大数据开发之Hadoop(优化&新特征)
第 1 章:HDFS-故障排除
注意:采用三台服务器即可,恢复到Yarn开始的服务器快照。
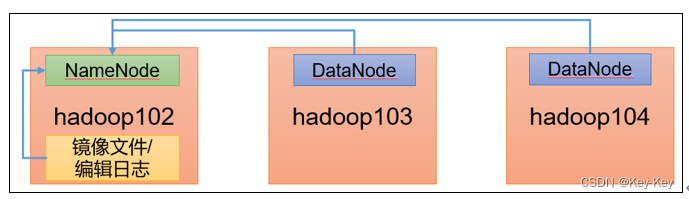
1.1 集群安全模块
1、安全模式:文件系统只接收读数据请求,而不接收删除、修改等变更请求
2、进入安全模式场景
1)NameNode在加载镜像文件和编辑日志期间处于安全模式
2)NameNode再接收DataNode注册时,处于安全模式
3)退出安全模式条件
dfs.namenode.safemode.min.datanodes:最小可用datanode数量,默认0
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的block占系统总block数的百分比,默认0.999f
dfs.namenode.safemode.extension:稳定时间,默认30000毫秒,即30秒
4)基本语法
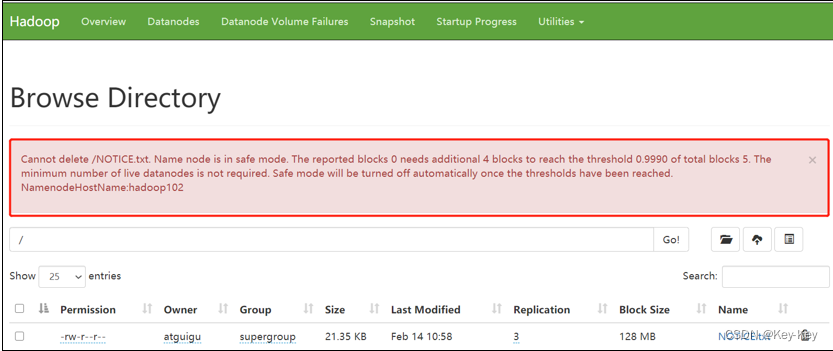
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
1.2 NameNode故障处理
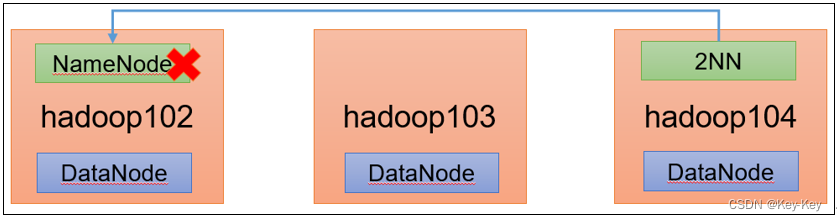
1、需求:
NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode
2、故障模拟
1)kill -9 NameNode进程
[atguigu@hadoop102 current]$ kill -9 NameNode的进程号
2)删除NameNode存储的数据
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*
3、问题解决
1)拷贝SecondaryNameNode中数据到原NameNode存储数据据目录
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./name/
2)重新启动NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode
3)向集群上传一个文件
1.3 磁盘修复
案例1:启动集群进入安全模式
1、重新启动集群
[atguigu@hadoop102 subdir0]$ myhadoop.sh stop
[atguigu@hadoop102 subdir0]$ myhadoop.sh start
2、集群启动后,立即来到集群上删除数据,提示集群处理安全模式
案例2:磁盘修复
需求:数据库损失,进入安全模式,如何处理
1、分别进入hadoop102、103、104的/opt/module/hadoop-3.1.3/data/dfs/data/current/BP~/subdir0目录,统一删除某2个块信息
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1015489500-192.168.10.102-1611909480872/current/finalized/subdir0/subdir0
[atguigu@hadoop102 subdir0]$ rm -rf blk_1073741847 blk_1073741847_1023.meta
[atguigu@hadoop102 subdir0]$ rm -rf blk_1073741865 blk_1073741865_1042.meta
说明:hadoop103/hadoop104重复执行以上命令
2、重新启动集群
[atguigu@hadoop102 subdir0]$ myhadoop.sh stop
[atguigu@hadoop102 subdir0]$ myhadoop.sh start
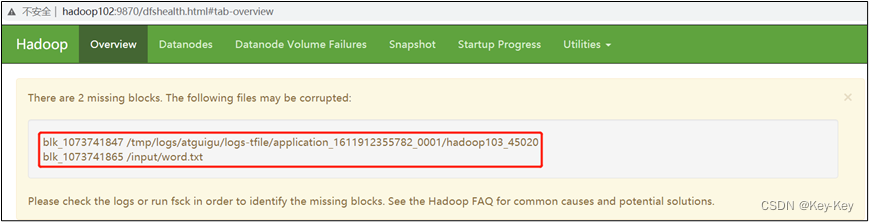
3、观察http://hadoop102:9870/dfshealth.html#tab-overview

