IO流的几大模型(最全IO流)
目录
什么是IO?
????????I/O输入/输出(Input/Output),分为IO设备和IO接口两个部分。
阻塞IO
????????阻塞IO是指调用结果返回之前,当前线程会被挂起,调用线程只有在到结果之后才会返回。
非阻塞IO
????????非阻塞IO是指在不能立刻得到结果之前,该调用不会阻塞当前线程。
TCP/IP协议

五大IO模型

阻塞IO模型

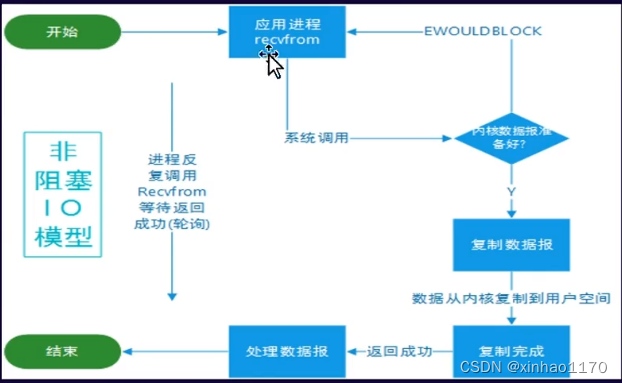
非阻塞IO模型
IO多路复用模型

信号驱动IO模型

异步IO模型

IO的多路复用(重点)
????????IO多路复用(IO Multiplexing)是指单个进程/线程就可以同时处理多个IO请求
| select | poll | epoll | |
|---|---|---|---|
| 底层数据结构 | 数组存储文件描述符 | 链表存储文件描述符 | 红黑树储存监控的文件描述符,双链表储存就绪的文件描述符 |
| 如何从fd数据中获取就绪的fd | 遍历fd_set | 遍历链表 | 回调 |
| 时间复杂度 | 获得就绪的文件描述符需要遍历fd数组,O(n) | 获得就绪的文件描述符需要遍历fd链表,O(n) | 当有就绪事件时,系统注册的回调函数就会被调用,将就绪的fd放入到就绪链表中。O(1) |
| FD数据拷贝 | 每次调用select,需要将fd数据从用户空间拷贝到内核空间 | 每次调用poll,需要将fd数据从用户空间拷贝到内核空间 | 使用内存映射(mmap),不需要从用户空间频繁拷贝fd数据到内核空间 |
| 最大连接数 | 有限制,一般为1024 | 无限制 | 无限制 |
????????select和poll适用于连接数较少并且连接数很活跃的时候,性能比epoll更高
????????epoll则是适用于连接数多并且都不活跃的时候,epoll的效率更高
select的工作机制
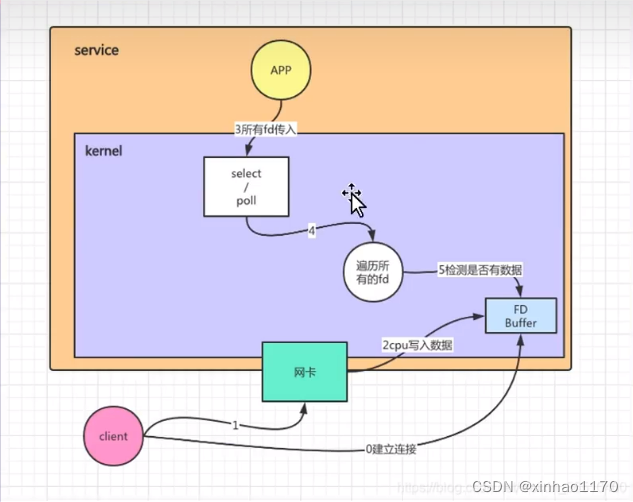
????????第一步跟内核建立连接,数据直接通过我们的网卡传送到我们的文件buffer里面,我们的用户空间(应用)把它需要监控的文件描述符传到select这个函数/传到我们的内核里面,在内核空间针对于我们的文件描述符的set去遍历一遍,去检查我们有没有就绪的socket描述符,如果没有的话就进入一个休眠的状态,直到有了后,我们的内核空间就会返回我们的select结果给我们的用户线程,然后告诉他我们的文件已经准备就绪了,用户拿到我们就绪描述符的数量之后呢再次遍历我们的内核去找出我们的就绪的文件描述符,这个时候我们的用户线程就可以针对文件描述符去进行读写的操作了
????????优点:基于POSIX的一个标准,这个标准基于所有的平台,不仅仅是我们的linux,Windows,包括我们的Mac,拥有一个好的跨平台性,缺陷是有最大的连接上限
epoll的工作机制

