大模型日报-20240105
骁龙888实时运行,美团、浙大等打造全流程移动端多模态大模型MobileVLM

https://mp.weixin.qq.com/s/-KnewDBeCN7a1XPk22u9Pw
MobileVLM 是一款专为移动设备设计的快速、强大和开放的视觉语言助手。它结合了面向移动设备的架构设计和技术,包括从头开始训练的 1.4B 和 2.7B 参数的语言模型、以 CLIP 方式预训练的多模态视觉模型,以及通过投影实现的高效跨模态交互。在各种视觉语言基准测试中,MobileVLM 的性能可媲美大型模型。此外,它还在高通骁龙 888 CPU 和英伟达 Jeston Orin GPU 上展示了最快的推理速度。
高情商的NPC来了,刚伸出手,它就做好了要配合下一步动作的准备

https://mp.weixin.qq.com/s/d9c0YirPTxw9_SpmulvYrQ
在虚拟现实、增强现实、游戏和人机交互等领域,经常需要让虚拟人物和屏幕外的玩家互动。这种互动是即时的,要求虚拟人物根据操作者的动作进行动态调整。有些互动还涉及物体,比如和和虚拟人物一起搬动一把椅子,这就需要特别关注操作者手部的精确动作。智能、可交互的虚拟人物的出现,将极大地提升人类玩家与虚拟人物的社交体验,带来全新的娱乐方式。在该研究中,作者专注于人与虚拟人的互动任务,特别是涉及物体的互动任务,提出了一项名为在线全身动作反应合成的新任务。新任务将基于人类的动作生成虚拟人的反应。以往的研究主要关注人与人的互动,不考虑任务中的物体,生成的身体反应也没有手部动作。此外,以往工作也没有将任务视为在线的推理,在实际情况中虚拟人根据实施情况对下一步进行预判。
面向超长上下文,大语言模型如何优化架构,这篇综述一网打尽了
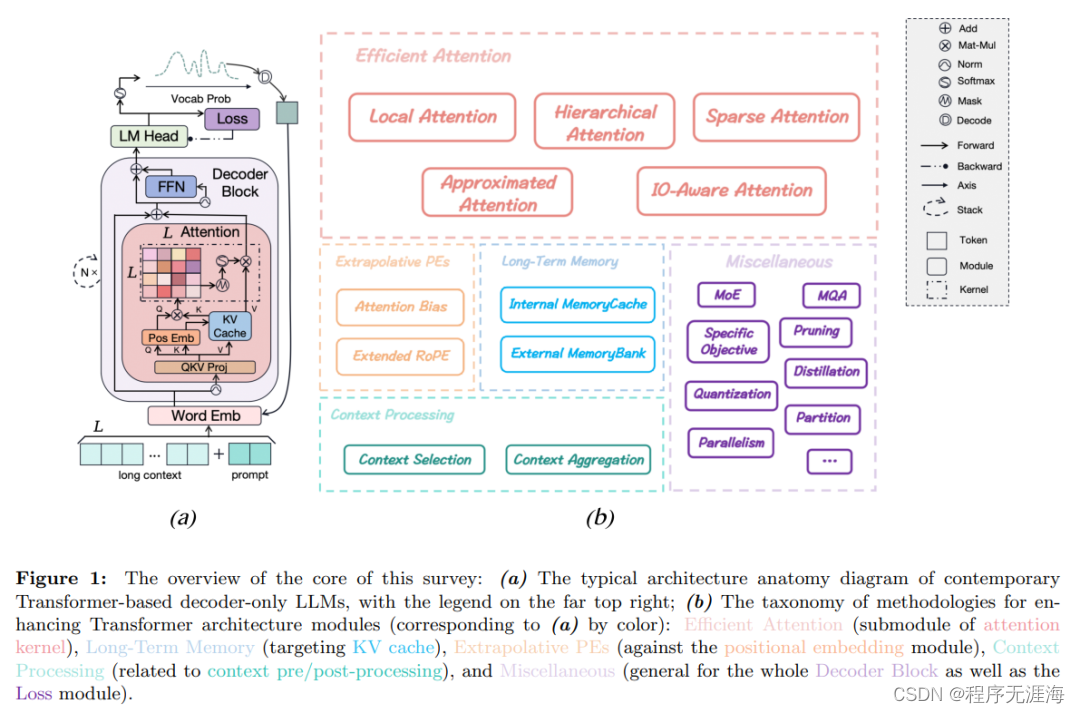
https://mp.weixin.qq.com/s/VrV3E_SKTbpjJBfFyirvhA