说明:安全模式已经打开,块的数量没有达到要求
4、离开安全模式
[atguigu@hadoop102 subdir0]$ hdfs dfsadmin -safemode get
Safe mode is ON
[atguigu@hadoop102 subdir0]$ hdfs dfsadmin -safemode leave
Safe mode is OFF
5、观察http://hadoop102:9870/dfshealth.html#tab-overview
6、将元数据删除
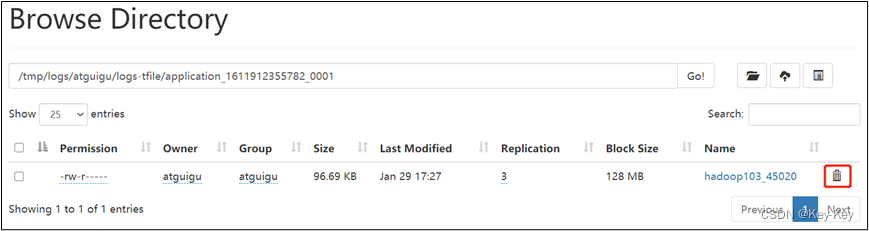
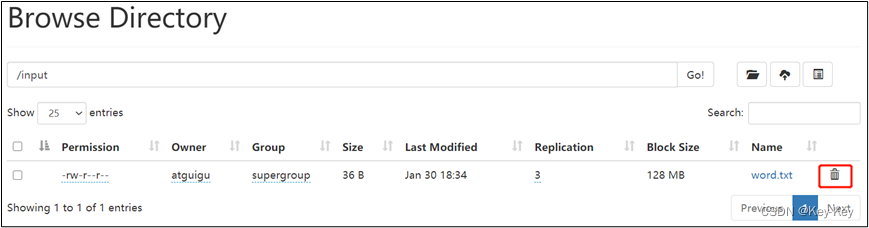
7、观察http://hadoop102:9870/dfshealth.html#tab-overview,集群已经正常
案例3:
需求:模拟等待安全模式
1、查看当前模式
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -safemode get
Safe mode is OFF
2、先进入安全模式
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode enter
3、创建并执行下面的脚本
在opt/module/hadoop-3.1.3路径上,编辑一个脚本safemode.sh
[atguigu@hadoop102 hadoop-3.1.3]$ vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
[atguigu@hadoop102 hadoop-3.1.3]$ chmod 777 safemode.sh
[atguigu@hadoop102 hadoop-3.1.3]$ ./safemode.sh
4、再打开一个窗口,执行
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode leave
5、再观察上一个窗口
Safe mode is OFF
6、HDFS集群上已经有上传的数据了

第 2 章:HDFS-多目录
2.1 DataNode多目录配置
1、DataNode可用配置成多个目录,每个目录存储的数据不一样(数据不是副本)

2、具体配置如下:
在hdfs-site.xml文件中添加如下内容:
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
3、查看结果
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data1
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data2
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2
4、向集群上传一个文件,再次观察两个文件夹里面的内容发现不一致(一个有数一个没数)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /
2.2 集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可用执行磁盘均衡命令。

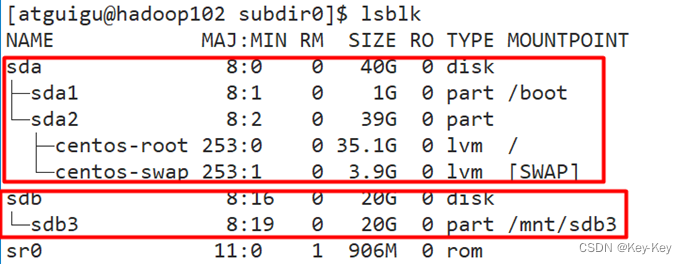
1、生产均衡计划(只有一块磁盘,不会生成计划)

