RFM会员价值度模型
模型基本原理
会员价值度用来评估用户的价值情况,是区分会员价值的重要模型和参考依据,也是衡量不同营销效果的关键指标。
价值度模型一般基于交易行为产生,衡量的是有实体转化价值的行为。常用的价值度模型是RFM
RFM模型是根据会员
- 最近一次购买时间R(Recency)
- 购买频率F(Frequency)
- 购买金额M(Monetary)计算得出RFM得分
- 通过这3个维度来评估客户的订单活跃价值,常用来做客户分群或价值区分
- RFM模型基于一个固定时间点来做模型分析,不同时间计算的的RFM结果可能不一样
 ?RFM模型的基本实现过程
?RFM模型的基本实现过程
①设置要做计算时的截止时间节点(例如2017-5-30),用来做基于该时间的数据选取和计算。
②在会员数据库中,以今天为时间界限向前推固定周期(例如1年),得到包含每个会员的会员ID、订单时间、订单金额的原始数据集。一个会员可能会产生多条订单记录。
③ 数据预计算。从订单时间中找到各个会员距离截止时间节点最近的订单时间作为最近购买时间;以会员ID为维度统计每个用户的订单数量作为购买频率;将用户多个订单的订单金额求和得到总订单金额。由此得到R、F、M三个原始数据量。
④ R、F、M分区。对于F和M变量来讲,值越大代表购买频率越高、订单金额越高;但对R来讲,值越小代表离截止时间节点越近,因此值越好。对R、F、M分别使用五分位(三分位也可以,分位数越多划分得越详细)法做数据分区。需要注意的是,对于R来讲需要倒过来划分,离截止时间越近的值划分越大。这样就得到每个用户的R、F、M三个变量的分位数值。
⑤ 将3个值组合或相加得到总的RFM得分。对于RFM总得分的计算有两种方式,一种是直接将3个值拼接到一起,例如RFM得分为312、333、132;另一种是直接将3个值相加求得一个新的汇总值,例如RFM得分为6、9、6。
RFM划分案例思路说明
在得到不同会员的RFM之后,根据步骤⑤产生的两种结果有两种应用思路
思路1:基于3个维度值做用户群体划分和解读,对用户的价值度做分析
- 得分为212的会员往往购买频率较低,针对购买频率低的客户应定期发送促销活动邮件
- 得分为321的会员虽然购买频率高但是订单金额低等,这些客户往往具有较高的购买黏性,可以考虑通过关联或搭配销售的方式提升订单金额。
在得到不同会员的RFM之后,根据步骤⑤产生的两种结果有两种应用思路
思路2:基于RFM的汇总得分评估所有会员的价值度价值,并可以做价值度排名。同时,该得分还可以作为输入维度与其他维度一起作为其他数据分析和挖掘模型的输入变量,为分析建模提供基础。
案例背景介绍?
用户价值细分是了解用户价值度的重要途径,针对交易数据分析的常用模型是RFM模型
业务对RFM的结果要求
- 对用户做分组
- 将每个组的用户特征概括和总结出来,便于后续精细化运营不同的客户群体,且根据不同群体做定制化或差异性的营销和关怀
规划目标将RFM的3个维度分别做3个区间的离散化
- 用户群体最大有3×3×3=27个
- 划分区间过多则不利于用户群体的拆分
- 区间过少则可能导致每个特征上的用户区分不显著?
数据介绍?
案例数据是某企业从2015年到2018年共4年的用户订单抽样数据,数据来源于销售系统
数据在Excel中包含5个sheet,前4个sheet以年份为单位存储为单个sheet中,最后一张会员等级表为用户的等级表?
 ?读取数据
?读取数据

查看数据基本情况
 ?数据预处理
?数据预处理
 ?
?- 通过for循环配合enumerate方法,获得每个可迭代元素的索引和具体值
- 处理缺失值和异常值只针对订单数据,因此sheet_datas通过索引实现不包含最后一个对象(即会员等级表)
- 直接将each_data使用dropna丢弃缺失值后的dataframe代原来sheet_datas中的dataframe
- 使用each_data[each_data['订单金额']>1]来过滤出包含订单金额>1的记录数,然后替换原来sheet_datas中的dataframe
- 最后一行代码的目的是在每个年份的数据中新增一列max_year_date,通过each_data['提交日期'].max()获取一年中日期的最大值,这样方便后续针对每年的数据分别做RFM计算,而不是针对4年的数据统一做RFM计算。?
汇总所有数据?

