使用python快速开发与PDF文档对话的Gemini聊天机器人

检索增强生成(Retrieval-augmented generation,RAG)使得我们可以让大型语言模型(LLMs)访问外部知识库数据(如pdf,word、text等),从而让人们可以更加方便的通过LLM来学习外部数据的知识。今天我们将利用之前学习到的RAG方法,谷歌Gemini模型和langchain框架来快速开发一个能够和pdf文件对话的机器人,之所以要选择Gemini模型是因为它的API目前是免费调用的,而OpenAI的API则是要收费的,而我没有那么多银子,所以只能选择免费的。
一、什么是检索增强生成 (Retrieval-augmented generation,RAG)?
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。 它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如 大型语言模型 (LLM) ,此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。一个基本的RAG检索过程主要包含以下这些步骤:
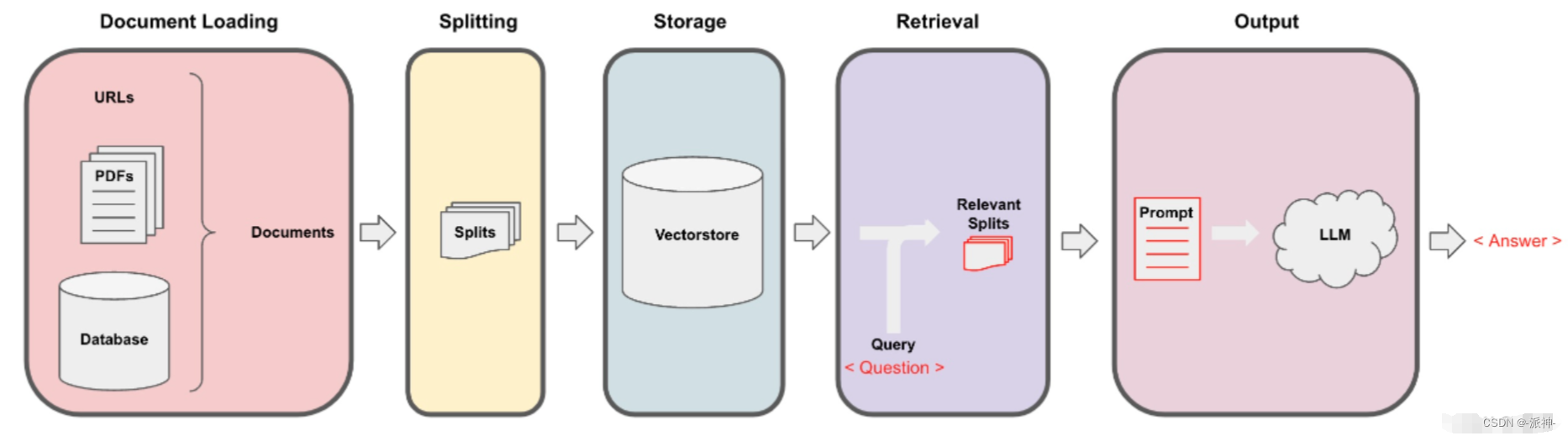
一个典型的RAG系统一般包含两个主要的部件:
- 检索器组件:根据用户问题从外部数据源(如pdf,word,text等)检索相关信息并提供给LLM 以便回答用户问题。
- 生成器组件:LLM根据检索到的相关信息,生成正确的、完整的对用户友好的答案。
我之前写过一系列的关于使用langchain与文档对话的博客,如果想详细了解RAG的基本过程可以先看一下我写的这些博客。
在本次的与PDF文档对话的系统中我们使用的检索器组件是基于Langchain框架的父文档检索器,如果对它还不熟悉朋友可以先看一下我之前写的父文档检索器这篇博客,至于生成器组件,我们使用的是基于谷歌的Gemini大模型。对于如何开发一个基于web页面的聊天机器人程序还不熟悉的朋友可以查看我之前写的使用python快速开发各种聊天机器人应用这篇博客,以便可以快速上手开发机器人应用程序。对谷歌gemini模型还不熟悉的朋友可以查看我之前写的谷歌Gemini API 应用(一):基础应用这篇博客,以便可以快速了解Gemini API的使用方法。
在本文的最后我会给大家分享完整的代码,大家可以在此基础上不断的完善代码开发出符合你们自己需求的机器人。
一,环境配置
这里我们主要使用的是panel和langchain这两个python包:
pip install google-generativeai
pip install panel
pip install langchain
pip install chroma如果在安装过程中报错,请根据报错信息安装其他必要的python包。
二、组件介绍
这里我们会使用谷歌Gemini模型组件,以及基于langchain的检索器组件,其中包括:文档分割器组件、父文档检索器组件、向量数据库组件、另外我们还需要使用python的web框架组件panel等。下面我们导入这些组件的python包:
import tempfile
import panel as pn
import param
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from panel_chat_examples import EnvironmentWidgetBase