2、执行均衡计划
hdfs diskbalancer -execute hadoop102.plan.json
3、查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
4、取消均衡任务
hdfs diskbalancer -cancel hadoop102.plan.json
第 3 章:HDFS-集群扩容及缩容
3.1 服役新服务器
1、需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点
2、环境准备
1)在hadoop100主机上再克隆一台hadoop105主机
2)修改IP地址和主机名称
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop105 ~]# vim /etc/hostname
3)拷贝hadoop102的/opt/module目录和/etc/profile.d/my_env.sh到hadoop105
[atguigu@hadoop102 opt]$ scp -r module/* atguigu@hadoop105:/opt/module/
[atguigu@hadoop102 opt]$ sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/my_env.sh
[atguigu@hadoop105 hadoop-3.1.3]$ source /etc/profile
4)删除hadoop105上Hadoop的历史数据,data和log数据
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
5)配置hadoop102和hadoop103到hadoop105的ssh无密登录
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop105
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop105
3、服役新节点具体步骤
1)直接启动DataNode,即可关联到集群
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
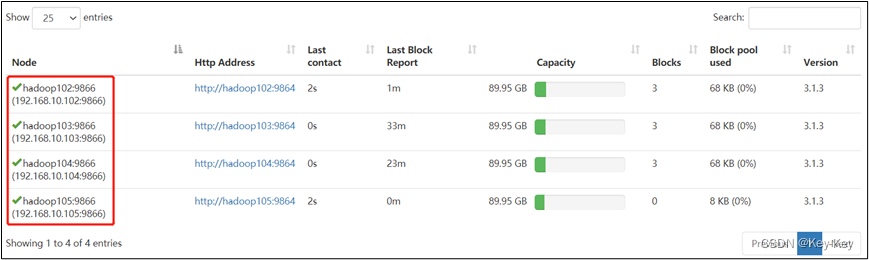
4、在白名单中增加新服役的服务器
1)在白名单whitelist中增加hadoop104、105,并重启集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改如下内容:
hadoop102
hadoop103
hadoop104
hadoop105
2)分发
[atguigu@hadoop102 hadoop]$ xsync whitelist
3)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
5、在hadoop105上上传文件
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /
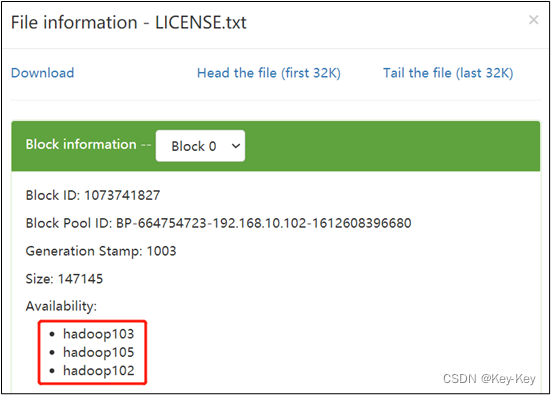
思考:如果数据不均衡(hadoop105数据少,其它节点数据多),怎么处理?
3.2 服务器间数据均衡
1、企业经验:
在企业开发中,如果经常在hadoop102和hadoop104上提交任务,且副本数为2,由于数据本地性原则,就会导致102和104数据过多,103存储的数据量小。
另一种情况,就是新服役的服务器数据量比较少,需要执行集群均衡命令。
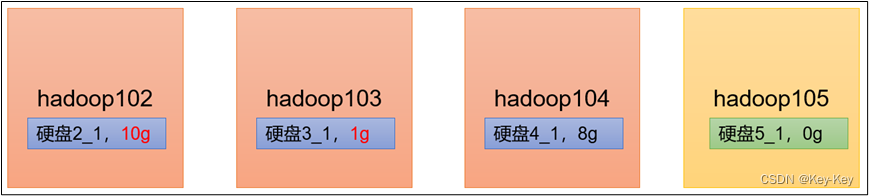
2、开启数据均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
3、停止数据均衡命令
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以经量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
3.3 添加白名单
白名单:表示在白名单的主机IP地址可用,用来存储数据。
企业中:配置白名单,可用尽量防止黑客恶意访问攻击。
配置白名单步骤如下:
1、在NameNode节点的/opt/~/hadoop目录下创建whitelist和blacklist文件
1)创建白名单
[atguigu@hadoop102 hadoop]$ vim whitelist
在whitelist中添加如下主机名称,加入集群正常工作的节点为102 103
hadoop102
hadoop103
2)创建黑名单
[atguigu@hadoop102 hadoop]$ touch blacklist
保持空的就可用
2、在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
3、分发配置文件whitelist、hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4、第一次添加白名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
5、在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode
6、二次修改白名单,增加hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop105
7、刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
8、在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode
3.4 黑名单退役服务器
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据
企业中:配置黑名单,用来退役服务器
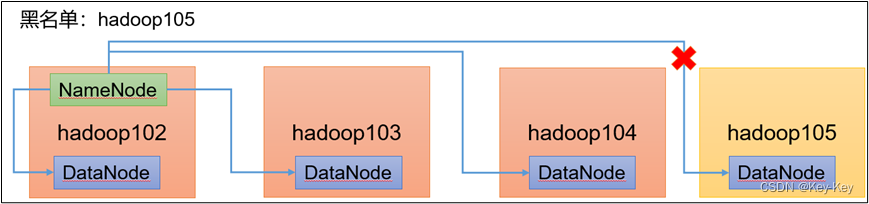
黑名单配置步骤如下:
1、编辑/opt/module/had~/hadoop目录下的blacklist文件
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop105
注意:如果白名单中没有配置,需要在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
2、分发配置文件blacklist,hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3、第一次添加黑名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
4、检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其它节点