汇总所有数据: 将4年的数据使用pd.concat方法合并为一个完整的dataframe data_merge,后续的所有计算都能基于同一个dataframe进行,而不用写循环代码段对每个年份的数据单独计算?
按会员ID做聚合?

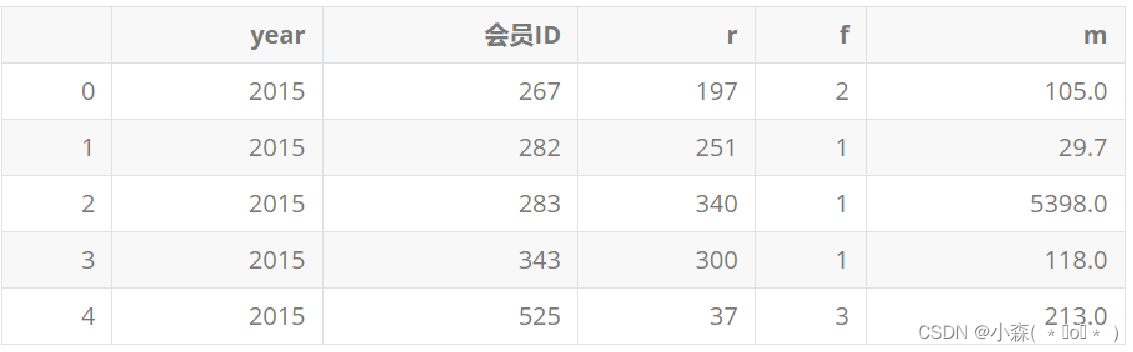 ?这里使用groupby分组,以year和会员ID为联合主键,设置as_index=False意味着year和会员ID不作为index列,而是普通的数据框结果列。后面的agg方法实际上是一个“批量”聚合功能的函数,它实现了对date_interval、提交日期、订单金额三列分别以min、count、sum做聚合计算的功能。否则,我们需要分别写3条goupby来实现3个聚合
?这里使用groupby分组,以year和会员ID为联合主键,设置as_index=False意味着year和会员ID不作为index列,而是普通的数据框结果列。后面的agg方法实际上是一个“批量”聚合功能的函数,它实现了对date_interval、提交日期、订单金额三列分别以min、count、sum做聚合计算的功能。否则,我们需要分别写3条goupby来实现3个聚合
确定RFM划分区间?
在做RFM划分时,基本逻辑是分别对R、F、M做离散化操作,然后再计算RFM。而离散化本身有多种方法可选,由于我们要对数据做RFM离散化,因此需要先看下数据的基本分布状态
 ?
?
区间分析?
从数据分布看出 汇总后的数据总共有14万条 r和m的数据分布相对较为离散,表现在min、25%、50%、75%和max的数据没有特别集中
而从f(购买频率)则可以看出,大部分用户的分布都趋近于1,表现是从min到75%的分段值都是1且mean(均值)才为1.365
计划选择25%和75%作为区间划分的2个边界值
 ?确定RFM划分区间
?确定RFM划分区间

f的分布情况说明
- r和m本身能较好地区分用户特征,而f则无法区分(大量的用户只有1个订单)
- 行业属性(家电)原因,1年购买1次比较普遍(其中包含新客户以及老客户在当年的第1次购买)
- 与业务部门沟通,划分时可以使用2和5来作为边界?
举例:[1,2,3,4,5],假如数据划分的区间边界是[1,3,5],即划分为2份?
其中的2/3被划分到(1,3]区间中
3/4/5被划分到(3,5]区间中?
1无法划分到任何一个正常区间内
RFM计算过程