ChatGPT 的诞生,让基于 Transformer 的大型语言模型 (LLM) 为通用人工智能(AGI)铺开了一条革命性的道路,并在知识库、人机交互、机器人等多个领域得到应用。然而,目前存在一个普遍的限制:由于资源受限,当前大多 LLM 主要是在较短的文本上进行预训练,导致它们在较长上下文方面的表现较差,而长上下文在现实世界的环境中是更加常见的。最近的一篇综述论文对此进行了全面的调研,作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。
## 年度总结 | 2023 AI+游戏大事记

https://mp.weixin.qq.com/s/mbPYMXbv89ciKz51GvFSpw
ChatGPT发布后,AI领域的产品和科技开始快速增长。上期我们梳理了2023年这一整年内,行业技术和工具的发展迭代。今天,让我们深入探究这一年中,AI如何为游戏行业带来新的视角和体验。
消息称英伟达正开发“Skinny Joe"AI GPU: 700W TDP,特供中国

https://www.ithome.com/0/743/070.htm
根据国外科技媒体 tweaktown 报道,英伟达正开发名为“Skinny Joe"的全新 AI GPU,预估为中国特供版本.其TDP 为 700W。根据曝光的参考 Dev_ID 列表,“Skinny Joe"仅次于新款 L20 AIGPU 和英伟达 (NVIDIA)GeForce RTX 4090 D 显卡。目前尚不清楚"Skinny Joe” AI GPU 的具体规格信息,不过预估可能是 H100 或者 H200 的“瘦身"版本。
Midjourney 计划未来几个月内发布 AI视频生成模型

https://decrypt.co/211583/midjourney-leaps-into-ai-video-creation
Midiourney 是一个流行的图像生成工具,因其高质量和在 Discord 服务器内运行而闻名。该公司周二宣布,他们计划在未来几个月内推出“文本转视频"模式。Midjourney 首席执行官 David Holz 在 Discord 对话上表示该公司将从一月份开始训练其视频模型,可能会在“几个月内"准备就绪。有关该模型的更多信息并未透露。