5、等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役

[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
stopping nodemanager
6、如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
第 4 章:Hadoop企业优化
4.1 MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
4.1.1 数据输入
1、合并小文件:在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢。
2、采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
4.1.2 Map阶段
1、减少溢出(Spill)次数:通过调整mapreduce.task.io.sort.mb及mapreduce.map.sort.spill.percent参数值,增大触发Spill的内存上限,减少Spill次数,从而减少IO。
2、减少合并(Merge)次数:通过调整mapreduce.task.io.sort.factor参数,增大Merge的文件数目,减少Merge的次数,从而缩短MR处理时间。
3、在Map之后,不影响业务逻辑前提下,先进行Combine处理,减少I/O。
4.1.3 Reduce阶段
1、合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致Map、Reduce任务间竞争资源,造成处理超时等错误。
2、设置Map、Reduce共存:
调整mapreduce.job.reduce.slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
3、规避使用Reduce:因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
4、合理设置Reduce端的Buffer:默认情况下,数据达到一个阈值的时候,Buffer中的数据就会写入磁盘,然后Reduce会从磁盘中获得所有的数据。也就是说,Buffer和Reduce是没有直接关联的,中间多次写磁盘-》读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得Buffer中的一部分数据直接输送到Reducec,从而减少IO开销:mapreduce.reduce.input.buffer.percent,默认为0.0。当值大于0的时候,会保留指定比例的内存读Buffer中的数据直接拿给Reduce使用。这样一来,设置Buffer需要内存,读取数据需要内存,Reduce计算也要内存,所以要根据作业的运行情况进行调整。
4.1.4 I/O传输
1、采用数据压缩的方式,减少网络IO的时间。安装Snappy和LZO压缩编码器。
2、使用SequenceFile二进制文件。
4.1.5 数据倾斜问题
1、数据倾斜现象
数据频率倾斜-某一个区域的数据量要远远大于其它区域
数据大小倾斜-部分记录的大小远远大于平均值
2、减少数据倾斜的方法
方法1:抽样和范围分区
可以通过对原始数据进行抽样得到的结果集来预设分区边界值。
方法2:自定义分区
基于输出键的背景知识进行自定义分区。例如,如果Map输出键的单词来源于一本书。且其中某几个专业词汇较多。那么就可以自定义分区将这些专业词汇发送给固定的一部分Reduce实例。而将其它的都发送给剩余的Reduce实例。
方法3:Combiner
使用Combiner可以大量地减少数据倾斜。在可能地情况下,Combine的目的就是聚合并精简数据。
方法4:采用Map Join,尽量避免Reduce Join。
4.2 常用的调优参数
1、资源相关参数
1)以下参数是在用户自己的MR应用程序徐中配置就可以生效(mapred-default.xml)