import google.generativeai as genai这里需要说明的是我们使用的LLM是谷歌原生的Gemini模型组件,而非由langchain非封装的gemini组件,之所以使用谷歌原生组件是因为我发现langchain的gemini组件存在一些bug, 它不能设置谷歌模型的安全策略,导致机器人在回答问题的时候经常会报用户问题存在安全性问题的异常,这可能是由于目前这个langchain的gemini组件还是早期版本,估计后面会完善这些问题。
三、功能模块介绍
31. Embedding模型的选择
如果对Embedding模型还不太熟悉的朋友可以查看我之前写的Embedding模型的选择这篇博客,因为本次实验使用的是中文内容的文档,所以我还是选择了BAAI的"bge-small-zh-v1.5", 如果大家使用的是英文的pdf文档则可以将Embedding模型切换为了BAAI的"bge-small-en-v1.5":
#支持中文的BAAI embedding模型
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5",
cache_folder="D:\\models")这里的cache_folder指的是存放Embedding模型的文件夹,当首次执行机器人程序的时候系统会自动从HuggingFace的网站下载Embedding模型并将它存放到默认的cache_folder文件夹下(C盘),所以这里我们可以指定cache_folder文件夹的路径把Embedding模型存储在C盘以外的地方。
3.2 Gemini模型的安全策略
Gemini模型在回答用户问题的时候有一套严格的关于内容的安全审查机制,以防止出现违反道德伦理,色情暴力等内容。由于本次实验我使用的PDF文档是:"阿凡提故事大全.pdf"它是一个中文文档,当机器人在回答问题的时候不知为何经常出现内容违规的提示,这可能是由于gemini模型的默认安全审查策略的阈值设置的太高引起的,因此当我把安全审查策略的阈值调到"无"以后就不再出现违规提示了:
generation_config = {
"temperature": 0.0,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
]这里我们设置了模型参数generation_config 和安全策略参数safety_settings ,在模型参数中我们设置了temperature为0,该参数的取值范围为0-1,参数值越低,llm给出的答案越精准,参数值越高给出的答案变化性越大,因此为了让llm不要产生多样化的结果,我们应尽量调低temperature的值,设置为0或0.1都可以。另外我们将所有安全策略的阈值都设置为"BLOCK_NONE"即不做安全性审查。
3.3父文档检索器
如果对langchain的父文档检索器策略还不熟悉的朋友可以先看一下我之前写的父文档检索器这篇博客,下面是我们在panel中定义父文档检索器的一些组件:
#加载文档
@pn.cache(ttl=TTL)
def _get_docs(pdf):
# load documents
with tempfile.NamedTemporaryFile("wb", delete=False) as f:
f.write(pdf)
file_name = f.name
loader = PyPDFLoader(file_name)
