人体关键点检测3:Android实现人体关键点检测(人体姿势估计)含源码 可实时检测
目录
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
1. 前言
人体关键点检测(Human Keypoints Detection)又称为人体姿态估计2D Pose,是计算机视觉中一个相对基础的任务,是人体动作识别、行为分析、人机交互等的前置任务。一般情况下可以将人体关键点检测细分为单人/多人关键点检测、2D/3D关键点检测,同时有算法在完成关键点检测之后还会进行关键点的跟踪,也被称为人体姿态跟踪。
项目将实现人体关键点检测算法,其中使用YOLOv5模型实现人体检测(Person Detection),使用HRNet,LiteHRNet和Mobilenet-v2模型实现人体关键点检测。为了方便后续模型工程化和Android平台部署,项目支持高精度HRNet检测模型,轻量化模型LiteHRNet和Mobilenet模型训练和测试,并提供Python/C++/Android多个版本;项目分为数据集说明,模型训练和C++/Android部署等多个章节,本篇是项目《人体关键点检测(人体姿势估计)》系列文章之Android实现人体关键点检测,主要分享将Python训练好的模型移植到Android平台,搭建一个可实时的人体关键点检测Android Demo,且支持多人关键点检测。

轻量化Mobilenet-v2模型在普通Android手机上可以达到实时的检测效果,CPU(4线程)约50ms左右,GPU约30ms左右 ,基本满足业务的性能需求。下表格给出HRNet,以及轻量化模型LiteHRNet和Mobilenet的计算量和参数量,以及其检测精度。
| 模型 | input-size | params(M) | GFLOPs | AP |
| HRNet-w32 | 192×256 | 28.48M | 5734.05M | 0.7585 |
| LiteHRNet18 | 192×256 | 1.10M | 182.15M | 0.6237 |
| Mobilenet-v2 | 192×256 | 2.63M | 529.25M | 0.6181 |
【尊重原创,转载请注明出处】?https://blog.csdn.net/guyuealian/article/details/134881797
Android人体关键点检测APP Demo体验(下载):https://download.csdn.net/download/guyuealian/88610359
Android人体关键点检测APP Demo体验
 ??
??
更多项目《人体关键点检测(人体姿势估计)》系列文章请参考:
- 人体关键点检测1:人体姿势估计数据集(含下载链接)?https://blog.csdn.net/guyuealian/article/details/134703548
- 人体关键点检测2:Pytorch实现人体关键点检测(人体姿势估计)含训练代码和数据集?https://blog.csdn.net/guyuealian/article/details/134837816
- 人体关键点检测3:Android实现人体关键点检测(人体姿势估计)含源码 可实时检测?https://blog.csdn.net/guyuealian/article/details/134881797
- 人体关键点检测4:C/C++实现人体关键点检测(人体姿势估计)含源码 可实时检测?https://blog.csdn.net/guyuealian/article/details/134881797
