如何将LLMs封装成应用并在本地运行
最近我一直在致力于Ollama的工作,因此我花了很多时间思考如何在本地系统上运行大型语言模型(LLMs)以及如何将它们打包成应用程序。对于使用LLMs的大多数桌面应用程序而言,通常的体验要么是插入OpenAI API密钥,要么是从源代码构建一个Python项目。这些方法可以作为概念验证,但它们需要一些基础知识,而许多用户可能不具备。我追求的体验是一个只需单击即可下载并直接运行的应用程序。计划
- 一键下载并运行。
- 无外部依赖。
- 应用程序文件尺寸最小化。
- 简单的LLM版本控制和分发系统。
- 为所有主要操作系统构建和发布。
- 充分利用本地运行,使本地文件系统可用。
- 用户不暴露任何设置。LLM应该在用户系统上以最佳性能运行,无需干预。
- 内置电池,但可替换。对于高级用户,他们应该能够使用高级配置自定义驱动应用程序的LLM。
考虑到所有这些因素,我决定开发一个名为“chatd”的桌面应用程序,允许用户与其文档进行聊天。这是一个常见的LLM应用场景,但我认为目前对于非技术终端用户而言,尚未有一个简单而出色的选择。它还充分利用了应用程序轻松访问文件系统的特点。架构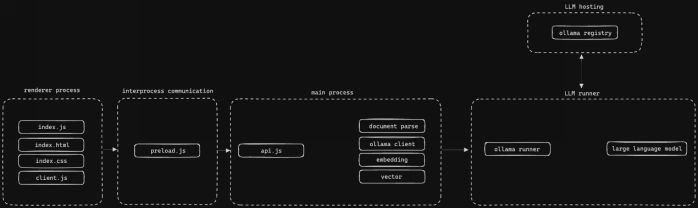 该项目可以分为四个明确定义的部分:渲染、进程间通信、主进程和LLM运行器。
该项目可以分为四个明确定义的部分:渲染、进程间通信、主进程和LLM运行器。
渲染和进程间通信
渲染部分使用典型的HTML、CSS和JavaScript完成。当用户执行需要处理的操作时,通过进程间通信将其发送到主进程。这使得可以执行代码,并访问实际的主机系统。
主进程
包括一些自定义文档处理(附注:请有人为通用文档处理用例创建一个标准的JavaScript库),然后将提取的数据输入到transformers.js中。transformers.js库是由Hugging Face维护的一个项目,允许您在浏览器中使用ONNX运行时运行模型。这可以非常快速。最后,我将向量存储在内存中,因为目前尚无符合我的需求的内存向量数据库。
LLM运行器
在处理了所有这些信息后,我使用Ollama作为打包和分发将驱动交互的LLM的方式。目前,大多数用户将Ollama作为独立的应用程序运行,并向其发送查询,但也可以直接将其打包到桌面应用程序中并进行编排。我为每个操作系统的相应软件包添加了Ollama可执行文件,并编写了一些JavaScript代码来编排可执行文件的使用。
这非常方便,因为我不仅能够利用Ollama作为可靠的系统来运行LLM,还能为在Electron软件包之外分发LLM提供便利的系统。将LLM添加到Electron应用程序包本身意味着需要进行大规模的初始下载(超过4GB),并将用户锁定为仅使用我在chatd中发布的模型。此外,使用Ollama的分发系统,我还可以在不发布新应用程序的情况下更新或修改模型。我可以进行更改,将模型推送到ollama.ai注册表,用户将在下次启动应用程序时获得更新。利用Ollama还使用户体验保持简单,同时仍然允许高级用户根据需要更换驱动应用程序的模型。早期采用本地LLM的用户(以及我与之互动的Ollama用户)对事物的工作方式感兴趣,并希望使用最新的模型保持领先地位。尽管Ollama被打包到chatd中,但它可以检测到Ollama是否已在运行。在这种情况下,它会向用户显示额外的设置,让他们根据需要配置chatd并更换模型。这还意味着用户无需重新下载已经存在的模型。
结果
我向一些不属于典型ChatGPT用户群体的朋友展示了chatd,他们的反响非常积极。在他们的计算机上看到AI简单而本地地运行是让他们惊叹不已的,他们迅速看到了让这个本地聊天机器人访问其文件的潜力。我期待着改进这一体验,希望我们能看到一批新的桌面应用程序使LLMs变得更加易用。Chatd项目地址:https://www.chatd.ai/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- etcd跨主机通信与Flannel
- 使用Kali Linux端口扫描
- Synchronized、ReentrantLock 和 ReadWriteLock底层原理
- 服务器数据恢复-raid5故障导致上层分区无法访问的数据恢复案例
- 使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解
- Python调用Shell命令 (python, shell 混合编程)
- git运用之.gitignore 配置文件的常用写法及案例
- 西南科技大学计算机网络实验二 (IP协议分析与以太网协议分析)
- [Firefly-Linux] RK3568在Ubuntu上安装内核头文件实现本地编译驱动程序
- 【··案例··】【19.某易云音乐】请求逆向解析,数据算法解密(详细笔记)