docs = loader.load()
return docs
#创建父文档切割器
@pn.cache(ttl=TTL)
def _get_parent_splitter():
return RecursiveCharacterTextSplitter(chunk_size=1000)
#创建子文档切割器
@pn.cache(ttl=TTL)
def _get_child_splitter():
return RecursiveCharacterTextSplitter(chunk_size=400)
#创建内存存储组件
@pn.cache(ttl=TTL)
def _get_MemoryStore():
return InMemoryStore()
#创建向量数据库
@pn.cache(ttl=TTL)
def _get_vector_db():
vectorstore = Chroma(collection_name="split_parents",
embedding_function = bge_embeddings)
return vectorstore
#创建父文档检索器
@pn.cache(ttl=TTL)
def _get_retriever(pdf, number_of_chunks: int):
docs=_get_docs(pdf)
vectorstore= _get_vector_db()
store=_get_MemoryStore()
child_splitter=_get_child_splitter()
parent_splitter=_get_parent_splitter()
#创建父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
search_kwargs={"k": number_of_chunks}
)
#添加文档集
retriever.add_documents(docs)
return retriever3.4创建gemini模型对象
下面是在panel中定义gemini模型对象和模型生成内容的方法:
#创建gemini模型对象
@pn.cache(ttl=TTL)
def _get_model():
#创建gemini model
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)
return model
def _get_response(contents):
retriever=_get_retriever(state.pdf, state.number_of_chunks)
model=_get_model()
relevant_docs=retriever.get_relevant_documents(contents)
contexts='\n\n'.join([w.page_content for w in relevant_docs])
#prompt模板
template = f"""请根据下面给出的上下文来回答下面的问题,并给出完整的答案:
上下文:{contexts}
问题: {contents}
"""
response = model.generate_content(template)
chunks = []
for chunk in relevant_docs:
name = f"Chunk {chunk.metadata['page']}"
