OCR识别网络CRNN理解与Pytorch实现
CRNN是2015年的论文“An End-to-End Trainable Neural Network for Image-based Sequence?Recognition and Its Application to Scene Text Recognition”提出的图像字符识别网络,也是目前工业界使用较为广泛的一个OCR网络。论文地址:https://arxiv.org/abs/1507.05717
1. 网络结构
CRNN是一个端到端可训练的网络,并且可处理任意长度的字符序列。CRNN得名于Convolutional Recurrent Neural Network,从名称即可看出,该网络包含了卷积网络和递归网络。实际上,CRNN由三部分组成,分别是卷积层部分(Convolutional layers)、递归层部分(Recurrent Layers)和转录层部分(Transcription Layers),如下图所示:

其中, 卷积层的作用是从输入图像中提取特征,递归层则对卷积层输出的feature maps进行预测,最后,转录层将递归层的预测结果翻译成文字标签序列。CNN和RNN可由同一个损失函数进行联合训练。
在图像输入CRNN之前,需要缩放到指定高度height,宽度无限制。卷积层输出的feature maps在送入RNN之前,从左到右生成一个feature vector序列,第i个feature vector为feature maps第i列的元素的级联。这样做的好处是,每个feature vector代表了原图像上一个矩形区域的特征(感受野),使得网络能够预测不同长度的字符序列。
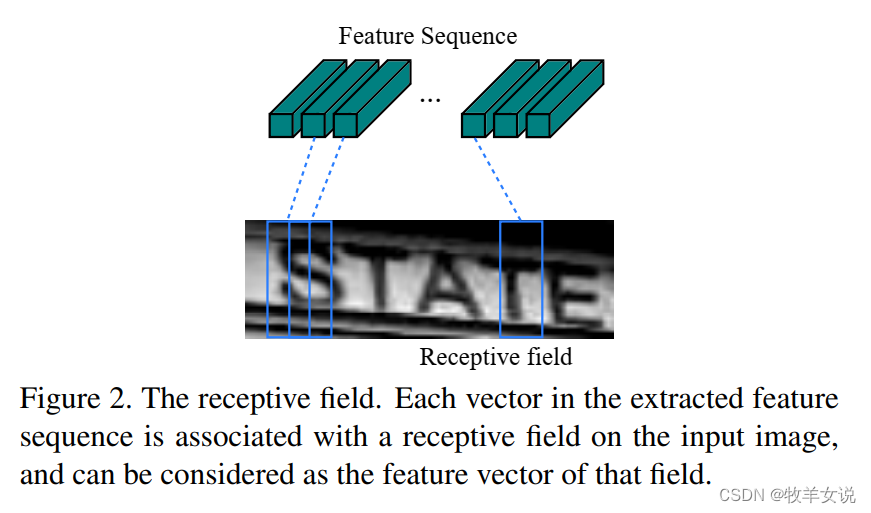
RNN网络的优势在于,它能够有效利用序列的上下文信息进行预测,比分别预测单个字符有更好的精确度和稳定性,同时,它对输入序列的长度无限制,比单纯使用CNN网络更加灵活。
由于传统RNN存在梯度爆炸和梯度消失问题,因此,在这篇文章中,作者采用了LTSM(Long-Short Term Memory)来克服该问题。一个LSTM包含一个记忆单元(Memory Cell)和三个乘法门(Multiplicative gates),分别为输入门(input gate)、输出门(output gate)和遗忘门(forget gate),如下图所示:
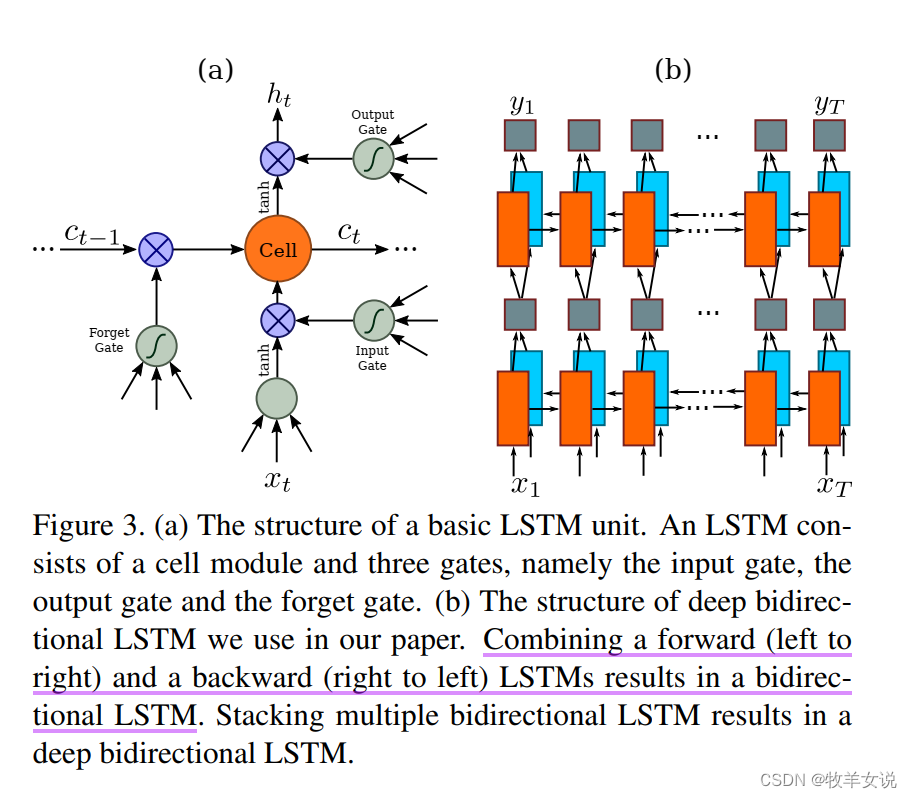
由于基于图像的文字识别具有较强的前向和后向上下文信息,因此,使用双向LSTM(bidirectional LSTM)是一个合适的选择。?