“LLMs和编程”:当今的大多数编程工作都是在以略有不同的形式重复相同的事情,如果你在写LLM也能写出的程序,不妨再多思考一下是不是应该未来还做这样的事情

http://antirez.com/news/140
antirez从一位程序员的角度出发,讨论了自从ChatGPT和本地运行的LLMs出现后,这些新技术如何加速编程能力,并减少在编程中不值得投入精力的方面。作者通过个人经验分享,强调了自己在使用LLMs编写高级Python代码方面的增长,以及在C语言编程中较少使用LLMs的原因。
“我很遗憾地说,但这是事实:当今的大多数编程工作都是在以略有不同的形式重复相同的事情。这并不需要高水平的推理能力。大型语言模型在这方面做得相当好,尽管它们仍然受到上下文最大大小的严重限制。这确实应该让程序员思考。编写这种程序真的值得吗?当然,你能拿到报酬,而且报酬相当丰厚,但如果一个LLM可以做其中的一部分工作,那么五年或十年后这可能不是最好的位置。”
OpenVoice:仅通过一小段参考说话者的音频来复制其声音,并能用多种语言生成语音
https://x.com/reach_vb/status/1742075640990322689?s=20
OpenVoice🎙?是一种新颖的声音克隆技术,能够仅通过一小段参考说话者的音频来复制其声音,并能用多种语言生成语音。它提供了对声音风格的细致控制,包括情感、口音、节奏、停顿和语调,同时还能模仿参考说话者的音色。该技术基于训练有素的基础文本到语音(VITS)模型和音色转换器,VITS在3万个音频样本上训练,而音色转换器则在30万个样本上训练,覆盖中文、日语和英语。欢迎在Hugging Face平台上尝试这一技术👇。
QuestionImprover Agent:通过提出更好的问题来提升我们的思维方式
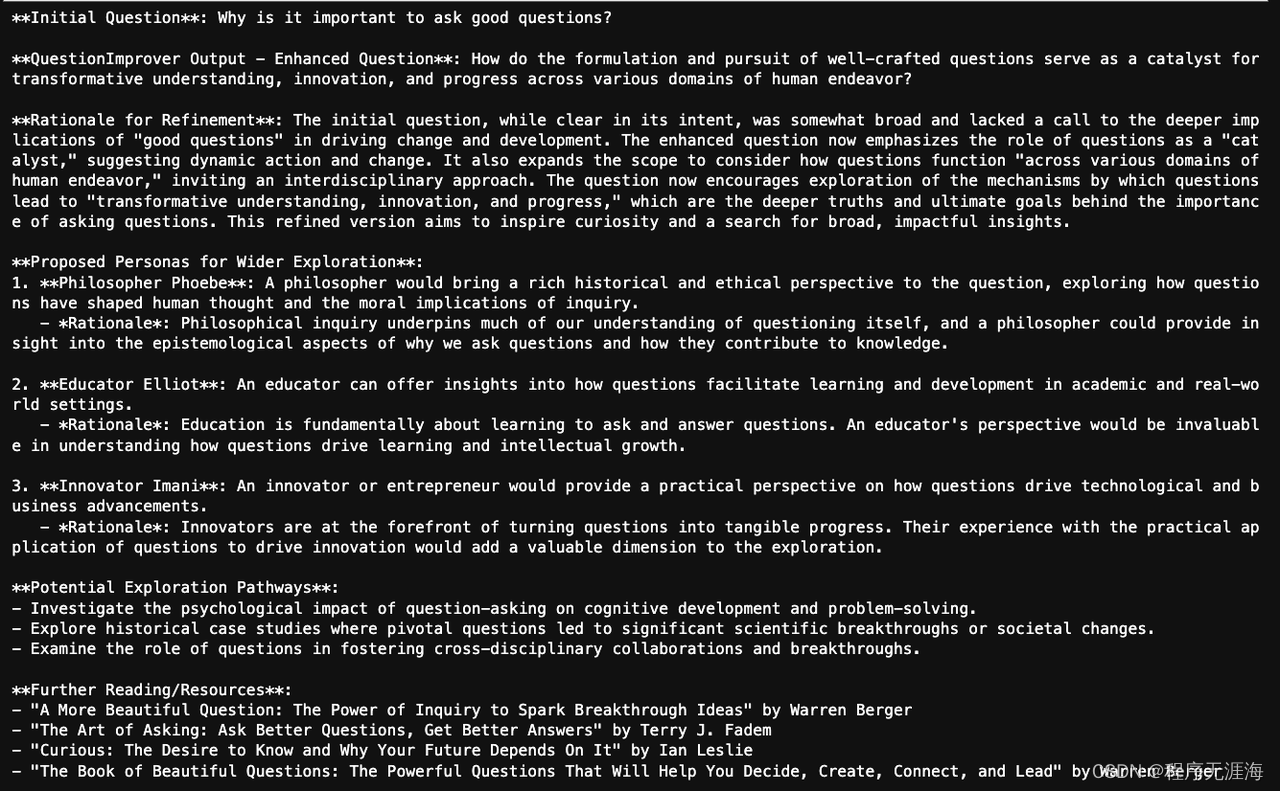
https://x.com/sockcymbal/status/1742120465110610398?s=20