content = chunk.page_content
chunks.insert(0, (name, content))
return response.text, chunks3.5创建panel页面组件
这里我们还需要创建panel的页面组件和设置环境变量等全局变量以便设置谷歌的api_key和callback函数,这里我们我们仍然使用的是panel的chat_interface作为我们的页面聊天组件,对应panel还不熟悉的朋友可以查看我之前写的使用python快速开发各种聊天机器人应用以及panel的官方文档:
# 定义应用程序全局变量
class EnvironmentWidget(EnvironmentWidgetBase):
GOOGLE_API_KEY: str = param.String()
class State(param.Parameterized):
pdf: bytes = param.Bytes()
number_of_chunks: int = param.Integer(default=2, bounds=(1, 5), step=1)
environ = EnvironmentWidget()
state = State()
# 定义页面组件
pdf_input = pn.widgets.FileInput.from_param(state.param.pdf, accept=".pdf", height=50)
text_input = pn.widgets.TextInput(placeholder="First, upload a PDF!")
# 定义和配置 panel ChatInterface
def _get_validation_message():
pdf = state.pdf
google_api_key = environ.GOOGLE_API_KEY
if not pdf and not google_api_key:
return "请在左侧侧边栏中输入谷歌api key 然后上传PDF文件!"
if not pdf:
return "请先上传pdf 文件"
if not google_api_key:
return "请先输入谷歌api key"
genai.configure(api_key=google_api_key,transport='rest')
return ""
def _send_not_ready_message(chat_interface) -> bool:
message = _get_validation_message()
if message:
chat_interface.send({"user": "System", "object": message}, respond=False)
return bool(message)
async def respond(contents, user, chat_interface):
if _send_not_ready_message(chat_interface):
return
if chat_interface.active == 0:
chat_interface.active = 1
chat_interface.active_widget.placeholder = "在这里输入您的问题!"
yield {"user": "Gemini", "object": "现在可以开始和pdf对话了!"}
