Hive实战:词频统计
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据文件
- 1、在虚拟机上创建文本文件
- 2、将文本文件上传到HDFS指定目录
- (二)实现步骤
- 1、启动Hive Metastore服务
- 2、启动Hive客户端
- 3、基于HDFS文件创建外部表
- 4、利用Hive SQL进行词频统计
- 5、演示分步完成词频统计
一、实战概述
-
在本次实战中,我们任务是在大数据环境下使用Hive进行词频统计。首先,我们在master虚拟机上创建了一个名为
test.txt的文本文件,内容包含一些关键词的句子。接着,我们将该文本文件上传到HDFS的/hivewc/input目录,作为数据源。 -
随后,我们启动了Hive Metastore服务和Hive客户端,为数据处理做准备。在Hive客户端中,我们创建了一个名为
t_word的外部表,该表的结构包含一个字符串类型的word字段,并将其位置设置为HDFS中的/hivewc/input目录。这样,Hive就可以直接读取和处理HDFS中的文本数据。 -
为了进行词频统计,我们编写了一条Hive SQL语句。该语句首先使用
explode和split函数将每个句子拆分为单个单词,然后通过子查询对这些单词进行计数,并按单词进行分组,最终得到每个单词的出现次数。 -
通过执行这条SQL语句,我们成功地完成了词频统计任务,得到了预期的结果。这个过程展示了Hive在大数据处理中的强大能力,尤其是对于文本数据的分析和处理。同时,我们也注意到了在使用Hive时的一些细节,如子查询需要取别名等,这些经验将对今后的数据处理工作有所帮助。
二、提出任务
- 文本文件
test.txt
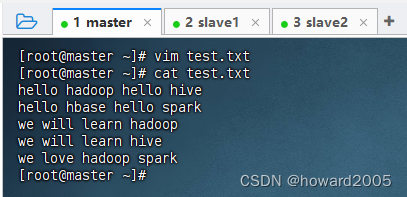
hello hadoop hello hive
hello hbase hello spark
we will learn hadoop
we will learn hive
we love hadoop spark
- 进行词频统计,结果如下
hadoop 3
hbase 1
hello 4
hive 2
learn 2
love 1
spark 2
we 3
will 2
三、完成任务
(一)准备数据文件
1、在虚拟机上创建文本文件
- 在master虚拟机上创建
test.txt文件
2、将文本文件上传到HDFS指定目录
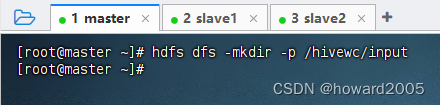
- 在HDFS上创建
/hivewc/input目录
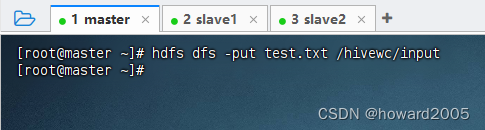
- 将
test.txt文件上传到HDFS的/hivewc/input目录
(二)实现步骤
1、启动Hive Metastore服务
- 执行命令:
hive --service metastore &,在后台启动metastore服务

2、启动Hive客户端
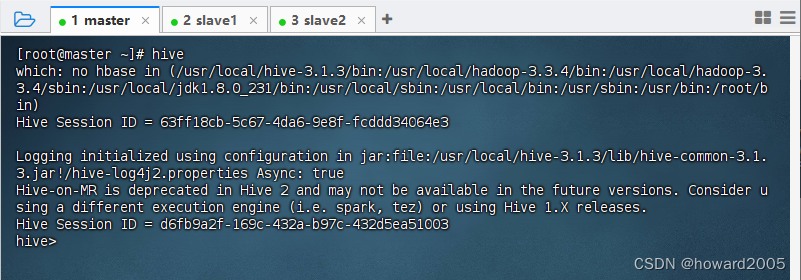
- 执行命令:
hive,看到命令提示符hive>
3、基于HDFS文件创建外部表
-
基于
/hivewc/input目录下的文件,创建外部表t_word,执行命令:create external table t_word(word string) location '/hivewc/input';