- 手部关键点检测1:手部关键点(手部姿势估计)数据集(含下载链接)https://blog.csdn.net/guyuealian/article/details/133277630
- 手部关键点检测2:YOLOv5实现手部检测(含训练代码和数据集)https://blog.csdn.net/guyuealian/article/details/133279222
- 手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集https://blog.csdn.net/guyuealian/article/details/133277726
- 手部关键点检测4:Android实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133931698
- 手部关键点检测5:C++实现手部关键点检测(手部姿势估计)含源码 可实时检测https://blog.csdn.net/guyuealian/article/details/133277748

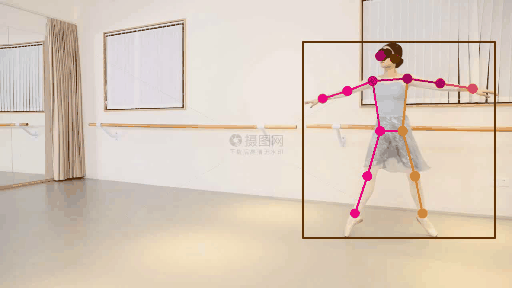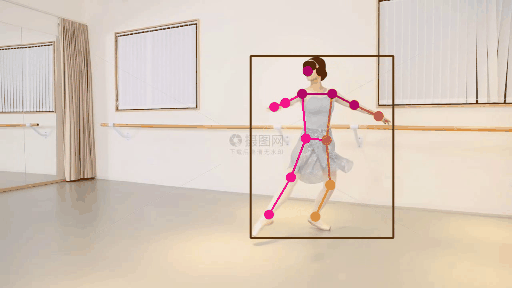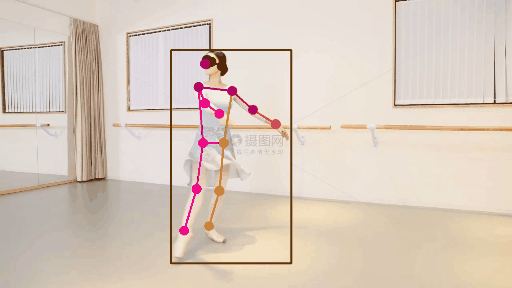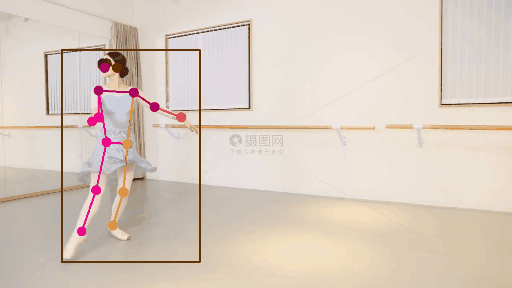
2.人体关键点检测方法
目前主流的人体关键点检测(人体姿势估计)方法主要两种:一种是Top-Down(自上而下)方法,另外一种是Bottom-Up(自下而上)方法;
(1)Top-Down(自上而下)方法
将人体检测和人体关键点检测(人体姿势估计)检测分离,在图像上首先进行人体目标检测,定位人体位置;然后crop每一个人体图像,再估计人体关键点;这类方法往往比较慢,但姿态估计准确度较高。目前主流模型主要有CPN,Hourglass,CPM,Alpha Pose,HRNet等。
(2)Bottom-Up(自下而上)方法:
先估计图像中所有人体关键点,然后在通过Grouping的方法组合成一个一个实例;因此这类方法在测试推断的时候往往更快速,准确度稍低。典型就是COCO2016年人体关键点检测冠军Open Pose。
通常来说,Top-Down具有更高的精度,而Bottom-Up具有更快的速度;就目前调研而言,?Top-Down的方法研究较多,精度也比Bottom-Up(自下而上)方法高。本项目采用Top-Down(自上而下)方法,先使用YOLOv5模型实现人体检测,然后再使用HRNet进行人体关键点检测(人体姿势估计);
本项目基于开源的HRNet进行改进,关于HRNet项目请参考GitHub
HRNet: https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
3.人体关键点检测模型训练
本项目采用Top-Down(自上而下)方法,使用YOLOv5模型实现人体检测,并基于开源的HRNet实现人体关键点检测(人体姿态估计);为了方便后续模型工程化和Android平台部署,项目支持轻量化模型LiteHRNet和Mobilenet模型训练和测试,并提供Python/C++/Android多个版本;轻量化Mobilenet-v2模型在普通Android手机上可以达到实时的检测效果,CPU(4线程)约50ms左右,GPU约30ms左右 ,基本满足业务的性能需求
本篇博文主要分享Android版本的模型部署,不包含Python版本的训练代码和相关数据集,关于人体关键点检测的训练方法和数据集说明,可参考 :?
