【六大排序详解】中篇 :选择排序 与 堆排序
选择排序 与 堆排序
选择排序
1 选择排序
1.1 选择排序原理
选择排序可以用扑克牌理解,眼睛看一遍所有牌,选择最小的放在最左边。然后略过刚才排完的那张,继续进行至扑克牌有序。这样一次一次的挑选,思路很顺畅。总结为:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。

1.2 排序步骤
- 从头开始遍历数组,设置mini指向最小值下标(先指向首元素)。
- 遇到比a[mini]小的值,mini改变为新下标。直到遍历到结尾。
- 将数组首元素与mini指代元素交换位置。
- 从排好序的下一个元素开始,重复 1-3 步骤。
- 直到排序完成。

1.3 代码实现
void SelectSort(int* a, int n) {
int begin = 0;//无序部分开头
int mini = 0;//先设置mini指向开头
//直到begin = n ,都有序。
while (begin<n) {
//从无序部分开始,选择最小值。
for (int i = begin; i < n; i++) {
if (a[i] < a[mini]) //如果小则下标更新。
mini = i;
}
//将选择出来的最小值放置到无序部分开头。
swap(a, begin, mini);
begin++;//begin向后推进
mini = begin;//mini更新
}
}
排序功能实现,效果非常棒!

直接选择排序的特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
2 堆排序
2.1 堆排序原理
堆排序是一种特殊的选择排序,堆排序以二叉树为基础。选择两个子元素其一,然后逐层上升或下沉,直到有序。在认识理解堆排序之前,我们需要了解如何建堆。这里我们由于是学习堆排序,所以下面我只介绍堆的大小堆建立,向上调整算法,向下调整算法。其余堆相关知识会在另一篇文章详细介绍。
2.1.1 大堆与小堆
首先:堆 是一种特殊的树,满足以下条件即为堆,是二叉树的顺序结构。
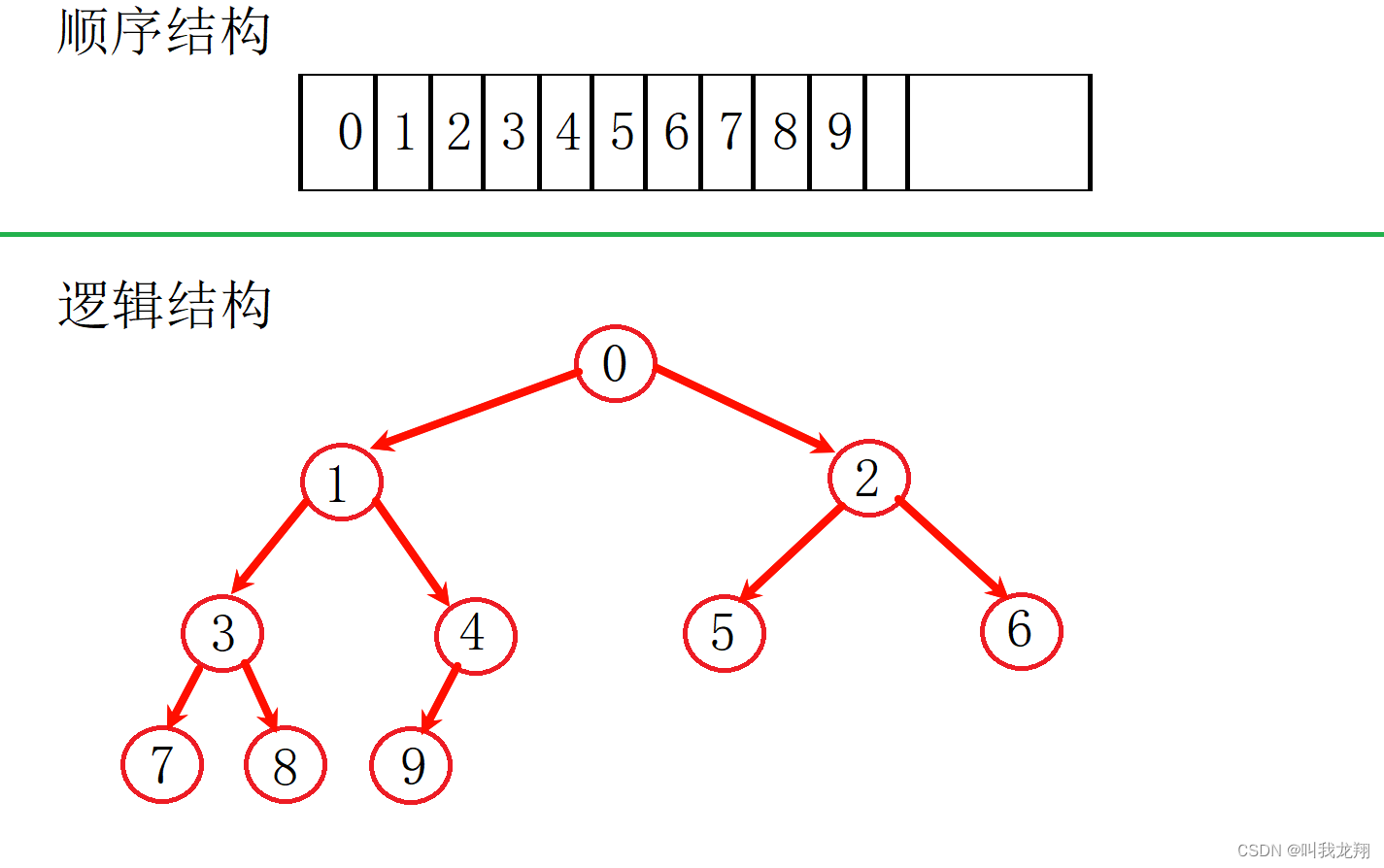
二叉树内容见:二叉树解释
根据二叉树的知识,堆一定是完全二叉树(除了最后一层,其他层的节点个数都是满的,最后一层的节点都集中在左部连续位置)
