代码进入了死循环,不会因为flag变成false而自动退出。 为什么会这样? 线程间flag是不可见的,这时如果flag加上了volatile关键字,变成:
private volatile boolean flag = true;
会强制把共享内存中的值刷新到主内存中,让多个线程间可见,程序可以正常退出。
案例三:HashMap JDK7/8 死循环
问题: JDK7 rehash(扩容)时和JDK8链表更改为红黑树时。链接
案例四:自己手动写死循环
定时任务比如有个需求要求每隔5分钟,从远程拉取数据,覆盖本地数据。 这时候,如果你不想用其他的定时任务框架,可以实现一个简单的定时任务,具体代码如下:
public static void sync() {
new Thread(() -> {
while (true) {
try {
System.out.println("sync data");
Thread.sleep(1000 * 60 * 5);
} catch (Exception e) {
log.error(e);
}
}
}).start();
}
其实很多JDK中的定时任务,比如:Timer类的底层,也是用了while(true)的无限循环(也就是死循环)来实现的。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pixels:重新定义游戏体验的区块链农场游戏
- Spring基于注解的IOC配置
- 总线协议:GPIO模拟SMI(MDIO)协议(2):SMI协议软件实现
- 怎么把workspace的数据导入到simulink查看波形?
- nodejs前端项目的CI/CD实现(四)前端项目的CD持续部署
- WT588F02B-8S语音芯片:灵活应用的语音播放利器,实现多重优势
- 深度学习seed()函数随机种子详解
- 检查一个Java List是否包含某个JavaBean对象的特定值,并且获取这个值
- 如何做好一个信息系统项目经理,一个项目经理的个人体会和经验总结(三)
- 【PostgreSQL】从零开始:(三十五)数据类型-pg_lsn类型