人体关键点检测2:Pytorch实现人体关键点检测(人体姿势估计)含训练代码和数据集?https://blog.csdn.net/guyuealian/article/details/134837816
下表格给出HRNet,以及轻量化模型LiteHRNet和Mobilenet的计算量和参数量,以及其检测精度AP; 高精度检测模型HRNet-w32,AP可以达到0.7585,但其参数量和计算量比较大,不合适在移动端部署;LiteHRNet18和Mobilenet-v2参数量和计算量比较少,合适在移动端部署;虽然LiteHRNet18的理论计算量和参数量比Mobilenet-v2低,但在实际测试中,发现Mobilenet-v2运行速度更快。轻量化Mobilenet-v2模型在普通Android手机上可以达到实时的检测效果,CPU(4线程)约50ms左右,GPU约30ms左右 ,基本满足业务的性能需求
| 模型 | input-size | params(M) | GFLOPs | AP |
| HRNet-w32 | 192×256 | 28.48M | 5734.05M | 0.7585 |
| LiteHRNet18 | 192×256 | 1.10M | 182.15M | 0.6237 |
| Mobilenet-v2 | 192×256 | 2.63M | 529.25M | 0.6181 |
HRNet-w32参数量和计算量太大,不适合在Android手机部署,本项目Android版本只支持部署LiteHRNet和Mobilenet-v2模型;C++版本可支持部署HRNet-w32,LiteHRNet和Mobilenet-v2模型?
4.人体关键点检测模型Android部署
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署。部署流程可分为四步:训练模型->将模型转换ONNX模型->将ONNX模型转换为TNN模型->Android端上部署TNN模型。
(1) 将Pytorch模型转换ONNX模型
训练好Pytorch模型后,我们需要先将模型转换为ONNX模型,以便后续模型部署。
- 原始Python项目提供转换脚本,你只需要修改model_file和config_file为你模型路径即可
- ?convert_torch_to_onnx.py实现将Pytorch模型转换ONNX模型的脚本
python libs/convert_tools/convert_torch_to_onnx.py"""
This code is used to convert the pytorch model into an onnx format model.
"""
import os
import torch.onnx
from pose.inference import PoseEstimation
from basetrainer.utils.converter import pytorch2onnx
def load_model(config_file, model_file, device="cuda:0"):
pose = PoseEstimation(config_file, model_file, device=device)
model = pose.model
config = pose.config
return model, config
def convert2onnx(config_file, model_file, device="cuda:0", onnx_type="kp"):
"""
:param model_file:
:param input_size:
:param device:
:param onnx_type:
:return:
"""
model, config = load_model(config_file, model_file, device=device)
model = model.to(device)
model.eval()
model_name = os.path.basename(model_file)[:-len(".pth")]
onnx_file = os.path.join(os.path.dirname(model_file), model_name + ".onnx")
# dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
input_size = tuple(config.MODEL.IMAGE_SIZE) # w,h
input_shape = (1, 3, input_size[1], input_size[0])
pytorch2onnx.convert2onnx(model,
input_shape=input_shape,
input_names=['input'],
output_names=['output'],
onnx_file=onnx_file,
opset_version=11)
print(input_shape)
if __name__ == "__main__":
config_file = "../../work_space/person/mobilenet_v2_17_192_256_custom_coco_20231124_090015_6639/mobilenetv2_192_192.yaml"
model_file = "../../work_space/person/mobilenet_v2_17_192_256_custom_coco_20231124_090015_6639/model/best_model_158_0.6181.pth"
convert2onnx(config_file, model_file)
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署
TNN转换工具:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine? ?(可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)
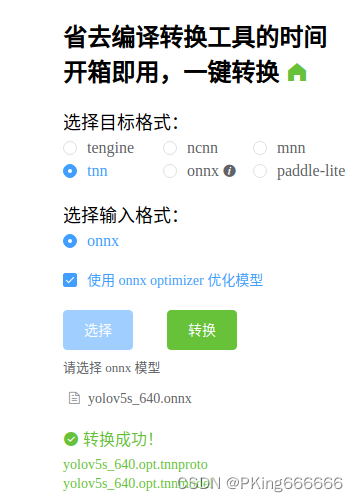 ??
??