堆分为大小堆
即 :堆中每一个节点的值都必须大于等于或小于等于其左右子节点的值
每个节点的值都大于等于其子树节点的堆叫“大堆“,根是所有数据的最大值
每个节点的值都小于等于其子树节点的堆叫“小堆“,根是所有数据的最小值
2.1.2 向上调整算法
我们如何把基本的数组变成大堆和小堆呢?这里就需要向上调整算法。
向上调整顾名思义,就是从尾部开始,一层一层向上调整。
以建大堆为例
- 从尾节点开始,如果该孩子节点大于父母节点,则向上调整(上浮)。
- 直到调整到合适的位置。
- 尾节点向前推移,继续重复 1 - 2 步骤。
- 直到遍历所有元素,完成建堆。
void adjustup(int* a, int child) ;
int main(){
//...
for (int i = n - 1; i > 0; i--) {
adjustup(a, i);//逐个遍历
}
//...
}
//建堆
void adjustup(int* a, int child) {
int parent = (child - 1) / 2;//根据二叉树知识取父母节点
while (child > 0) {
if (a[child] > a[parent]) {
swap(a, child, parent);
//如果该孩子节点大于父母节点,则向上调整(上浮)
}
child = parent;//孩子节点迭代
parent = (child - 1) / 2;//父母节点迭代
}
}
这样就建立了大堆。小堆原理相同,只需更改大于号和小于号。
2.1.3 向下调整算法
建立好堆之后,如何进行排序呢?这时就需要向下调整算法。首先我们要有一个共识:
排升序建大堆;排倒序建小堆。
之所以这样是因为向下调整算法的缘故,下面我们来看向下调整算法,之后解释原因。
以排升序为例
- 首先头元素与尾元素交换位置。
- 然后从头开始向下调整,如果父母节点大于孩子节点中较大的,则交换。
- 调整完成后,尾向前推进。继续重复 1 - 2 步骤。
- 直到遍历所有元素。
void adjustdown(int* a, int parent,int size);
int main(){
//...
int end = n - 1;
while (end > 0) {
swap(a, end, 0);
adjustdown(a,0,end);
end--;
}
//...
