YOLOv8算法改进【NO.99】引入最新发布Deformable Convolution v4 (DCNv4)
?前? ?言
? ? ? ?YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通:第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,不算是堆积木那种,也可以说是一种新的算法,所以做实验的话建议朋友们优先尝试这种改法。
第二,创新特征融合网络,这个同理第一,比如将原yolo算法PANet结构改进为Bifpn等。
第三,改进主干特征提取网络,就是类似加个注意力机制等。根据个人实验情况来说,这种改进有时候很难有较大的检测效果的提升,乱加反而降低了特征提取能力导致mAP下降,需要有技巧的添加。
第四,改进特征融合网络,理由、方法等同上。
第五,改进检测头,更换检测头这种也算个大的改进点。
第六,改进损失函数,nms、框等,要是有提升检测效果的话,算是一个小的改进点,也可以凑字数。
第七,对图像输入做改进,改进数据增强方法等。
第八,剪枝以及蒸馏等,这种用于特定的任务,比如轻量化检测等,但是这种会带来精度的下降。
...........未完待续
一、创新改进思路或解决的问题
强势推出 Deformable Convolution v4 (DCNv4),这是一种专为广泛的视觉应用而设计的高效且有效的动态和稀疏的算子。
二、基本原理

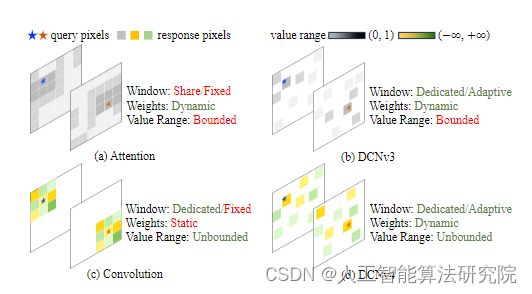
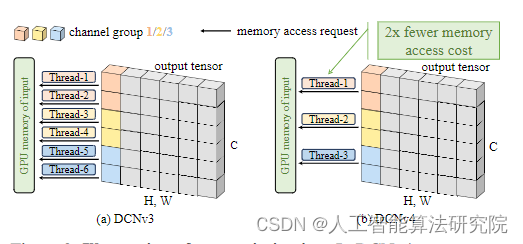
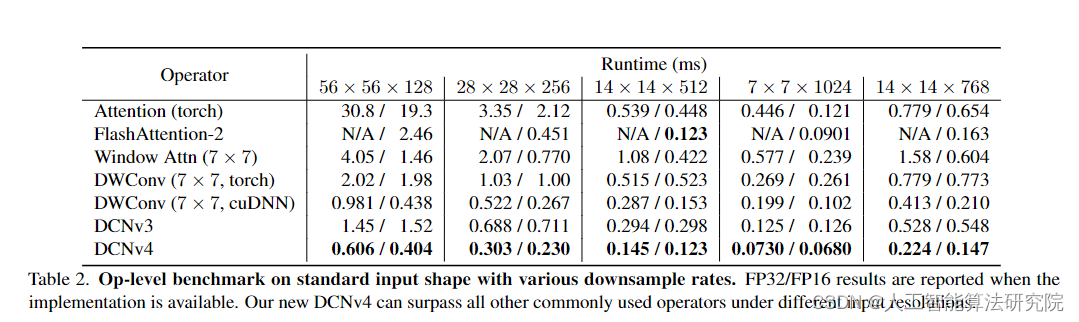
??摘要:我们介绍了可变形卷积v4(DCNv4),这是一种高效有效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:1。去除空间聚合中的softmax归一化以增强其动态特性和表达能力。优化内存访问以最大限度地减少冗余操作以加快速度。与DCNv3相比,这些改进显著加快了收敛速度,并显著提高了处理速度,其中DCNv4实现了三倍以上的正向速度。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当集成到潜在扩散模型中的U-Net等生成模型中时,DCNv4的性能优于其基线,突出了其增强生成模型的可能性。在实际应用中,将InternetImage模型中的DCNv3替换为DCNv4以创建FlashInternetImage,可以在不进行进一步修改的情况下提高高达80%的速度和进一步的性能。DCNv4在速度和效率方面的进步,加上其在不同视觉任务中的强大性能,显示出其作为未来视觉模型基础构建块的潜力。
?
 ?
?
 ?
?
三、?添加方法
部分代码如下所示,详细改进代码可私信我获取。(扣扣2453038530)
四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv8,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何将 element-ui 中的 el-select 默认展开
- 用户口碑推荐:亚马逊鲲鹏系统,购物体验的全新革命
- c++基础3
- 借助文档控件Aspose.Words,使用 Java 在 Word 文档中创建表格
- 200. 岛屿数量(js)
- 【每日一题】【12.24】 - 【12.28】
- java 项目日记实现两种方式:拦截器方式实现日记与定义日记注解方式实现日记
- 解决使用document.activeElement.blur()禁止弹出手机默认键盘
- CNVD漏洞审核类型尺度参考标准
- 常用算法-快速排序