(3) Android端上部署模型
项目实现了Android版本的人体检测和人体关键点检测Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。项目Android源码,核心算法均采用C++实现,上层通过JNI接口调用。
如果你想在这个Android Demo部署你自己训练的模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。?
HRNet-w32参数量和计算量太大,不适合在Android手机部署,本项目Android版本只支持部署LiteHRNet和Mobilenet-v2模型;C++版本可支持部署HRNet-w32,LiteHRNet和Mobilenet-v2模型?
- 这是项目Android源码JNI接口 ,Java部分
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector {
static {
System.loadLibrary("tnn_wrapper");
}
/***
* 初始化检测模型
* @param dets_model: 检测模型(不含后缀名)
* @param pose_model: 识别模型(不含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:是否开启GPU进行加速
*/
public static native void init(String dets_model, String pose_model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 返回检测和识别结果
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @param pose_thresh: 关键点阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh, float pose_thresh);
}
- 这是Android项目源码JNI接口 ,C++部分
#include <jni.h>
#include <string>
#include <fstream>
#include "src/yolov5.h"
#include "src/pose_detector.h"
#include "src/Types.h"
#include "debug.h"
#include "android_utils.h"
#include "opencv2/opencv.hpp"
#include "file_utils.h"
using namespace dl;
using namespace vision;
static YOLOv5 *detector = nullptr;
static PoseDetector *pose = nullptr;
JNIEXPORT jint JNI_OnLoad(JavaVM *vm, void *reserved) {
return JNI_VERSION_1_6;
}
JNIEXPORT void JNI_OnUnload(JavaVM *vm, void *reserved) {
}
extern "C"
JNIEXPORT void JNICALL
Java_com_cv_tnn_model_Detector_init(JNIEnv *env,
jclass clazz,
jstring dets_model,
jstring pose_model,
jstring root,
jint model_type,
jint num_thread,
jboolean use_gpu) {
if (detector != nullptr) {
delete detector;
detector = nullptr;
}
std::string parent = env->GetStringUTFChars(root, 0);
std::string dets_model_ = env->GetStringUTFChars(dets_model, 0);
std::string pose_model_ = env->GetStringUTFChars(pose_model, 0);
string dets_model_file = path_joint(parent, dets_model_ + ".tnnmodel");
string dets_proto_file = path_joint(parent, dets_model_ + ".tnnproto");
string pose_model_file = path_joint(parent, pose_model_ + ".tnnmodel");
string pose_proto_file = path_joint(parent, pose_model_ + ".tnnproto");
DeviceType device = use_gpu ? GPU : CPU;
LOGW("parent : %s", parent.c_str());
LOGW("useGPU : %d", use_gpu);
LOGW("device_type: %d", device);
LOGW("model_type : %d", model_type);
LOGW("num_thread : %d", num_thread);
YOLOv5Param model_param = YOLOv5s05_320;//模型参数
detector = new YOLOv5(dets_model_file,
dets_proto_file,
model_param,
num_thread,
device);
PoseParam pose_param = POSE_MODEL_TYPE[model_type];//模型类型
pose = new PoseDetector(pose_model_file,
pose_proto_file,
pose_param,
num_thread,
device);
}
extern "C"
JNIEXPORT jobjectArray JNICALL
Java_com_cv_tnn_model_Detector_detect(JNIEnv *env, jclass clazz, jobject bitmap,
jfloat score_thresh, jfloat iou_thresh, jfloat pose_thresh) {
cv::Mat bgr;
BitmapToMatrix(env, bitmap, bgr);
int src_h = bgr.rows;