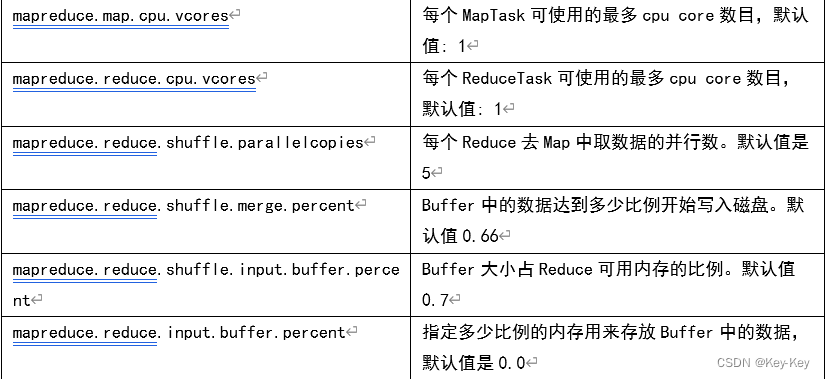
2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
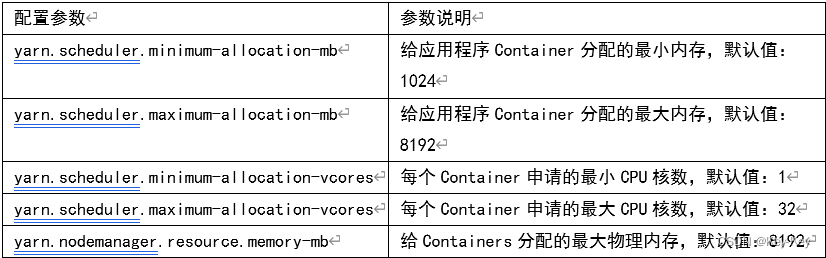
3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)

2、容错相关参数(MapReduce性能优化)

4.4 Hadoop小文件优化方法
4.4.1 Hadoop小文件弊端
HDFS上每个文件都要在NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的MapTask。每个MapTask处理的数据量小,导致MapTask的处理时间比启动时间还小,白白浪费资源。
4.4.2 Hadoop小文件解决方案
1、小文件优化的方向:
1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
4)开启uber模式,实现jvm重用。
2、Hadoop Archive
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将小文件打包成一个HAR文件,从而达到减少NameNode的内存使用。
3、CombineTextInputFormat
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
4、开启uber模式,实现JVM重用。
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。
开启uber模式,在mapred-site.xml中添加如下配置:
<!-- 开启uber模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>
第 5 章:Hadoop扩展
5.1 集群间数据拷贝
1、scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
2、采用distcp命令实现两个Hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:8020/user/atguigu/hello.txt hdfs://hadoop105:8020/user/atguigu/hello.txt
5.2 小文件存档
1、HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会消耗NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据库的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2、解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体来说,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
1、实例
1)需要启动YARN进程
[atguigu@hadoop102 hadoop-3.1.3]$ start-yarn.sh
2)归档文件
把/user/atguigu/input目录里面的所有文件归档成一个交input.har的归档文件,并把归档后文件存储到/user/atguigu/output路径下
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /user/atguigu/input /user/atguigu/output
3)查看归档
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///user/atguigu/output/input.har
4)解归档文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu
5.3 回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
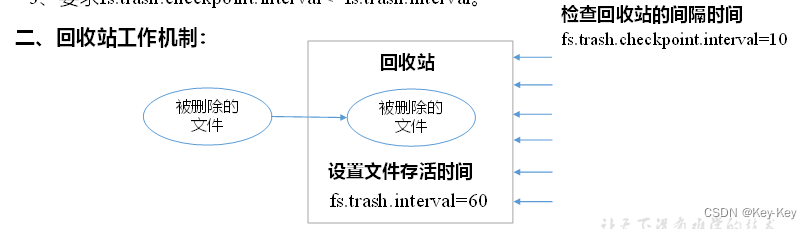
1、回收站参数设置及工作机制
1)开启回收站功能参数说明
(1)默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间
(2)默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相同。
(3)要求fs.trash.checkpoint.interval<=fs.trash.interval。
2、启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
3、查看回收站
回收站目录在hdfs集群的路径:/user/atguigu/.Trash/…
4、通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Configuration conf = new Configuration();
//设置HDFS的地址
conf.set("fs.defaultFS","hdfs://hadoop102:8020");
//因为本地的客户端拿不到集群的配置信息 所以需要自己手动设置一下回收站
conf.set("fs.trash.interval","1");
conf.set("fs.trash.checkpoint.interval","1");
//创建一个回收站对象
Trash trash = new Trash(conf);
//将HDFS上的/input/wc.txt移动到回收站
trash.moveToTrash(new Path("/input/wc.txt"));
5、同故宫网页上直接删除的文件也不会走回收站。
6、只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/atguigu/input
7、恢复回收站数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《ORANGE’S:一个操作系统的实现》读书笔记(三十一)文件系统(六)
- Python和Java环境搭建
- 数据库编程大赛:一条SQL计算扑克牌24点
- Redis集群选举流程详解
- 搭建redis服务器
- 一文详解CRM系统多少钱一套、定价依据、成本效益
- std::bind 的实现原理
- 2024年【山东省安全员C证】考试资料及山东省安全员C证模拟考试题库
- idea 如何开启mybatis控制台SQL日志打印
- 代码随想录——链表