????????首先通过epoll_create函数去创建epoll,然后epoll会去创建一个红黑树和我们的链表
????????当我们客户端建立的连接后有一个文件描述符的buffer,通过网卡去传输数据,传输完数据之后把准备就绪的数据写到我们的双向链表
????????epoll_ctl的作用是帮我们将文件描述符添加到我们的红黑树
????????epoll_wait的作用当我们调用epoll_wait的时候监测我们的链表中有没有数据,如果有数据,有数据就去返回
???IO多路复用性能分析
????????每秒两千个连接的时候,我们并发能达到一万,随着我们的连接数增加,我们的性能在不断下降
????????红线是poll模型,绿线是select模型,蓝线是我们的epoll模型
传统IO模型
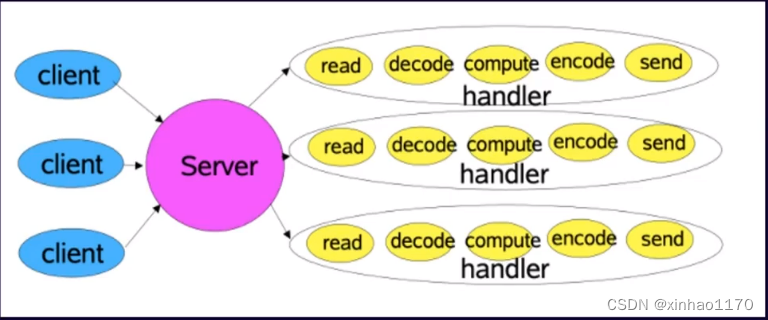
为什么需要Reator模型
????????1. 每一个连接请求 进来都会开一个handler,适用于连接数比较小的时候,当连接数上来时对内存的损耗很严重?
????????2. CPU数量远小于我们的线程数量,对于线程上下文切换的性能损耗也是非常大的
Reactor模型
NIOReactor-单Reactor单线程

由三大组件组成
-
Reactor(dispatch【分发器】)
-
acceptor
-
handler
执行流程
-
Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发。
-
如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理。
-
如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应
-
Handler 会完成 Read→业务处理→Send 的完整业务流程。
优点:
????????模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:
-
性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能阻塞。
-
可靠性问题,线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
使用场景:
????????客户端的数量有限,业务处理非常快速。java原生nio就是这个模型。
NIOReactor模型-单Reactor多线程

流程:
-
Reactor 对象通过select 监控客户端请求事件, 收到事件后,通过dispatch进行分发。
-
如果建立连接请求, 则由Acceptor 通过accept 处理连接请求, 然后创建一个Handler对象处理完成连接后的各种事件。
-
如果不是连接请求,则由reactor分发调用连接对应的handler 来处理。
-
handler 只负责响应事件,不做具体的业务处理, 通过read 读取数据后,会分发给后面的worker线程池的某个线程处理业务。
-
worker 线程池会分配独立线程完成真正的业务,并将结果返回给handler。
-
handler收到响应后,通过send 将结果返回给client。
优点:
????????可以充分的利用多核cpu 的处理能力。
缺点:
????????多线程数据共享和访问比较复杂, reactor 处理所有的事件的监听和响应,在单线程运行, 在高并发场景容易出现性能瓶颈.。
NIOReactor模型-主从Reactor多线程

流程:
-
Reactor主线程 MainReactor 对象通过select 监听连接事件, 收到事件后,通过Acceptor 处理连接事件。
-
当 Acceptor 处理连接事件后,MainReactor 将连接分配给SubReactor 。
-
subreactor 将连接加入到连接队列进行监听,并创建handler进行各种事件处理。
-
当有新事件发生时, subreactor 就会调用对应的handler处理。
-
handler 通过read 读取数据,分发给后面的worker 线程处理。
-
worker 线程池分配独立的worker 线程进行业务处理,并返回结果。
-
handler 收到响应的结果后,再通过send 将结果返回给client。
-
Reactor 主线程可以对应多个Reactor 子线程, 即MainRecator 可以关联多个SubReactor
优点
-
父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
-
父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
缺点:
????????编程复杂度较高。
应用场景:
????????这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用nodejs定时备份mysql数据库与恢复
- 助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv6开发构建生活场景下城市部件检测识别系统
- 窗口虽小,功能良多:一篇文章带你玩转鸿蒙4的实况窗
- Mac Install Parallels Desktop 19.1.0
- 【Spring】07 懒加载
- __declspec (dllexport)定义了导出函数,但dll中没有此函数
- 移动光缆使用规定
- 零基础如何自学编程?自学编程资料哪里找?
- 无约束优化问题求解笔记(2):最速下降法
- StartAI文生图攻略(元旦篇)