int src_w = bgr.cols;
// 检测区域为整张图片的大小
FrameInfo resultInfo;
// 开始检测
if (detector != nullptr) {
detector->detect(bgr, &resultInfo, score_thresh, iou_thresh);
} else {
ObjectInfo objectInfo;
objectInfo.x1 = 0;
objectInfo.y1 = 0;
objectInfo.x2 = (float) src_w;
objectInfo.y2 = (float) src_h;
objectInfo.label = 0;
resultInfo.info.push_back(objectInfo);
}
int nums = resultInfo.info.size();
LOGW("object nums: %d\n", nums);
if (nums > 0) {
// 开始检测
pose->detect(bgr, &resultInfo, pose_thresh);
// 可视化代码
//classifier->visualizeResult(bgr, &resultInfo);
}
//cv::cvtColor(bgr, bgr, cv::COLOR_BGR2RGB);
//MatrixToBitmap(env, bgr, dst_bitmap);
auto BoxInfo = env->FindClass("com/cv/tnn/model/FrameInfo");
auto init_id = env->GetMethodID(BoxInfo, "<init>", "()V");
auto box_id = env->GetMethodID(BoxInfo, "addBox", "(FFFFIF)V");
auto ky_id = env->GetMethodID(BoxInfo, "addKeyPoint", "(FFF)V");
jobjectArray ret = env->NewObjectArray(resultInfo.info.size(), BoxInfo, nullptr);
for (int i = 0; i < nums; ++i) {
auto info = resultInfo.info[i];
env->PushLocalFrame(1);
//jobject obj = env->AllocObject(BoxInfo);
jobject obj = env->NewObject(BoxInfo, init_id);
// set bbox
//LOGW("rect:[%f,%f,%f,%f] label:%d,score:%f \n", info.rect.x,info.rect.y, info.rect.w, info.rect.h, 0, 1.0f);
env->CallVoidMethod(obj, box_id, info.x1, info.y1, info.x2 - info.x1, info.y2 - info.y1,
info.label, info.score);
// set keypoint
for (const auto &kps : info.keypoints) {
//LOGW("point:[%f,%f] score:%f \n", lm.point.x, lm.point.y, lm.score);
env->CallVoidMethod(obj, ky_id, (float) kps.point.x, (float) kps.point.y,
(float) kps.score);
}
obj = env->PopLocalFrame(obj);
env->SetObjectArrayElement(ret, i, obj);
}
return ret;
}
(4) Android测试效果?
Android Demo在普通手机CPU/GPU上可以达到实时检测效果;CPU(4线程)约50ms左右,GPU约30ms左右 ,基本满足业务的性能需求。
Android版本的人体关键点检测APP Demo体验:
Android人体关键点检测APP Demo体验(下载):
https://download.csdn.net/download/guyuealian/88610359
???
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:
解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
?Android SDK和NDK相关版本信息,请参考:?
 ?
?
5.Android项目源码下载
Android项目源码下载地址:Android实现人体关键点检测(人体姿势估计)含源码 可实时检测
Android人体关键点检测APP Demo体验(下载):https://download.csdn.net/download/guyuealian/88610359
整套Android项目源码内容包含:
- Android Demo源码支持YOLOv5人体检测
- Android Demo源码支持轻量化模型LiteHRNet和Mobilenet-v2人体关键点检测(人体姿态估计)
- Android Demo在普通手机CPU/GPU上可以实时检测,CPU约50ms,GPU约30ms左右
- Android Demo支持图片,视频,摄像头测试
- 所有依赖库都已经配置好,可直接build运行,若运行出现闪退,请参考dlopen failed: library “libomp.so“ not found?解决。
6.C++实现人体关键点检测
- ?人体关键点检测4:C/C++实现人体关键点检测(人体姿势估计)含源码 可实时检测?https://blog.csdn.net/guyuealian/article/details/134881797
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mybatis查询日期格式
- Facebook企业户与个人户的区别是什么?一文带你看懂Facebook企业户!
- MySQL函数—字符串函数
- 如何防止你的 Goroutine 泄露 Part2
- JMeter做http接口功能测试
- DoIP学习笔记系列:(七)doipclient测试工具安装使用说明
- 双证博士|英国斯特灵大学管理学院国际事务副院长教授来社科大开展学术讲座
- 书生·浦语大模型全链路开源开放体系
- Spring事件监听机制
- 思迈特2023 年度回顾:这一年,在不确定的时代里做好正确的事