- 每个rfm的过程使用了pd.cut方法,基于自定义的边界区间做划分
- labels用来显示每个离散化后的具体值。F和M的规则是值越大,等级越高
- 而R的规则是值越小,等级越高,因此labels的规则与F和M相反
- 在labels指定时需要注意,4个区间的结果是划分为3份
 ?将3列作为字符串组合为新的分组
?将3列作为字符串组合为新的分组
- 代码中,先针对3列使用astype方法将数值型转换为字符串型
- 然后使用pandas的字符串处理库str中的cat方法做字符串合并,该方法可以将右侧的数据合并到左侧
- 再连续使用两个str.cat方法得到总的R、F、M字符串组合
保存结果?
保存RFM结果到Excel
rfm_gb.to_excel('sales_rfm_score1.xlsx') # 保存数据为Excel
保存结果到Mysql ? ?(pip install pymysql)
 ?
?
RFM图形展示?
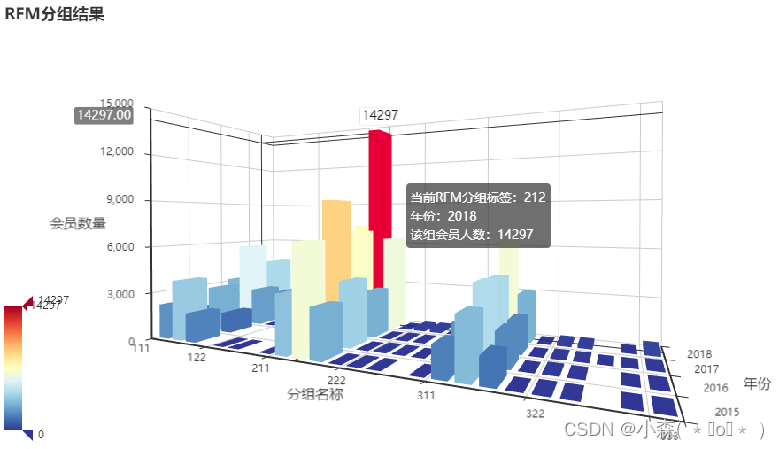
为了更好地了解不同周期下RFM分组人数的变化,通过3D柱形图展示结果
展示结果时只有3个维度,分别是年份、rfm分组和用户数量。

第1行代码使用数据框的groupby以rfm_group和year为联合对象,以会员ID会为计算维度做计数,得到每个RFM分组、年份下的会员数量
第2行代码对结果列重命名
第3行代码将rfm分组列转换为int32形式?

输出3D图像中
- X轴为RFM分组、Y轴为年份、Z轴为用户数量
- 该3D图可旋转、缩放,以便查看不同细节?
- 左侧滑块,用来显示或不显示特定数量的分组结果
 ?分别针3类群体,按照公司实际运营需求和当前目标,制定了不同的群体落地的排期
?分别针3类群体,按照公司实际运营需求和当前目标,制定了不同的群体落地的排期
- RFM模型是经典的一种用户分群方法,操作起来比较简单,如果数据量不是很大的时候,直接使用Excel就可以实现
- RFM并不是在所有业务场景下都可以使用,一般用于零售行业(复购率相对高的行业)
- 使用Python的cut方法对数据进行分组,需要注意分组区间默认是左开右闭
- 使用Pyecharts可以方便的绘制出可以交互的3D图,在修改弹出提示信息内容时,需要注意字符串拼接的格式?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JS数据类型(undefined、null、boolean、number、bigInt、string、symbol、object,8种)
- 前端算法总结
- java:用ClassLoader将文件转化为输入流
- SpringBoot整合MyBatis
- 喜报,思迈特荣获广东省“专精特新”企业认定,再创新高
- GESP认证第四次考试百分榜考生名单及学校
- 【UEFI基础】EDK网络框架(通用函数和数据)
- HttpServletRequest setHeader
- 盘活存量GPU资源 破局高校算力不足窘境
- ATFX期市:安哥拉宣布退出OPEC,减产计划还能否彻底执行?