转录层将RNN层的预测结果(用概率表示)映射到字符序列。?在实践中,存在两种转录模式,分别是基于词典的转录,和无词典转录。在基于词典的模式中,会选择词典中最高概率的标签进行预测;而无词典模式,预测则是在无任何词典的情况下进行的。
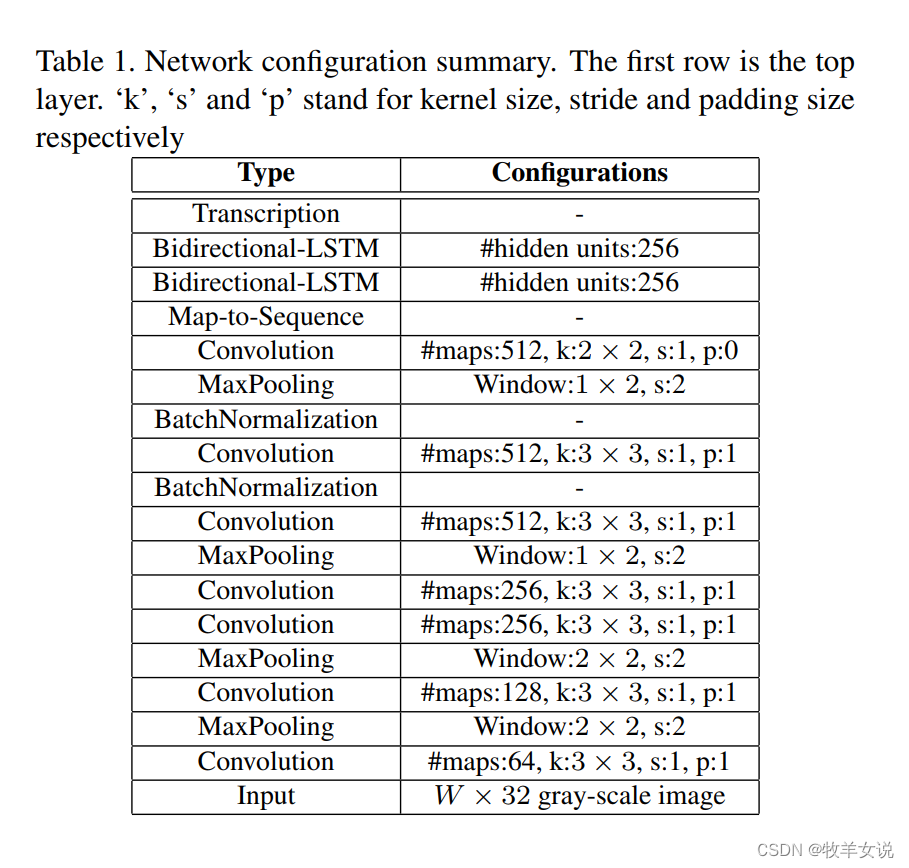
CRNN的具体网络结构及配置如下:
2. 代码实现?
网上找到一个CRNN的Pytorch实现,亲测好用,代码链接:CRNN Pytorch
网络定义:
import torch.nn as nn
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
conv = self.cnn(input)
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
conv = conv.permute(2, 0, 1) # [w, b, c]
# rnn features
output = self.rnn(conv)
return output
?其中,Bidirectional LSTM的定义如下:
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return outputDemo是基于字典的转录方式,可以识别0~9的1-0个数字,以及a~z的26个字母。
import torch
from torch.autograd import Variable
import utils
import dataset
from PIL import Image
import models.crnn as crnn
model_path = './data/crnn.pth' # 与训练模型路径
img_path = './data/demo.png' # 测试图片路径
alphabet = '0123456789abcdefghijklmnopqrstuvwxyz' # 字典
model = crnn.CRNN(32, 1, 37, 256)
if torch.cuda.is_available():
model = model.cuda()
print('loading pretrained model from %s' % model_path)
model.load_state_dict(torch.load(model_path))
converter = utils.strLabelConverter(alphabet) # 定义字典转录函数
transformer = dataset.resizeNormalize((100, 32)) # 图像预处理函数
image = Image.open(img_path).convert('L')
image = transformer(image)
if torch.cuda.is_available():
image = image.cuda()
print('image size: ', image.shape)
image = image.view(1, *image.size())
image = Variable(image)
model.eval()
preds = model(image) # CRNN预测
_, preds = preds.max(2) # 找到最大概率所对应的index
preds = preds.transpose(1, 0).contiguous().view(-1)
preds_size = Variable(torch.IntTensor([preds.size(0)]))
raw_pred = converter.decode(preds.data, preds_size.data, raw=True) # 逐一输出预测字符,如a-----v--a-i-l-a-bb-l-e---
sim_pred = converter.decode(preds.data, preds_size.data, raw=False) # 输出最终预测结果,如available
print('%-20s => %-20s' % (raw_pred, sim_pred))?demo执行结果:a-----v--a-i-l-a-bb-l-e--- => available ?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!