return
response, documents = _get_response(contents)
pages_layout = pn.Accordion(*documents, sizing_mode="stretch_width", max_width=800)
answers = pn.Column(response, pages_layout)
yield {"user": "Gemini", "object": answers}
chat_interface = pn.chat.ChatInterface(
callback=respond,
sizing_mode="stretch_width",
widgets=[pdf_input, text_input],
disabled=True,
)
@pn.depends(state.param.pdf, environ.param.GOOGLE_API_KEY, watch=True)
def _enable_chat_interface(pdf, google_api_key):
if pdf and google_api_key:
chat_interface.disabled = False
else:
chat_interface.disabled = True
_send_not_ready_message(chat_interface)
## Wrap the app in a nice template
template = pn.template.BootstrapTemplate(
title="PDF文档对话机器人",
sidebar=[
environ,
state.param.number_of_chunks
],
main=[chat_interface],
)
template.servable()四、机器人使用方法介绍
我们需要在命令行窗口中执行机器人的源代码程序:
panel serve gemini_pdf_bot.py
在浏览器中打开访问机器人的链接:
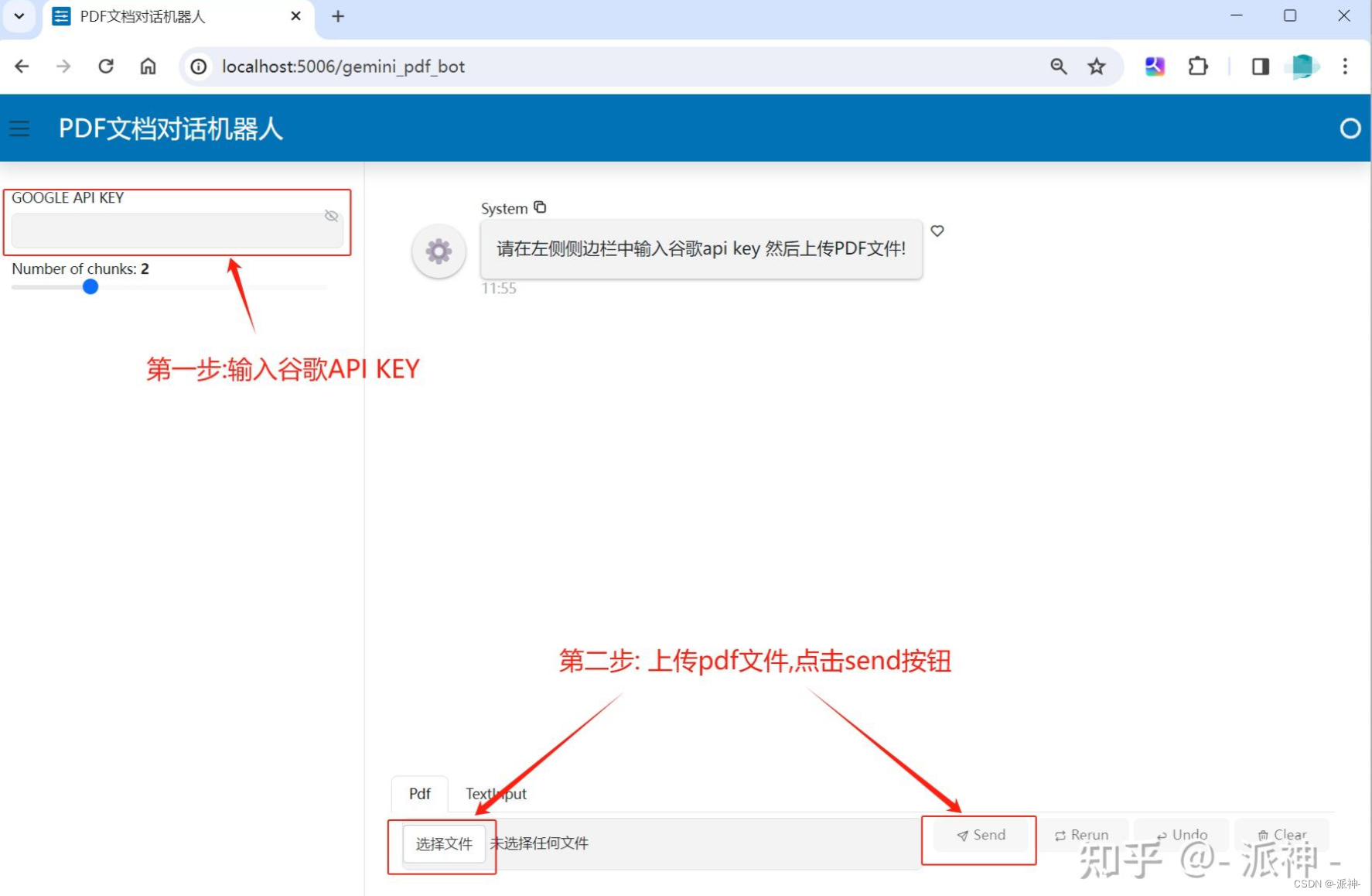
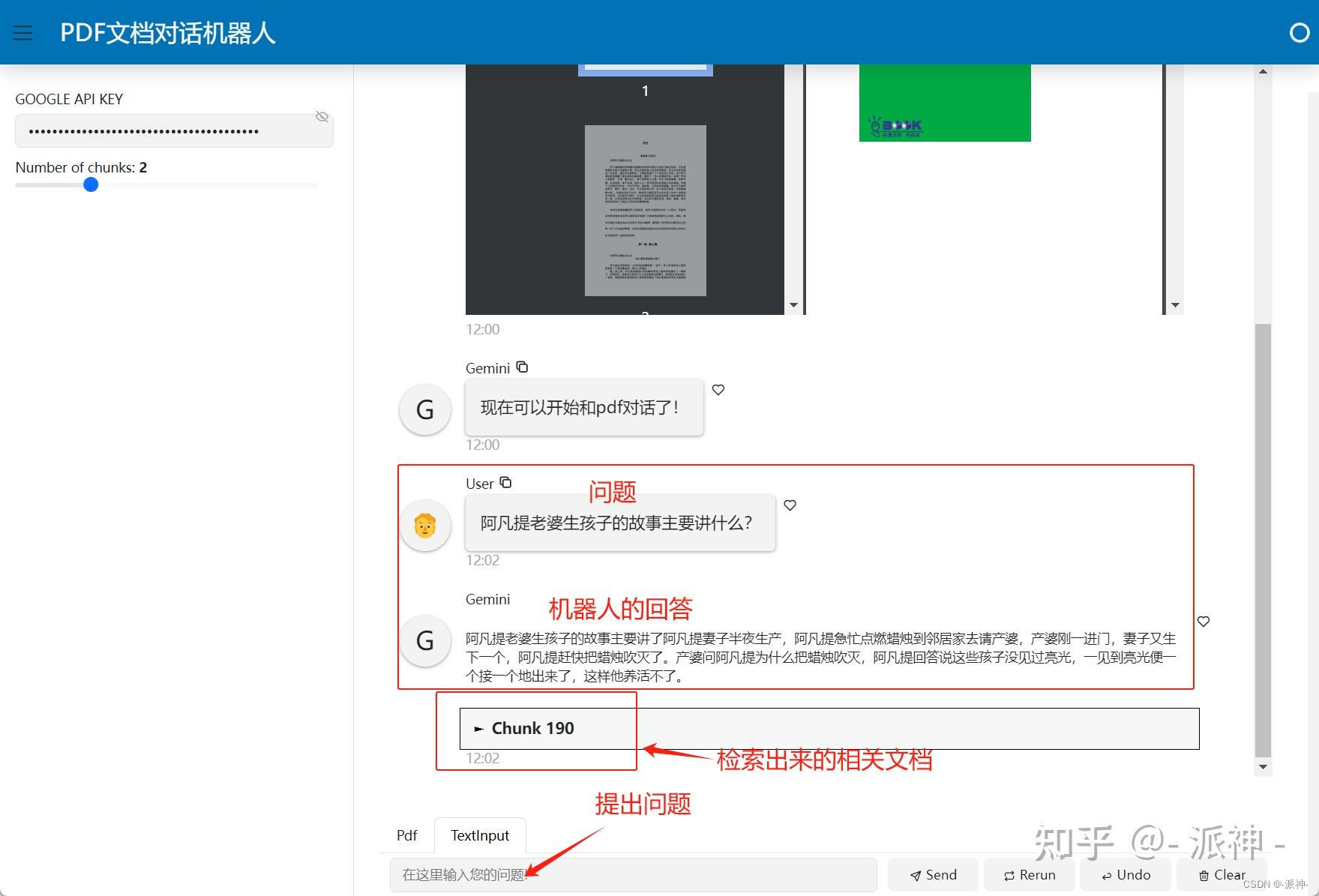
完成输入谷歌api key和上传pdf文件以后,就可以开始和机器人聊天了:
五、总结
今天我们主要介绍了如何开发一个简单的RAG系统:基于pdf文档问答的机器人应用,其中我们应用了langchain的父文档检索策略,panel的页面聊天组件chat_interface以及谷歌的Gemini大模型。希望今天的内容对大家学习RAG和聊天机器人程序有所帮助。
六、完整代码
链接:https://pan.baidu.com/s/1w6MzGDflLF7N3-NlENKj8w?提取码:tllt
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux-iptables,Centeros 防火墙
- Unity连接蓝牙设备的其中一种方法(不一定通用,但思路也许可以)
- 微信小程序怎样给事件传值的
- Github 2023-12-23 开源项目日报 Top10
- 产品更新 | 如何利用思码逸DevInsight度量代码评审效率、质量与瓶颈?
- vue创建项目
- 学习总结——1.23
- 万兆网络之网线鉴别
- 服务器配置 ssh 密钥登录
- 日志审计、数据库审计以及代码审计三者的区别与重要性