Dubbo负载均衡解析
Dubbo负载均衡四件套
相比Ribbon负载均衡策略里的十八般兵器,Dubbo就显得低调的多了,它只提供了负载均衡四件套,让我们先来简单了解一下:
| 负载均衡策略 | 底层算法 |
|---|---|
| RandomLoadBalance | 基于权重算法的负载均衡策略 |
| LeastActiveLoadBalance | 基于最少活跃调用数算法 |
| ConsistentHashLoadBalance | 基于Hash一致性 |
| RoundRobinLoadBalance | 基于加权轮询算法 |
接下来,我们去了解下这四件套都有什么特殊功效。
RandomLoadBalance-权重算法
RandomLoadBalance是Dubbo的缺省实现,所谓权重算法,实际上是加权随机算法的意思,它的算法思想相当简单。我们来看一幅图
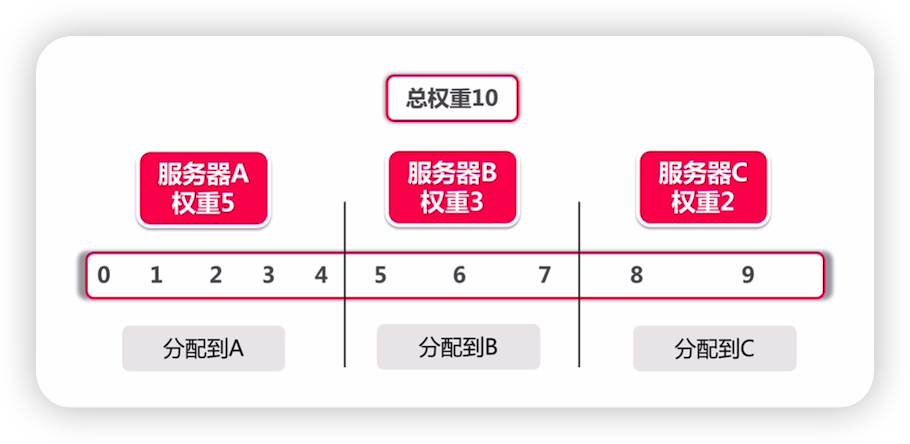
假设我们有一组服务器分别是A,B,C,他们对应的权重为A=5,B=3,C=2,权重总和为10。现在把这些权重值平铺在一维坐标值上,[0,5)区间属于服务器A,[5,8)区间属于服务器B,[8,10)区间属于服务器 C。
接下来通过随机数生成器生成一个范围在[0,10)之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器A对应的区间上,此时返回服务器A即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。
只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器A被选中的次数大约为5000次,服务器B 被选中的次数约为3000次,服务器C被选中的次数约为2000次。
LeastActiveLoadBalance -最少活跃数
这个算法的思想就是“能者多劳”,它认为当前活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求,因此应优先将请求分配给该服务提供者。
该算法给每个服务提供者设置一个“active’ 属性,初始值为0,每收到一个请求,活跃数加1,完成请求后则将活跃数减。在服务运行-段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。
当然这种算法也有不公平的地方,比如某台机器是扩容后新上线的机器,因此active的值 是0,而这时Dubbo会认为这台机器的性能快如闪电,但其实这台机器的性能有可能慢如老狗。
除了最小活跃数以外,LeastActiveLoadBalance在实现上还引入了权重值。所以准确的来说,LeastActiveLoadBalance 是基于加权最小活跃数算法实现的。
举个例子说明一下,在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时Dubbo会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可。 关于LeastActiveLoadBalance的背景知识就先介绍到这里.
