Learning Vision-and-Language Navigation from YouTube Videos
问题:
现有的VLN方法受小规模环境或不合理的路径指令训练的影响,限制了对不可见环境的泛化
解决方案:
使用Youtube上海量的房屋参观视频
1、根据youtube的视频创建一个大规模数据集,该数据集包含来自房屋参观视频的合理路径指令对
2、在创建的数据集上预训练智能体
面临的挑战:
1、很难从大量视频帧中确定轨迹节点的位置并表示节点中的视觉内容
2、真实的VLN指令包括各种动作描述,但由于动作隐含在视频中,从导航clips中获取相应的指令具有挑战性。因此,获取轨迹上的匹配指令并不简单
3、来自真实导航经验的布局知识难以挖掘和建模,这阻碍了智能体学习布局推理能力
具体方法:
1、基于熵的轨迹生成方法。设想轨迹中的节点应该尽可能的包含多类型的房间。因此,将视频中具有相同房间类型的帧分组,将每个组视为轨迹中的一个节点,并且选择组中分类熵最低的帧来表示节点中的视觉内容
2、训练一个动作感知生成器,从未标记的轨迹生成指令。即采用动作逆模型来伪标记沿着轨迹的动作,并通过手工设计的规则将它们填充到指令中
3、设计一个自我监督的轨迹合理性判断任务,要求智能体可以识别合理的导航轨迹。(该任务集成在智能体lily上,并且在R2R和REVERIE数据集上呈现出了最先进的性能)
构建一个youtube VLN数据集
多样化的轨迹生成——》基于熵的方法
我们寻求从 YouTube 视频构建离散的导航轨迹。与离散导航数据集(例如,R2R [2])类似,每个轨迹包含 K 个导航节点,代表导航路径的不同位置。
面临的两个挑战:
1、如何确定组成轨迹的位置,使得轨迹更加多样化;
2、如何表示每个节点位置的视觉内容
具体做法:
从youtube中收集导航数据
收集了4078个视频,使用稀疏采样和现成的图像分类器预处理视频,过滤掉冗余或者嘈杂的帧(去除掉人物和室外场景特征的帧)。
使用在places365上训练的wideresnet过滤户外帧
使用在coco上训练的maskrcnn过滤人
确定轨迹节点的位置
需要构建的轨迹在有限的导航节点内也包含不同的视觉内容。
因此,使用CLIP来识别室内图像的房间类型,将具有相同房间类型的时间相邻帧收集为一组,并将该组视为导航节点之一。
对抽取来的原始帧使用预训练好的Vit-B/32表示视觉内容
房间类型和物体类型参考了MP3D,其中房间类型有12种
areas = ['office', 'lounge', 'family room', 'entry way', 'dining room', 'living room', 'stairs', 'kitchen',
? ? ? ? ?'porch', 'bathroom', 'bedroom', 'hallway']
objects = ['wall', 'floor', 'chair', 'door', 'table', 'picture', 'cabinet', 'cushion', 'window', 'sofa', 'bed',
? ? ? ? ? ?'curtain', 'chest of drawers', 'plant', 'sink', 'stairs', 'ceiling', 'toilet', 'stool', 'towel',
? ? ? ? ? ?'mirror', 'tv monitor', 'shower', 'column', 'bathtub', 'counter', 'fireplace', 'lighting', 'beam',
? ? ? ? ? ?'railing', 'shelving', 'blinds', 'gym equipment', 'seating', 'board panel', 'furniture',
? ? ? ? ? ?'appliances', 'clothes','person']
为了增加轨迹的多样性,在相邻房间节点之间随机插入一个房间到另一个房间期间捕获的视频帧组成的过渡节点。
在节点中表示视觉内容
选择信息最丰富的图像来表示节点特征,因此使用具有最低分类熵的图像来表示节点的当前视图。为了模仿全景视觉上下文,合并当前视图的M个相邻连续图像。相比于airbert,合并了当前视图属于同一位置的相邻帧。
最终,我们随机选择K个连续节点来构建轨迹。
使用的是香农熵来表示节点的当前视图
动作感知的指令生成
挑战:如何正确描述导航路径上的视觉内容和操作
具体做法:
1、生成带有动作和名词短语的空白指令模板,使用的是R2R数据集中的指令空白模板
2、使用Clip描述轨迹中的每个节点,即名词短语的空白,包括物体类型和房间类型的名称
3、使用动作逆模型推断动作,推断的准确率有96%,选择动作填进去。主要是resnet18和搭建的一些CNN层
4、使用视觉描述和操作填充指令模板
动作map有三种:0:向前;1:左;2:右
Lily智能体
给定从YouTube视频生成的类似VLN的合理路径指令对,我们然后描述如何从这些数据中学习 Lily 代理。如图3所示,整个VLN模型由两个组件组成:一个视觉和语言backbone(即多层transformer),用于对轨迹和指令之间的关系进行建模;以及一个决策模块,用于预测下一个动作或路径指令对的匹配分数。视觉和语言backbone可以是任何类型的跨模式网络。我们选择 ViLBERT与 Airbert进行公平比较。作为一种常见的做法,pretext任务用于预训练backbone网络。接下来,我们描述如何使用提出的轨迹判断pretext任务在 Youtube-VLN 数据集上预训练backbone网络。

Learning Layout from Trajectory Judgment
鉴于上述模型架构,我们建议使用轨迹判断(TJ)任务来训练 VLN 代理,使其能够推理布局。在这里,我们详细阐述了所提出的轨迹判断任务。
具体的评判方式
轨迹判断任务旨在判断轨迹的合理性。
具体方法:
将生成的轨迹视为正(合理)样本,将打乱的轨迹视为负(不合理)样本。为了完成此任务,智能体需要推理视觉信息并识别房间类型,然后推断轨迹是否与真实环境布局分布相匹配。
具体来说,我们首先计算 [IMG] 和 [CLS] 标记的输出特征的点积。然后,我们将这个向量特征输入到线性层来预测指令轨迹是否合理的概率。该模型旨在最小化二元交叉熵损失:
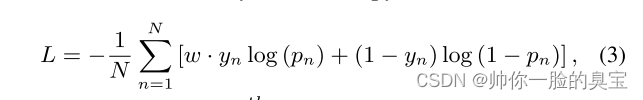
其中,如果第 n 个轨迹合理,则 yn = 1,否则 yn = 0。pn 表示第 n 个轨迹被预测为合理的概率。 N 是批次中的轨迹数量。 w是缓解正负样本不平衡的因子,等于负样本数与正样本数的比值。
负样本的生成
对正样本进行洗牌以生成负样本:1)仅对转移节点进行洗牌; 2)对所有节点进行shuffle; 3)保持房间节点的顺序,并随机插入其他视频中的节点。通过这种方式,我们创建了丰富且困难的负样本,这增加了任务难度,帮助智能体以更复杂的方式理解真实布局。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!