QuestionImprover Agent是一个创新的AI工具,目的是在信息过载的时代,通过提出更好的问题来提升我们的思维方式。这个工具在@AGIHouseSF举办的AI for Thought Hackathon上获得了第一名,由@JvNixon, @kylejohnmorris和@Conaw共同开发。它利用一种新颖的推理算法和基于图的动态推理节奏来丰富和深化用户提出的问题,从而解锁更多洞察层次。适用于各种领域的复杂探索,如跨学科研究、战略分析或个人内省。这个项目的更广泛目标是提高提问的艺术,促进更深刻的理解和更有意义的对话。
KwaiAgents
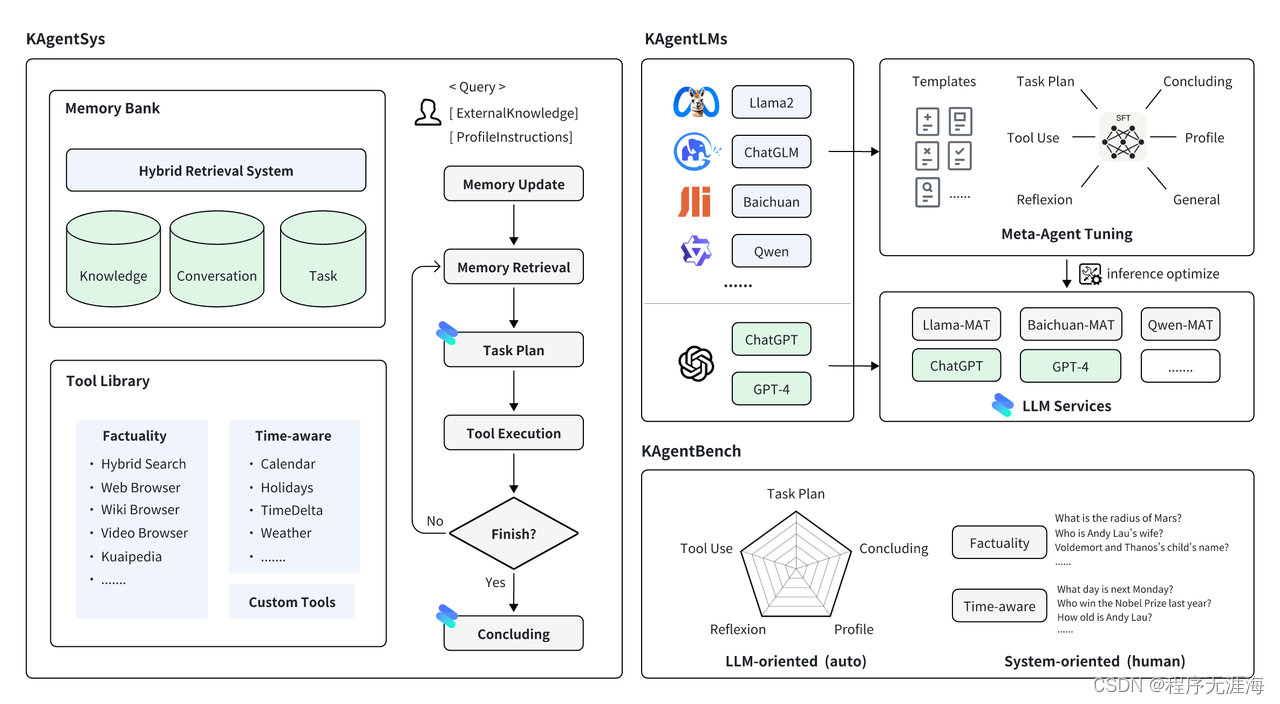
https://github.com/KwaiKEG/KwaiAgents
KwaiAgents 是快手快知团队开源的一整套Agent系列工具。论文中KAgentSys的轻量版系统,其保留了部分原系统的功能。与功能齐全的系统相比,KAgentSys-Lite(1)缺少部分工具;(2)缺乏记忆机制;(3)性能稍有降低;(4)不同的代码库,Lite版本基于开源项目如BabyAGI和Auto-GPT。尽管有这些变更,KAgentSys-Lite在众多开源Agent系统中仍具有较好的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大模型开启应用时代 数钉科技一锤定音
- 内存编织技术,JVM对内存的又一次压榨
- 【操作系统】知识点整理
- 2024年恩施中级职称申报条件是什么?
- 二叉树的直径(LeetCode 543)
- 大数据回归算法全解析:一文读懂机器学习中的回归模型
- IEEE Transactions on Industrial Electronics工业电子TIE论文投稿须知
- Mybatis xml中排序(order by)条件用#{}查询失败
- openresty介绍、安装、使用
- 【MySQL】根据某一字段累加计算出每一行数据形成新字段(累积求和)