ConsistentHashLoadBalance -Hash算法
一致性Hash算法由麻省理工学院的Karger及其合作者于1997年提出的,算法提出之初是用于大规模缓存系统的负载均衡。在Dubbo中它的工作流程是这样的
- 首先根据服务地址为服务节点生成一个Hash,并将这个Has h 投射到[0,232 -1]的圆环上
- 当有请求到来时,根据请求参数等维度的信息作为一个Key
,生成一个hash 值。然后查找第一个大于或等于该Hash值的服务节点,并将这个请求转发到该节点。 - 如果当前节点挂了,则查找另一个大于其Hash值的缓存节点即可。
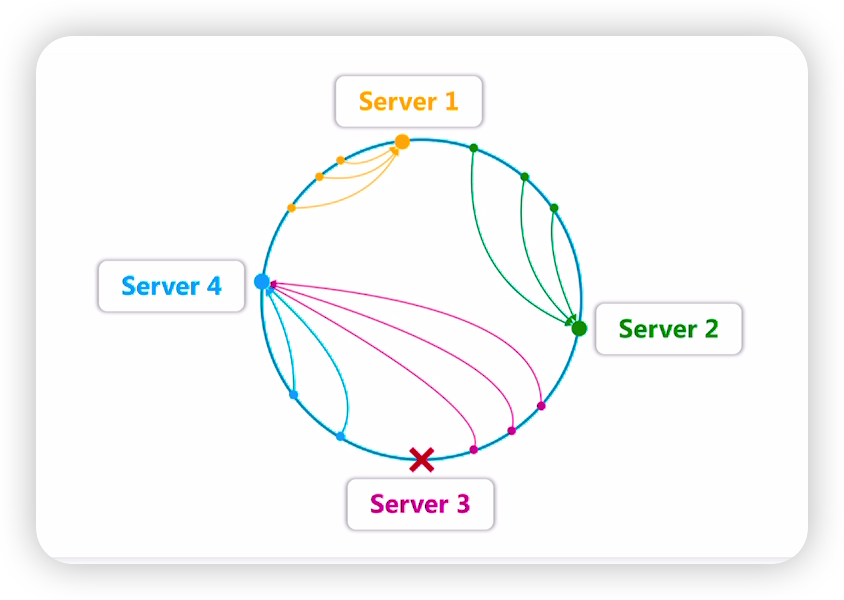
如上图所示,4台机器均匀分布在圆环中,所有请求会访问第一个大于或等于自身Hash的节点。Server3这台机器处于不可用的状态,因此所有请求继续向后寻址直到找到Server4。
RoundRobinLoadBalance-加权轮询
终于看到一个熟悉的面孔了,它和Ribbon的RoudRobinRule差不多。我们先来理解下什么是加权轮询。
所谓轮询是指将请求轮流分配给每台服务器。比如说我们有3台机器A、B、C,当请求到来的时候我们从A开始依次派发,第一个请求给A,第二个给B,依次类推,到最后一个节点C派发完之后再回到A重新开始。
从上面的例子中可以看出,每台机器接到请求的概率是相等的,但是在实际应用中我们并不能保证每台机器的效率都一样,因此可能会出现某台Server性能特别慢导致无法消化请求的情况。因此我们需要对轮询过程进行加权,以调控每台服务器的负载。
经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器A、B、C权重比为5:2:1。那么在8次请求中,服务器A将收到其中的5次请求,服务器B会收到其中的2次请求,服务器C则收到其中的1次请求。
配置负载均衡策略
Dubbo可以在类级别(@Service)和方法级别(@Resource)指定负载均衡策略,以方法级别为例,下面的代码配置了使用RoundRobin的负载均衡规则:
@Reference(loadbalance = "roundrobin")
private IDubboService dubboService;
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PDF文档创建时间修改时间怎么改?推荐一个一键修改的方法
- Packet Tracer - 配置第 3 层交换和VLAN间路由
- Java 已死、前端已凉?真相背后的技术浪潮
- 7-1 建立二叉搜索树并查找父结点(PTA - 数据结构)
- 【算法】选择最佳路线(超级源点)
- 上海亚商投顾:创业板指低开低走 煤炭等周期股逆势走强
- 八、K8S metrics-server
- 北京大学漏洞报送证书
- Python是怎么调用接口的
- 2024年最新安全且稳定的大数据传输方式