}
void adjustdown(int* a, int parent,int size) {
int child = parent * 2 + 1;
while (child < size) {
if (child + 1 < size && a[child + 1] > a[child]) {
child++;
}
if (a[child] > a[parent]) {
swap(a, child, parent);
}
parent = child;
child = parent * 2 + 1;
}
}
这样遍历一遍向下调整就可以完成排序。我们理解向下调整算法之后就可以发现
**排升序建大堆;排倒序建小堆。**是非常巧妙的,
以排升序为例,每次放在交换到首元素 的都是最小值(最大值),然后向下调整,把它放到该放在的位置上。
2.2 排序步骤
我们理解上述两种算法之后,就可以非常顺畅理解堆排序。
- 向上调整建堆
- 向下调整排序
理解向上调整算法和向下调整算法之后,堆排序就迎刃而解。
2.3 代码实现
void adjustup(int* a, int child) {
int parent = (child - 1) / 2;
while (child > 0) {
if (a[child] > a[parent]) {
swap(a, child, parent);
}
child = parent;
parent = (child - 1) / 2;
}
}
void adjustdown(int* a, int parent,int size) {
int child = parent * 2 + 1;
while (child < size) {
if (child + 1 < size && a[child + 1] > a[child]) {
child++;
}
if (a[child] > a[parent]) {
swap(a, child, parent);
}
parent = child;
child = parent * 2 + 1;
}
}
void HeapSort(int* a, int n) {
assert(a);
for (int i = n - 1; i > 0; i--) {
adjustup(a, i);//逐个遍历
}
int end = n - 1;
while (end > 0) {
swap(a, end, 0);
adjustdown(a,0,end);
end--;
}
}
这里我们是可以进一步优化的,因为向上调整算法可以有向下调整算法来代替。
算法优化就交给你完成了。
3 时间复杂度分析
让我们和之前的排序算法来比较一下。依然是10万组数据,让我们看一下运行时间。(以冒泡排序为对照)
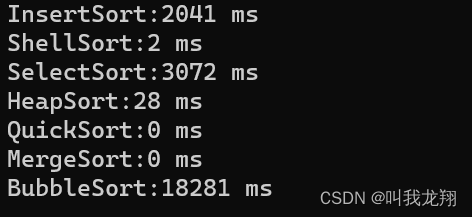
显然选择排序和插入排序是一个级别,堆排序和希尔排序都非常快速。
我们再来比较一下希尔排序与堆排序。100万组数据
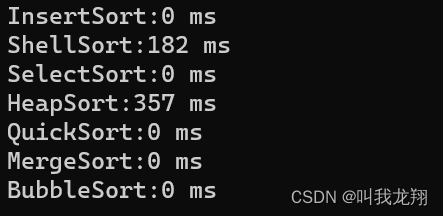
这里希尔貌似更快,但其实希尔排序与堆排序是一个量级,甚至在更多数据下,堆排序会更优。
Thanks?(・ω・)ノ
下一篇文章见!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《PCI Express体系结构导读》随记 —— 第I篇 第1章 PCI总线的基本知识(15)
- 力扣(leetcode)第205题同构字符串(Python)
- 【总结】Linux命令中文帮助手册
- Qt事件过滤
- 安卓开发之关于如何用viewPager实现三种不同效果的轮播图
- 嵌入式中的数据初始化
- 【每天五道题,轻松公务员】Day3:太阳常识
- Vue利用pinia来完成组件之间的数据共享,可持续化存储要点总结和部分代码
- 案例125:基于微信小程序的个人健康数据管理系统的设计与实现
- 使用docker实现logstash同步mysql到es