-
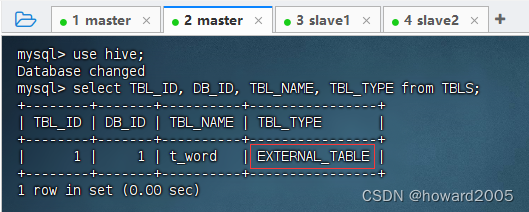
在MySQL的
hive数据库的TBLS表里可以查看外部表t_word对应的记录
-
要删除外部表,使用
truncate table <外部表名>
4、利用Hive SQL进行词频统计
- 编写Hive SQL语句,进行词频统计
- 执行命令:
select word, count(*) from (select explode(split(word, ' ')) word from t_word) t_word_1 group by word; - 注意:子查询
(select explode(split(word,' ')) word from t_word)必须取别名(比如t_word_1),否则会报错。
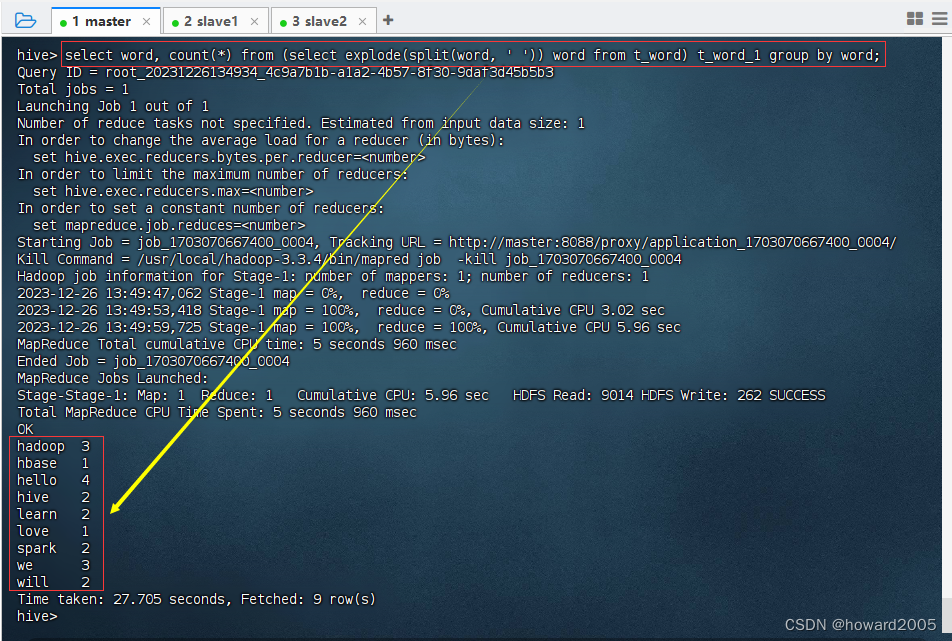
- 这个Hive SQL语句的主要功能是对文本数据中的单词进行词频统计,即计算每个单词在文本中出现的次数。
-
select word, count(*) from: 这部分是SQL的基本结构,表示我们要选择word字段和每个word字段值的计数。 -
(select explode(split(word, ' ')) word from t_word) t_word_1: 这是一个子查询。explode(split(word, ' ')):split(word, ' ')函数会根据空格将每一行的word字段值分割成一个数组。explode函数则会将这个数组扩展为多行,每行包含数组中的一个元素。这样,原来的一行文本就变成了多行,每行只包含一个单词。t_word_1是给这个子查询结果取的别名,这是Hive的要求,对于嵌套查询的结果需要指定别名。
-
group by word: 这部分指示Hive对查询结果进行分组,具体来说,是按照word字段的值进行分组。在分组之后,对于每个唯一的word值,Hive都会计算其出现的次数(通过count(*))。
- 综上所述,这个Hive SQL语句的作用是:首先,使用
explode和split函数将原始文本数据中的句子拆分为单个单词;然后,通过子查询将这些单词作为新的行进行处理;最后,按照单词进行分组并计算每个单词的出现次数。执行该语句后,结果将显示每个单词及其在文本中出现的次数。
5、演示分步完成词频统计
- 创建
v_word视图,执行命令:CREATE VIEW v_word AS SELECT explode(split(word, ' ')) AS word FROM t_word;

- 查看
v_word视图的记录,执行命令:SELECT * FROM v_word;

- 对
v_word视图按word字段分组统计个数,执行命令:SELECT word, count(*) FROM v_word GROUP BY word;

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小创学习记录
- 【Java基础概述-7】详说Java中的异常Throwable。
- Linux基础知识-命令
- centos7.9安装redmine5.1.1
- 不慌,新手专属!10款免费画图软件助你轻松入门!
- imgaug库图像增强指南(33):塑造【云层】效果的视觉魔法
- 基于SpringBoot+Vue的实验室管理系统(源码+文档+包运行)
- 阿里云Centos8安装Dockers详细过程
- Python安装与配置
- bash数组的用法