算法学习系列(十八):字符串哈希
发布时间:2023年12月31日
引言
这个字符串哈希还是比较厉害的啊,只要是有关字符串的题目,这个字符串哈希都是可以轻松水过,所以说这个还是得好好掌握啊,话不多说,直接开始。
一、字符串哈希概念
- 这个字符串哈希就是将一个字符串转换为一个p进制的数,然后将这个p进制的数转换为十进制 mod Q,然后就可以比较这个数,来判断这两个字符串是否相等。
这个p一般取131或者13331,Q一般取2^64,在这种情况下,一般99.99%都不会发生哈希冲突 - 给定一段字符串,并且给定一定L和R,如何判断这两个字符串是相等的?
根本就是根据每个字符的ASCLL码把一个字符串看成一个P进制的数,然后算出这个数对应的十进制来定义一个字符串。
然后需要求从L到R的字符串哈希值,来判断这两个哈希值是否等价,当然这个一般来说都不会冲突的
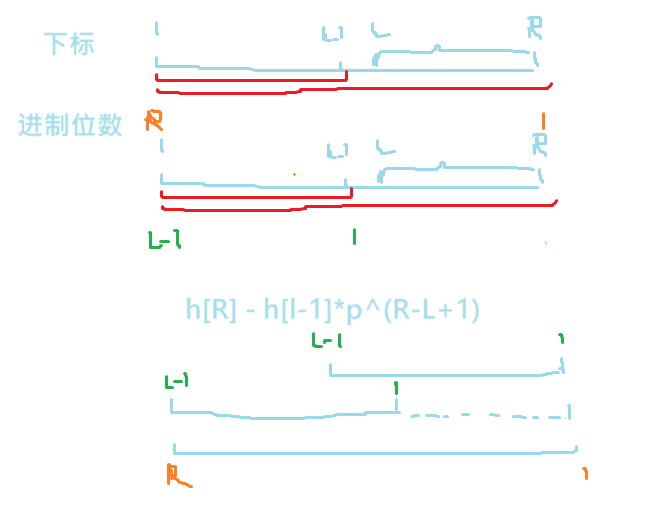
然后就是一个p进制的数,如下图所示,我们要求L~R的哈希值,然后进制位数所对应得下标如下,我们要求那一段,那就让h[L-1]那一段值左移到跟h[R]对其,那么其余的L ~ R那一段就都为0了,再用h[R]一减就可以求出来了。
有个问题就是进制数不能从0开始,因为A和AA这两个字符串对应的P进制数所对应的十进制都是0,所以是不可以的,然后需要 mod 2^64,可以用unsigned long long来存,这样溢出就相当于 mod 了
二、代码实现
这个还是要拿题目看
给定一个长度为 n 的字符串,再给定 m 个询问,每个询问包含四个整数 l1,r1,l2,r2,请你判断 [l1,r1] 和 [l2,r2] 这两个区间所包含的
字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数 n 和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n 的字符串,字符串中只包含大小写英文字母和数字。
接下来 m 行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从 1 开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
int n, m;
ULL h[N], p[N];
char str[N];
ULL get(int l, int r)
{
return h[r] - h[l-1] * p[r - l + 1];
}
int main()
{
scanf("%d%d%s", &n, &m, str + 1);
p[0] = 1;
for(int i = 1; i <= n; ++i)
{
p[i] = p[i-1] * P;
h[i] = h[i-1] * P + str[i];
}
while(m--)
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
if(get(l1,r1) == get(l2,r2)) puts("Yes");
else puts("No");
}
return 0;
}
文章来源:https://blog.csdn.net/weixin_60033897/article/details/135317415
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 浅谈情绪的分类合集
- 学习笔记-李沐动手学深度学习(一)(01-07)
- 免费使用Chatgpt4.0
- Isaac Sim urdf文件导入
- 03.SpringCloud服务间远程调用
- 【LeetCode:76. 最小覆盖子串 | 滑动窗口】
- 铁威马使用小贴士,让NAS实现存储的旷野
- DevC++ easyx实现视口编辑--像素绘图板与贴图系统
- Mybatis实现增删改查的两种方式-配置文件/注解
- 用了国产接口管理神器 Apifox 之后,我果断从 Postman “脱坑”了