第一篇:大模型技术基础之Transformer崛起
写在前面? ? ?
本文主要阐述大模型的技术演变路线,侧重于科普大模型的技术逻辑,技术痛点,以及一些商业机会,没有深入介绍技术细节。看完此文,你可以了解到大模型的前世今生,理解到技术发展趋势,适合准备入门大模型以及想在大模型方面创业的人士,如有表述不当之处,敬请提出。废话少说,开始吧!
大模型的定义并不明确,因为没有一个固定的标准来衡量一个模型是否算是“大模型”,这可能取决于参数数量、训练数据量、batch 大小等因素。一般来说,参数多、训练集大、batch 大的模型通常会被称为大模型。大模型从领域划分,可分为:
- 视觉大模型(Visual Foundation Model)【ViT-22B】
- 语言大模型(Large Language Model)【BERT,GPT】
- 多模态大模型【CLIP,Stable Diffusion】
然而,当今所说的“大模型”通常是指大语言模型LLM(Large Language Model)。因此,我们今天将重点讨论LLM及其相关应用。。
大模型的流行程度不言而喻,它直接推动了通用人工智能(AGI,Artificial General Intelligence)领域的发展。尽管作为一个语言模型,LLM展现出了出色的多模态数据融合能力、推理能力和新颖性,这些正在颠覆传统深度学习的研发范式。那么,从技术角度来看,它究竟具备了哪些能力,让人们对其寄予如此厚望呢?今天我们将围绕这个话题展开讨论,探讨以下问题:
- LLM从2017年的《Attention is all you need》到现在大火的ChatGPT,它在技术上是如何进化的?
- LLM所展现出的推理能力真的是“智能”么?它真的像人类一样思考具备AGI的潜力吗?
- 多模态数据是如何和LLM习得的“知识”对齐(Alignment)的?现在层出不穷的生成类应用是如何做的?
- 它理论上的upper bound和工程上的upper bound在哪里?我们该如何利用它?
LLM的前世今生
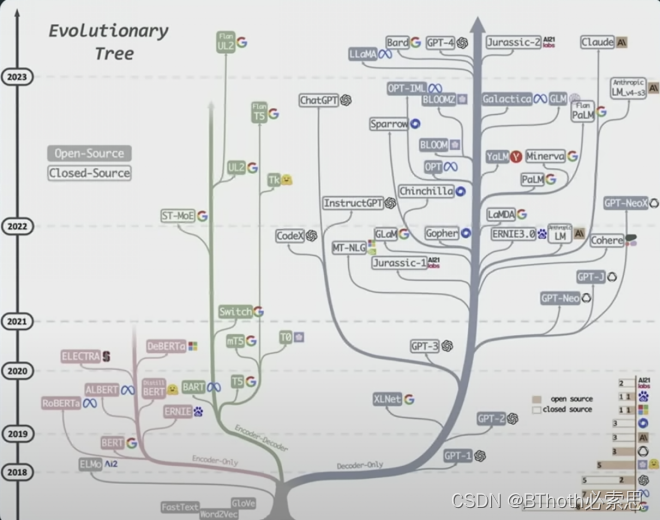
语言模型的爆发最早可以追溯到2017年的《Attention is All You Need》。可以看到,在transformer发布之后,语言模型开始蓬勃发展至今。
Transformer
这里简单回顾下Transformer提出的self-attention架构。因为它的思想在多模态、大模型的技术中起到很大的作用。在Transformer模型中,multi-head?attention的基础是self-attention,而其中的KQV概念需要好好理解。K、Q和V代表了"Key"、"Query"和"Value"。这些术语用于描述Transformer中的自注意力机制(self-attention mechanism)。
"Key"(K)表示每个单词的关键信息,用于被计算注意力权重。
"Query"(Q)表示当前位置或单词的查询向量,用于与其他单词进行比较以计算注意力权重。
"Value"(V)表示与Key相关联的实际数值,用于计算加权和。
在自注意力机制中,Query向量会与Key向量进行点积操作,以获得注意力分数,这些分数会用于对Value向量进行加权求和,从而得到最终的表示。这种机制允许模型在处理长距离依赖性时能够更好地捕捉全局信息。为什么要有KQV呢,只有KQ不行吗?其实这里KQV都是单词向量的分身,一个分身Q负责出去找联系,一个分身K作为被找的对象,找完这些联系,不能白白浪费吧,所以就加权到V身上。而且这一套逻辑可以完美复制到所有的单词向量上。我们举个例子,来看看这些单词之间的关系是怎么样的。
Self-Attention
? ? ? ? ? ? ? ? ? ??? ???? ?
???? ?
? ? ? ? ? ? ? ? ?
这里和K,Q,V进行点乘的都是来自于输入text本身,所以这里被称为self-attention。最终求得的结果也是输入text中,得到每个token之间的相关性。如上图中与it相关性最强的是the animal。在有了这种token间的相关性信息之后,对结构稍加改造,增加一个one-hot的loss,那么我们就可以让Transformer根据一个输入序列来预测这个序列的下一个输出(next token prediction)是什么。这也是构建ChatGPT的基础概念。当我们使用ChatGPT也会发现,他的输出是一个词一个词蹦出来的。
Cross-Attention
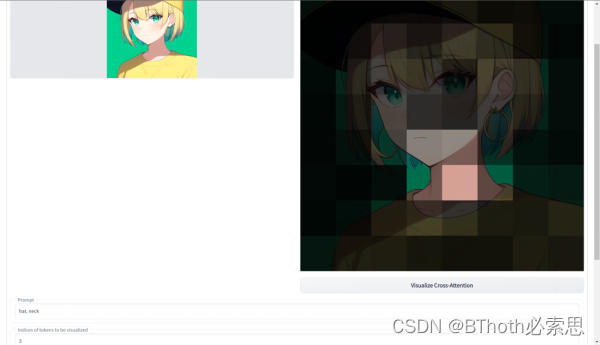
如果我们将其中的Q改成其他模态的数据,例如图片。KV仍然是text,这里便成为了cross-attention。例如我们visualize最常见的文生图模型Stable Diffusion,输入的prompt是hat, neck。这里我们可以看到,多模态模型采用Attention作为backbone不仅效果出众,还似乎给模型增加了一些可解释性。因此成为了一种最常见的多模态数据对齐LLM的方式,我们之后会详细解读。? ? ? ??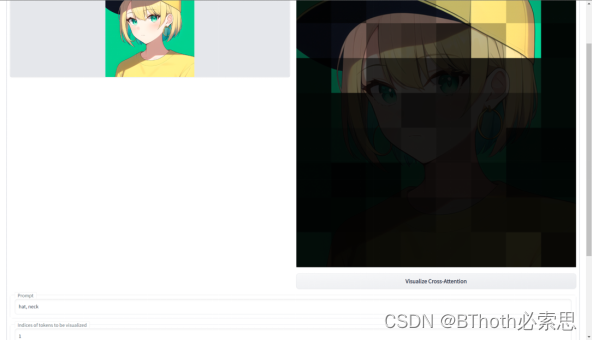
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 营销的尽头是矩阵!如何通过小魔推短视频矩阵快速破圈?
- 关于增强监控以检测针对Outlook Online APT活动的动态情报
- React Hooks
- visual studio 2019 移除/卸载项目已经如何再加载项目
- C++类调用另一个类的成员函数
- leetcode | go | 第632题 | 最小区间
- raid解析
- 第十六章 调用Callout Library函数
- linux查看已使用内存
- Linux系统编程(七):进程间通信(下)